Overcoming complexity: the biggest new dbt Cloud features from Coalesce 2023

Last edited on May 28, 2025
Today we kicked off dbt Labs’ annual conference, Coalesce 2023. It’s the highlight of our year, and it’s also been an unveiling ceremony for dbt Cloud announcements.
At the opening keynote, we announced a number of major new dbt Cloud features that solve some of the biggest problems we’ve heard from customers over the last year. We couldn’t be more thrilled to share these updates with the world.
These new features are geared to help our customers solve problems of complexity. As organizations—and organizational data—grow in complexity, it becomes increasingly difficult for data teams to remain agile, maintain quality and consistency across a wide assortment of data products, and keep spend under control.
This is how dbt Cloud is evolving to help you solve those problems.
More Data, More Problems
As organizations adopt dbt, their projects tend to naturally grow in size: data needs evolve, and it becomes helpful to incorporate business logic across more domains. Tristan highlighted earlier this year that a significant and growing proportion of all dbt projects now contain thousands of models.
To date, working with these large projects in dbt hasn’t been a great experience. They take more time to parse. Their lineage is hard to render, let alone reason about. It’s challenging for developers to find the right places to contribute and to ensure they aren’t accidentally causing breaking changes downstream. Central data teams get stretched thin trying to maintain order—and inevitably bottleneck other teams in the process.
Problems of complexity aren’t unique to dbt. Software teams, and indeed data teams, have been iterating on solutions to the same challenges for some time.
An increasingly large number of data teams have landed on data mesh architectures: a central team that maintains infrastructure and sets standards, along with domain teams that build on top of that platform, remaining in control of their own data.
The idea is simple: break down the whole into smaller pieces, empower smaller teams to operate autonomously, and develop interfaces between them so they can collaborate effectively.
dbt Mesh: Domain-level ownership, without compromising governance
Today we launched an easy-to-use way to reference models across projects in dbt Cloud. This allows you to implement a multi-project dbt architecture—a pattern we’re calling dbt Mesh.
Rather than relying on a single, monolithic project that is easily bottlenecked, domain teams can now own their own dbt projects. These projects seamlessly build on each other, with interfaces between them governed by contracts, versions, and access controls that are baked directly into dbt.
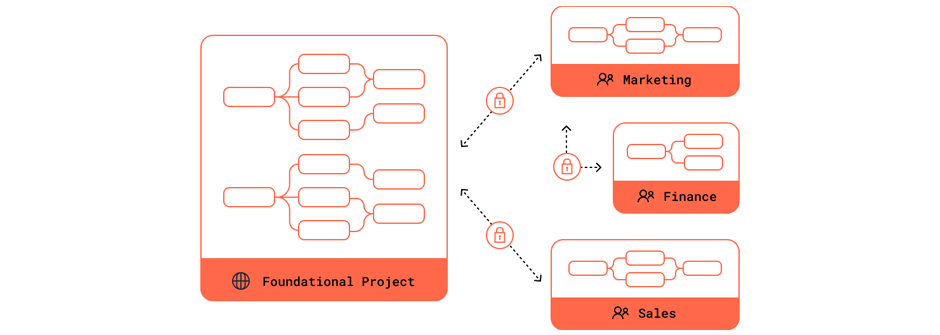
This puts domain teams in control of their own data pipelines (within reasonable guardrails), requiring them to reason about only the parts of the dbt lineage that are directly relevant to their work. They can easily reference shared dbt models from other teams, bolstered by the confidence that nothing will break unexpectedly for them or for their downstream consumers.
Meanwhile, a central data team can still set global standards for governance, and maintain visibility on end-to-end dbt lineage.
“dbt Mesh enables us to make data mesh a reality by offering a simple, cohesive way to integrate and manage data pipelines and products across the enterprise using a single platform."
– Marc Johnson, Data Strategy & Architecture, Fifth Third Bank
dbt Mesh isn’t a single feature. It’s an architecture involving multiple dbt projects, each aligned to a business domain, interfacing with and building off of each other. It’s a way for you to control the complexity of your data environment to unlock better collaboration at scale.
