The next big step forwards for analytics engineering

Last edited on Oct 15, 2024
If you use dbt today, you’ve bought into our way of looking at the world. Originally authored in 2016, our manifesto has changed the way that analytics is done inside the modern data stack. From the post:
Analytics teams have a workflow problem today. Too often, analysts operate in isolation, and this creates suboptimal outcomes. Knowledge is siloed. We too often rewrite analyses that a colleague had already written. We fail to grasp the nuances of datasets that we’re less familiar with. We differ in our calculations of a shared metric. As a result, organizations suffer from reduced decision speed and reduced decision quality.
Analytics doesn’t have to be this way. In fact, the playbook for solving these problems already exists — on our software engineering teams.
The same techniques that software engineering teams use to collaborate on the rapid creation of quality applications can apply to analytics. We believe it’s time to build an open set of tools and processes to make that happen.
The post goes on to introduce ideas around modularity, documentation, CI/CD, source control, testing, environments, SLAs, and more in the context of analytics. In 2016, these were novel ideas, controversial even. Today, they’ve become mainstream. Our original viewpoint, if published today, would be banal and unremarkable—this is a good thing.
I’m incredibly proud of how far we have come as an industry. But, as it turns out, we are not done learning from our peers in software engineering. Software engineers today maintain more complex codebases, work with larger groups of collaborators, satisfy more demanding SLAs, and drive more business-critical use cases than do most data professionals.
While we’ve matured tremendously as a profession over the past decade, our future calls us towards ever-more demanding use cases. This in turn demands greater maturity in our processes, teams, and tooling.
In this post I want to share the next steps in this journey we’re on.
Computing: from heroes to teams
In the early days of the technology industry, the locus of work was the individual. These individuals were lauded as “heroes” or “geniuses”; they pushed forwards a field that was very much in its nascency, a frontier with no railroad tracks.
One of the best views into this world is the book The Soul of a New Machine. Published in 1981, the book tells the story of how a small team of engineers at Data General built an entire computer—hardware and software—from scratch. The tale includes lots of individual heroic efforts and very little of what we, today, would think of as collaboration.
But as systems got more complex, relying on individual heroic efforts didn’t scale. The industry evolved complicated processes to manage this ever-greater complexity. These processes tended to be very top-down, and thought about the production of code similarly to the production of physical objects—as a factory. The entire problem was specified, broken up, and assigned out. Gantt charts ruled this era, and the predominating project management methodology was known as “waterfall.”
This approach did manage to create the larger, more complex systems that were needed, but it also resulted in higher costs (it was very inefficient) and had a higher failure rate. This way of building systems was very fragile, and missed deadlines could cascade through the system and spiral out of control.
The predominant software architecture of this era was known as The Monolith. In a monolith, all application code lives inside of a single codebase and typically executes inside of a single framework. Because of this interrelatedness, monolithic applications can become “tightly coupled” and therefore fragile / hard to maintain over time.
This was largely the state of the world until the early 2000s. But the then-still-youthful tech giants had built such complex monoliths that development velocity was declining despite the constant growth of engineering teams. And growing teams just ended up increasing the complexity of communications required.
It was right around then that Amazon dropped the hammer: moving forwards, all software systems would be constructed as services, and would communicate with one another over the network via interfaces. They went all in on service-oriented architecture (SOA), and this approach ended up leading to AWS and the cloud.
SOA is important, but potentially what is just as important is the organizational primitive that they unlock: the “two-pizza team.” Two-pizza teams are the core “primitive” for modern software engineering organizations; management, career development, planning, architecture, and tooling have all built up around this foundation. The most important principles are:
- Create teams of ~5-9 people that own their own code base and can push code to production without being blocked.
- Every codebase is responsible for exposing interfaces to other teams to build on top of.
- That team owns the entire lifecycle of their assigned surface area, including maintaining code in production and ”holding the pager.”
This is a dramatic oversimplification, but it’s good enough for our purposes here. The most authoritative source on how organizations like this should be run is called An Elegant Puzzle: Systems of Engineering Management, authored by an engineering leader at Stripe.
This socio-technical architecture has allowed software engineers to build globe-spanning systems of unbelievable sophistication. Think of all of the services you use today: these services rely on this complex web of innovation that has been built up over many, many decades. Everything from programming primitives to git to Docker to GraphQL to feature flags to Agile to consistent cultural understanding of “code smell”—every last little bit of it has helped the ecosystem steadily advance along three axes simultaneously: quality, velocity, and complexity. The consistent mandate: produce higher-complexity systems faster with higher quality.
And software engineers have done exactly that.
