What, exactly, is dbt?

Last edited on May 04, 2026
dbt has changed evolved significantly since this post was written back in 2017. From offering dbt as a service with dbt Cloud, to launching a semantic layer, to supporting various development environments and numerous ecosystem integrations, dbt Cloud is the best place for data teams and data consumers to build and use trusted data. Today, more than 40,000 companies use dbt in production. For the most up-to-date information on dbt, check out our blog.
dbt is a command line tool that enables data analysts and engineers to transform data in their warehouses more effectively. Today, dbt has ~850 companies using it in production, including companies like Casper, Seatgeek, and Wistia.
That's the elevator pitch. It works reasonably well at getting a head-nod at a meetup but it doesn't really convey a satisfying level of detail. To anyone who's used dbt, that description falls well short of their experience of the product.
The hard part about explaining dbt to someone who hasn't yet played with it is that it is not quite like anything else. dbt is not Uber for cats, or Harry's for fingernail clippers. It's a little bit like, but much more than, Looker PDTs. It has similarities with Airflow, but is built for a completely different user. dbt is its own unique thing.
So: if you want to go deeper than the elevator pitch, you have to go pretty deep. If you want to understand what dbt is, where it fits into the ecosystem, and how you should think about using it, this is that post.
dbt and the modern BI stack
dbt fits nicely into the modern BI stack, coupling with products like Stitch, Fivetran, Redshift, Snowflake, BigQuery, Looker, and Mode. Here's how the pieces fit together:
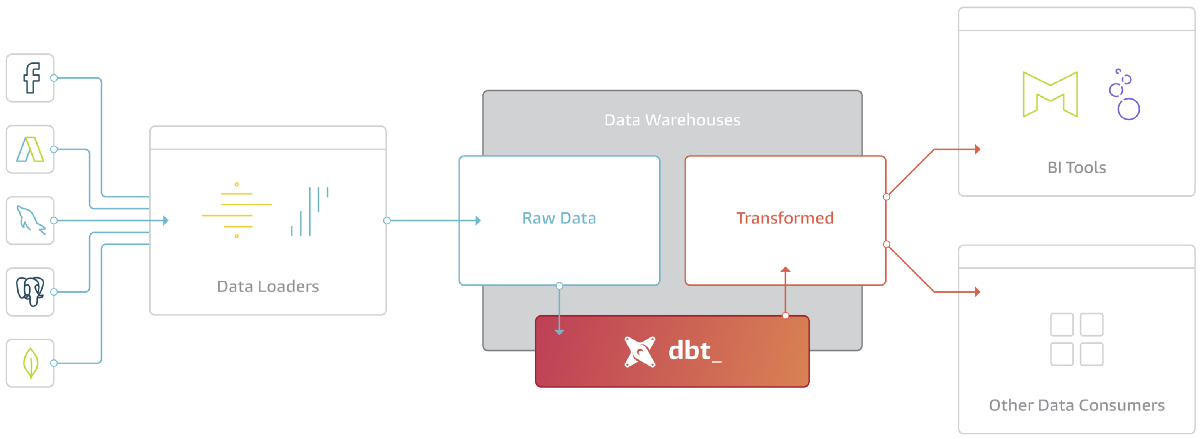
dbt is the T in ELT. It doesn't extract or load data, but it's extremely good at transforming data that's already loaded into your warehouse. This "transform after load" architecture is becoming known as ELT (extract, load, transform).
ELT has become commonplace because of the power of modern analytic databases. Data warehouses like Redshift, Snowflake, and BigQuery are extremely performant and very scalable such that at this point most data transformation use cases can be much more effectively handled in-database rather than in some external processing layer. Add to this the separation of compute and storage and there are decreasingly few reasons to want to execute your data transformation jobs elsewhere.
dbt is a tool to help you write and execute the data transformation jobs that run inside your warehouse. dbt's only function is to take code, compile it to SQL, and then run against your database.
dbt is a compiler and a runner
At the most basic level, dbt has two components: a compiler and a runner. Users write dbt code in their text editor of choice and then invoke dbt from the command line. dbt compiles all code into raw SQL and executes that code against the configured data warehouse. This is what the user interaction looks like:

What you're seeing is a user viewing the code for a model and then building that model and its parents. In this example, each of the models are materialized as views, but dbt supports any materialization strategy that you can express in SQL. To define these terms:
model: a data transformation, expressed in a single SELECT statement.
materialization: the strategy by which a data model is built in the warehouse. Models are materialized into views and tables, but there are a large number of possible refinements, including incrementally-loaded tables, date-partitioned tables, and more.
Every model is exactly one SELECT query, and this query defines the resulting data set. Here's a typical example model from our Stripe package:
with discounts as (
select * from {{ref('stripe_discounts')}}
),
invoice_items as (
select * from {{ref('stripe_invoice_items')}}
),
joined as (
select
invoice_items.*,
case
when discounts.discount_type = 'percent'
then amount * (1.0 - discounts.discount_value::float / 100)
else amount - discounts.discount_value
end as discounted_amount
from invoice_items
left outer join discounts
on invoice_items.customer_id = discounts.customer_id
and invoice_items.invoice_date > discounts.discount_start
and (invoice_items.invoice_date < discounts.discount_end
or discounts.discount_end is null)
),
final as (
select
id,
invoice_id,
customer_id,
event_id,
subscription_id,
invoice_date,
period_start,
period_end,
proration,
plan_id,
amount,
coalesce(discounted_amount, amount) as discounted_amount,
currency,
description,
created_at,
deleted_at
from joined
)
select * from finalThis particular model is responsible for associating discounts and invoices in Stripe, a task that's more challenging than one would anticipate. The only elements of this code that are not pure SQL are the ref() calls at the top.
dbt code is a combination of SQL and Jinja, a common templating language used in the Python ecosystem. ref() is a function that dbt gives to users within their Jinja context to reference other data models. ref() does two things:
- It interpolates itself into the raw SQL as the appropriate schema.table for the supplied model.
- It automatically builds a DAG of all of the models in a given dbt project.
Both of these are core to the way that dbt operates. Because dbt is interpolating the locations of all of the models it generates, it allows users to easily create dev and prod environments and seamlessly transition between the two. And because dbt natively understands the dependencies between all models, it can do powerful things like run models in dependency order, parallelize model builds, and run arbitrary subgraphs defined in its model selection syntax.
Some graphs are fairly straightforward. This graph is from our Snowplow package that incrementally sessionizes Snowplow's raw web events stream:

Other graphs are much more complicated. The following graph is from a venture-funded ecommerce company:

dbt is a complete Jinja compiler, so anything you can express in Jinja, you can express in dbt code. If statements, for loops, filters, macros, and more. It turns out that SQL is far more powerful when you pair it with a fully-featured templating language.
In addition to stock Jinja, dbt provides additional functions and variables within the Jinja context that allow users to express data transformation logic straightforwardly. Here's a simple example:
select * from {{ref('really_big_table')}}
{%raw%}
{% if incremental and target.schema == 'prod' %}
where timestamp >= (select max(timestamp) from {{this}})
{% else %}
where timestamp >= dateadd(day, -3, current_date)
{% endif %} This code is saying: if I'm being run in production and this is an incremental load (only loading new rows), only select rows that are more recent than the most recent timestamp currently in the table. If I'm being run in development, just grab the past three days of data.
This is an extremely useful pattern in practice: this model will execute different SQL depending on the current environment (dev vs prod) and state of the database. For tables with a billion or more rows of data, adopting this pattern can significantly improve performance in both environments.
That's just the beginning of what you can express in dbt. We've written functions to union together two tables that have differing schemas, analyze a table and re-compress it with optimal encoding, automatically build Bigquery date-partitioned tables (releasing soon!), and much more. Writing modular code like this allows users to automate complicated and time-consuming tasks that previously required manual effort.
What's critical to note is that all of the code I just linked to is written in user-space. In fact, dbt's Python code doesn't actually know how to write any SQL: dbt uses its own templating capabilities to deliver its most-used features like the Redshift table and view materializations. You can find the code here. If you don't like how these default features work, you can override dbt's SQL with your own.
dbt's goal is not to be a library of SQL transformations, but rather to give users powerful tools to build, and share, their own transformations. To that end, dbt ships with a package manager.
dbt ships with a package manager
dbt's package manager allows analysts to publish both public and private repositories of dbt code which can then be referenced by others.
Most analysts are used to being users of features, not developers of features. Software engineers are used to wanting a new feature from a tool they're using and simply building it and contributing their work back to the community. With dbt, analysts can do the same. With dbt's package manager, analysts can build libraries that provide commonly-used macros like dbt_utils or dataset-specific models like snowplow and stripe, and then share them with their peers.
With Stripe, you can go all the way from the Stripe API's event stream to a sophisticated monthly subscription dashboard in less than five minutes. And with Snowplow, you can incrementally transform billions of web events into web sessions with code that's been tested and optimized across dozens of Snowplow users. That's leverage.
This past week I had to release a new version of my Stripe package when a data engineer at Buffer let me know in a Github issue that I had a bug. Recently I received a PR for that same repo from an analyst at Makespace. This is how we believe that analytics will increasingly be done.
dbt transforms analysts from tool-users into tool-makers.
a programming environment for your database
dbt is made up of Jinja, custom Jinja extensions, a compiler, a runner, and a package manager. Combine those elements together and you get a complete programming environment for your database. There is no better way to write SQL-based data transformation logic against a data warehouse today.
dbt has evolved to become the product that it is specifically because of what we believe to be true about the world. Those beliefs are as follows:
- code, not graphical user interfaces, is the best abstraction to express complex analytic logic.
- data analysts should adapt similar practices and tools to software developers. (full post)
- critical analytics infrastructure should be controlled by its users as open source software.
- analytic code itself --- not just analytics tools --- will increasingly be open-source. (full post)
These core beliefs gave rise to the product that exists today and they form the foundation of the many exciting extensions we hope to build in the future.
Thanks for your interest. If you'd like to play with dbt, read the overview, run through the installation instructions, and ask any questions in Slack. We'll see you there 👋
Changelog:
- October 2018: updated dbt user count at the beginning of the post from 100 to 280
- September 2019: updated dbt user count at the beginning of the post from 280 to 850
- May 2021: updated dbt user count at the beginning of the post to 5000
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