This paradigm shift towards an architectural mesh ushers in a whole new host of ways of working in dbt Cloud, which lays the groundwork for many of our other dbt Cloud announcements.
The ability to reference across projects is available now in Public Preview. Have a look through our newly published dbt Mesh developer guide to dive deeper and get started.
dbt Explorer: A 360-degree view of your dbt assets
dbt Explorer is dbt Cloud’s new knowledge base and lineage visualization experience. It lets you quickly understand your dbt deployment, helping you identify available resources to use for development or analysis.
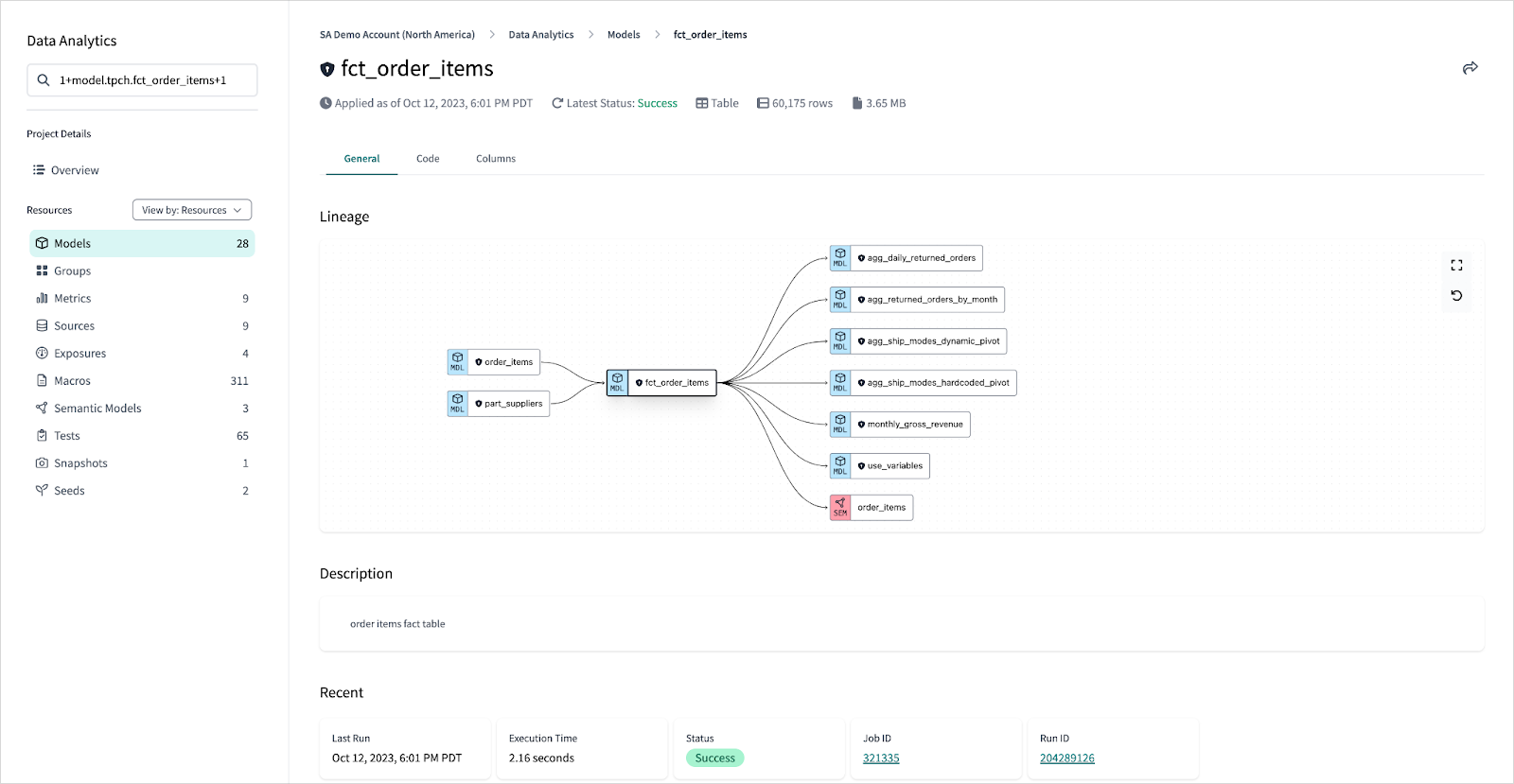
dbt Explorer provides documentation enriched after each dbt Cloud run, using the Discovery API as its source of truth for production metadata. With dbt Explorer as your launchpad, it’s easier than ever to share context, troubleshoot issues, and reuse assets across different parts of the organization—significantly reducing friction in the data development workflow, and allowing you to better control data platform spend at the same time.