Complexity in the dbt ecosystem
When we initially launched dbt into the world, a big dbt project was 150 models. A couple of years in and a large project was 500 models. Today, a large project is 1,000 models, and an appreciable percentage of the dbt user population works inside of projects that have 5,000 models or more! The below chart is from dbt’s anonymous usage statistics:
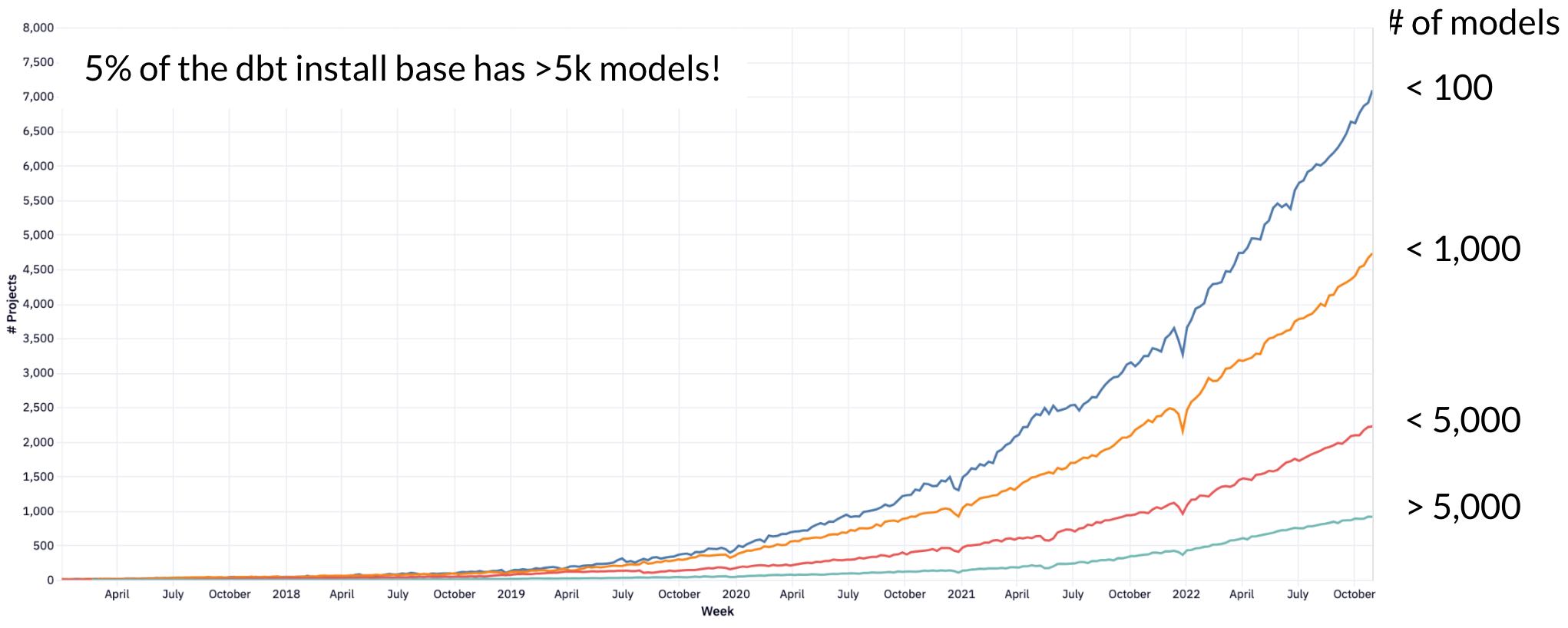
This shouldn’t be entirely surprising—as organizations’ investments in dbt deepen, the scope and complexity of dbt projects increases. This complexity is not, in and of itself, a problem—software engineers have consistently managed to deliver systems of increasing complexity for decades. The problems dbt developers face are two-fold:
- dbt does not give its users the tools to implement the same technical solutions that software engineers have used, and
- because of #1, data organizations haven’t been able to implement the organizational solutions that software engineers have used.
What is dbt missing? Let’s return to the organizing principles from earlier and ask whether dbt enables these for its users:
Create teams of ~5-9 people that own their own code base and can push code to production without being blocked.
Can dbt developers do this? In sufficiently large organizations with sufficiently complex dbt projects, they cannot. How about the second criteria?
Every codebase is responsible for exposing interfaces to other teams to build on top of.
Again, dbt developers cannot do this today. Let’s go just a bit deeper into why that is.
A scenario: The failed re-org
Let’s imagine a data organization of 50 people, a mix of data engineers, analytics engineers, and data analysts, all of whom regularly contribute to a single dbt project at a large ecommerce business. This dbt project has 4,000 models that cover every data domain within the business, from marketing to fulfillment to inventory to internal functions like people operations. The team’s tooling in the rest of their data stack is modern and well-implemented.
As the team’s code base has grown and become more critical for the organization, the team has observed the following things happen:
- Velocity and agility have slowed, creating frustration both inside and outside the data team.
- Collaboration becomes harder as no one is familiar with the entire code base. Time spent in meetings goes up relative to time spent getting things done.
- Quality becomes harder to enforce over a growing surface area and user-reported errors increase.
- SLA achievement declines as more jobs fail, but no amount of retros seem to reverse this trend.