"Given the size and complexity of Sunrun's dbt infrastructure, dbt Explorer is an ideal tool to provide our data engineers and analysts with quick, detailed visibility into all aspects of our environment."
– Gavin Mackinlay, Senior Data Engineer, Sunrun
dbt users have long relied on dbt Docs to automatically build data documentation alongside their code. It’s been incredibly helpful in aligning data teams, but dbt Docs simply wasn’t built for the kind of scale we’re now seeing at our larger customers. Unlike Docs, dbt Explorer is performant even for massive dbt deployments, and updates live after each run.
Importantly, dbt Explorer also natively supports multi-project lineage, making it an essential tool for organizations adopting a dbt Mesh architecture. It is the hub that provides the central visibility essential for distributed collaboration at scale.
dbt Explorer is available today in Public Preview for dbt Cloud Team and Enterprise plan customers. To get started, simply set a production environment and click the “Explore” tab in the top navigation bar.
dbt Semantic Layer: Generally Available, with new Tableau and Google Sheets integrations
As businesses grow in complexity, it becomes increasingly difficult to maintain consistent definitions of business concepts such as “customer” or “revenue” across various teams and analytics tools. The dbt Semantic Layer tackles this by allowing teams to define metrics once, centrally, and access them from any integrated analytics tool, ensuring consistent answers everywhere, every time.
Since dbt Labs’ acquisition of Transform earlier this year, we’ve made rapid progress incorporating MetricFlow under the hood, and we’re pleased to announce today that the dbt Semantic Layer is now Generally Available.
We’re also launching two of our most commonly requested integrations: Tableau and Google Sheets. These accompany integrations with Hex, Klipfolio, Lightdash, Mode, and Push.ai. See all available Semantic Layer integrations and get started here.

The new version of the dbt Semantic Layer is powered by MetricFlow under the hood, which enables more complex metric definition and querying to be done efficiently at scale, with capabilities such as:
- Dynamic join support. dbt can now infer the appropriate traversal paths between multiple tables using entities when generating a metric, making all valid dimensions available for your metrics on the fly.
- Expanded data platform support. The dbt Semantic Layer now supports BigQuery, Databricks, Redshift, and Snowflake. This includes performance optimizations for each data platform.
- Optimized query plans and SQL generation. With a focus on producing legible and performant SQL, the new Semantic Layer generates joins, filters, and aggregations just as an analyst would—without the need for complicated tricks that yield illegible SQL, such as symmetric aggregates.
- Semantic Layer APIs. We’ve also built new APIs, including an entirely rebuilt SQL interface built with ArrowFlight (ADBC/JDBC), as well as a GraphQL API allowing for more seamless integrations.
- More complex metric types out of the box. Enabling new aggregations and more flexible metric definitions means you can define more of the metrics that are critical to measuring your business.
The dbt Semantic Layer is now available to multi-tenant customers in all deployment regions. Customers on dbt Cloud Team and Enterprise plans can get started today on a trial basis, after which additional consumption units can be purchased. Talk to your dbt Labs account representative to learn more.
Develop anywhere with dbt Cloud
Whether you’re more comfortable developing in an in-browser IDE or using a CLI, you can now do so backed by dbt Cloud. Today we launched the dbt Cloud CLI, giving you the flexibility to develop using any IDE or terminal of your choice (such as VS Code, Sublime Text, or Vim). You’ll get to enjoy the familiarity of your own customizable development tooling, with all the power of dbt Cloud as the backend—and without all the hassles of manual configuration and authentication.
Using the Cloud CLI also makes your deployment easier to govern by allowing for dbt versioning to be managed centrally. That means you can significantly minimize the hassle of coordinating version upgrades.
Get started with the dbt Cloud CLI today—it’s available now in Public Preview.
Of course, developers that prefer to use the more accessible in-browser dbt Cloud IDE can do so knowing that we continue to invest in it. The dbt Cloud IDE now works with popular linters and formatters like SQLFluff, sqlfmt, Black, and Prettier, helping increase code quality and consistency across your projects. On top of that, you can now enjoy more intelligent context-aware compilation, along with further improved interaction and cold start time, building off an all-new backend.
But that’s not all. Whether you’re using the dbt Cloud CLI or the Cloud IDE, we’ve made the experience of developing on dbt Cloud more streamlined in other ways too. You can now:
- Defer to production. Instead of needing to build every upstream model before you can start developing, deferral lets you point your dev environment to models already in production—allowing you to shorten your development feedback loop and reduce data platform consumption.
- Say farewell to
dbt deps. dbt Cloud is internalizing dependency management, so there’s no need to manually rundbt depson initial clone of a new repo as of dbt v1.6—and soon, you'll never need to run it again, period.
Better, smarter CI/CD out of the box
The ability to promote development work to production quickly, without risk of breaking pipelines, is critical for data teams. Built-in continuous integration (CI) and continuous deployment (CD) capabilities in dbt Cloud help you do just that.
dbt Cloud’s CI/CD capabilities are now significantly enhanced, allowing you to more easily deploy with confidence—while keeping costs in check.
Here are some of the highlights:
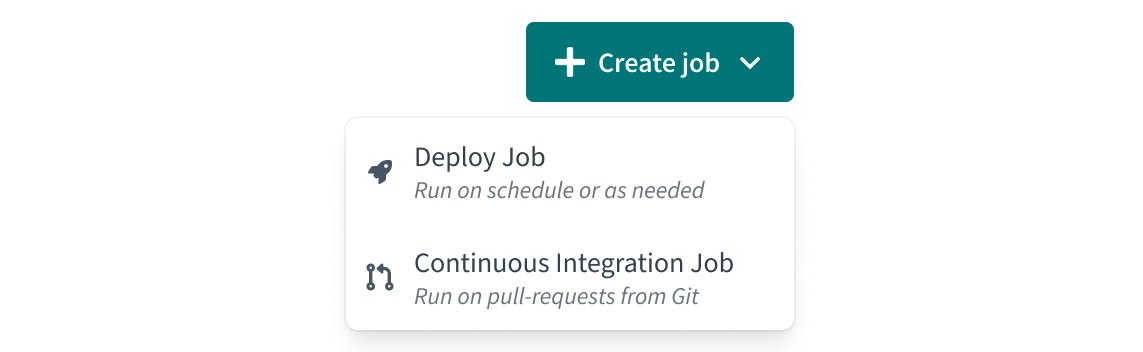
- Introducing dedicated CI jobs. You can now simply choose “Continuous Integration” as a job type, making CI jobs easier to get started—with best practice configurations pre-applied.
- Defer to an environment instead of a job. Never waste a build or test on code that hasn’t been changed. dbt Cloud can now diff between the PR and what’s running in production, allowing you to save valuable compute resources.
- Auto-cancellation of stale, in-flight CI jobs. dbt Cloud can detect and cancel any in-flight, now-stale checks in favor of executing tests on the newest code commit to a PR.
- CI runs never block production runs. CI jobs will no longer consume a run slot, and thus cannot prevent a production job from running on schedule.
- Rerun from point of failure. We’ve incorporated the new retry command so you can re-execute the last dbt job from the node point of failure, allowing you to avoid re-executing the entire job when it’s not necessary.