The VP of Data has grown the team from the ground up and has been zealous about implementing current industry best practices. She’s aware of and stressed about the current worrying trends present in her organization. After going on a several-months-long search for answers, reading and talking to industry experts, she decides the answer is to split the data org into seven teams, all aligned around specific functional areas of the business. She calls this her “mesh” strategy.
One of the critical components of this strategy is to break out the monolithic dbt code base into seven distinct dbt projects, one per team. This will theoretically enable each team to own their own code base and push code to production without being blocked.
Now let’s say that the VP of Data executes the re-org, and that the teams start down the path of decomposing the dbt monolith. Two weeks later, she meets with the seven tech leads from the seven teams. They tell her that what she is asking is not possible, or at least, it’s not possible to do it in a way that gets the benefits that she’s looking for.
Why?
There are at least three things that dbt does not provide today that are all required to successfully execute this plan. Let’s go through each one.
The ability to define interfaces
Interfaces are central to the ability to organize a team and a codebase in accordance with the goals of this leader’s mesh initiative. Each team must be able to take ownership for the complexity in its own domain, but then expose their finished work in easy-to-consume interfaces that other teams and their codebases can reference. Today, dbt does not have the ability to do this.
Many teams today try to deconstruct dbt projects, but they fail when they attempt to reference models in other projects (which is inevitably critical). The two solutions that teams attempt are both bad options:
- They reference a dataset from another project directly (using schema.table) or register it as a source. Either of these breaks the DAG, environment management, etc.
- They import the project they want to reference as a package and use ref(). This re-couples the two projects together; they are now effectively a single monolithic project again.
In both cases, the team who owns the upstream project is unable to control what models it exposes to other teams, which is the core principle of interface design.
The ability to define and validate contracts
Not only must teams be able to define interfaces between two different functional areas, they must be able to prove that these interfaces are stable and reliable. Both sides of the contract rely on this ability.
- The author of the interface relies on contracts to ensure that it is not accidentally causing breakages downstream which it did not anticipate.
- The consumer of the interface relies on contracts to ensure that is not and will not be broken.
Contracts on top of interfaces and automated mechanisms to validate them are the foundation of cross-team collaboration.
The ability to upgrade your code without causing downstream breakages
Having created interfaces and validated them using contracts, teams now require the ability to break these contracts in a controlled fashion. This is typically handled by several things working together:
- Using a versioning scheme
- Creating an automated way of resolving a reference to a particular version of an object
- Creating a mechanism to deprecate old versions of an object
Using these three capabilities, teams can update their contracted interfaces periodically by incrementing their version numbers and then communicating a deprecation window to downstream teams.
With these three abilities, the team would be able to be successful. Without these three abilities, there is simply no path forwards to implementing a mesh strategy like the one the VP outlined above.
How we’re fixing this
We can’t execute your re-org or rearchitect your project, but we can make these things possible. And we’re investing heavily in doing exactly that.
dbt Core v1.5 is slated for release at the end of April, and it will include three new constructs:
- Access: Choose which models ought to be “private” (implementation details, handling complexity within one team or domain) and “public” (an intentional interface, shared with other teams). Other groups and projects can only ref a model — that is, take a critical dependency on it — in accordance with its access.
- Contracts: Define the structure of a model explicitly. If your model’s SQL doesn’t match the specified column names and data types, it will fail to build. Breaking changes (removing, renaming, retyping a column) will be caught during CI. On data platforms that support build-time constraints, ensure that columns are not null or pass custom checks while a model is being built, in addition to more flexible testing after.
- Versions: A single model can have multiple versioned definitions, with the same name for downstream reference. When a mature model with an enforced contract and public access needs to undergo a breaking change, rather than breaking downstream queriers immediately, facilitate their migration by bumping the version and communicating a deprecation window.
These core capabilities are the prerequisite to supporting true multi-project collaboration. In the near future, we’ll be moving towards a world in which these constructs span multiple dbt projects, creating a mesh of interconnected, domain-owned, dbt codebases. The essential mechanism enabling this will be to ref a public, contracted, and versioned model from another project.
What the future looks like
In the future, individual teams will own their own data. Data engineering will own “core tables” or “conformed dimensions” that will be used by other teams. Ecommerce will own models related to site visits and conversion rate. Ops will own data related to fulfillment. Etc. Each of these teams will reference the public interfaces exposed by other teams as a part of their work, and periodically release upgrades as versions are incremented on upstream dependencies. Teams will review PRs for their own models, and so have more context for what “good” looks like. Monitoring and alerting will happen in alignment with teams and codebases, so there will be real accountability to delivering a high quality, high reliability data product. Teams will manage their own warehouse spend and optimize accordingly. And teams will be able to publish their own metrics all the way into their analytics tool of choice.
Teams owning their own data. This is how analytics scales. I’m excited about this future and hope you are too.
Register now to attend Coalesce 2023, the analytics engineering conference.
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