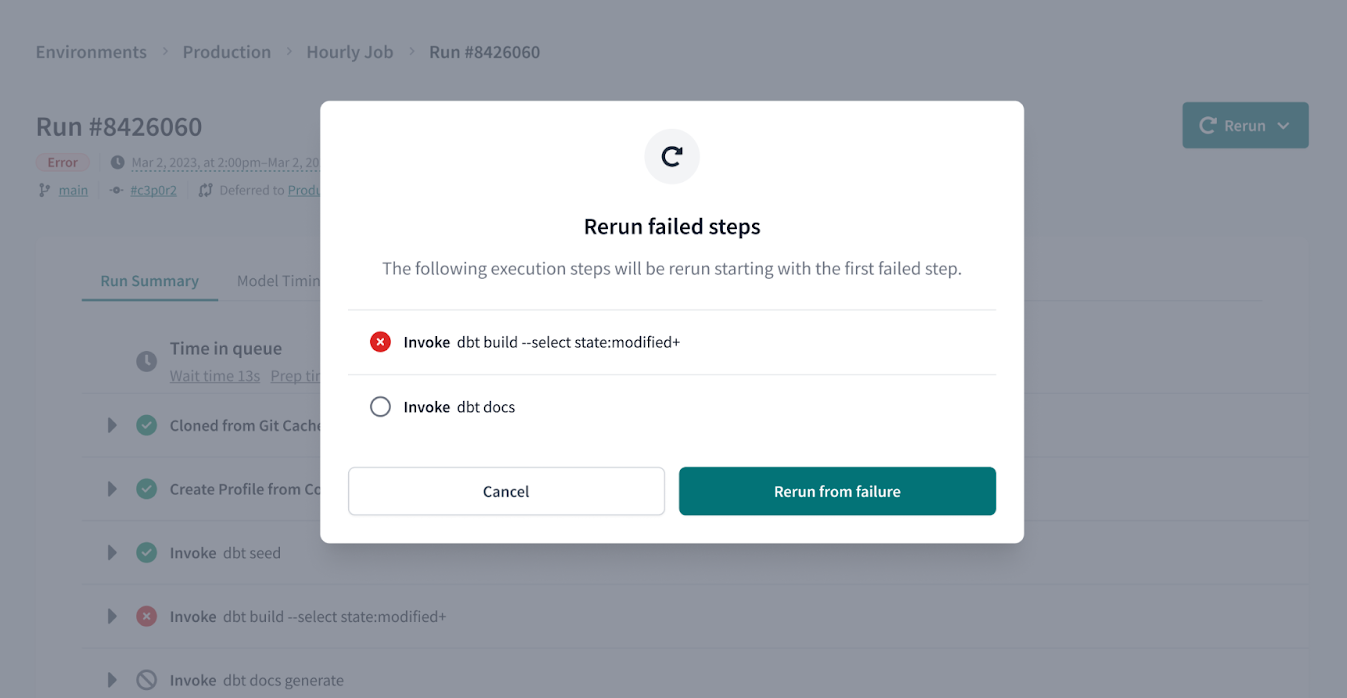
In addition, dbt Cloud now does a better job of dropping temporary schemas after your CI job has run, and updates CI job status more quickly, allowing you to stay in flow as testing happens.
These changes are Generally Available to all dbt Cloud users today.
Support for Microsoft adapters in dbt Cloud
We’re excited to share that the dbt Cloud ecosystem continues to grow. Today we also announced upcoming support for Microsoft Fabric and Azure Synapse adapters in dbt Cloud. Adding Microsoft to our ecosystem builds on the already deep integrations we have with popular data platforms including BigQuery, Databricks, Redshift, Snowflake, and Starburst as we partner to support our joint customers’ expanding use cases.
The Microsoft Fabric adapter is currently in Private Preview, while the Azure Synapse adapter will launch soon. Keep an eye out on this space for more updates!
Toward better-managed chaos
From the introduction of the dbt Mesh architecture to the launch of dbt Explorer and improvements in the Semantic Layer, organizations are now able to collaborate better in the face of organizational complexity than ever before. New tools like the dbt Cloud CLI and enhanced CI/CD have further enhanced the developer experience—while making it possible to better optimize data platform costs. And with the addition of Microsoft adapters, we're broadening our ecosystem to better meet the needs of even more customers.
We're excited to keep pushing the envelope on product innovation, and we always value customer feedback to guide our next steps. For questions, drop into the #dbt-cloud channel on dbt Slack any time.
And as a reminder, if you miss any of the action this week, you can catch a recording of our opening keynote or other sessions from Coalesce online at any time.
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




