
In our series of articles on data mesh architecture, we’ve looked at what the data mesh is and the four principles behind it, and its components,.
In this installment, we explore the principle of domain-driven data ownership. We explain what data domains are, and how they bring better scalability and faster delivery times to new data products.
Check out all of the key components of data mesh:
[See how dbt Mesh reduces complexity without sacrificing governance.]
What is a data domain?
In data mesh, a data domain is a logical grouping of data, often source-aligned or consumer aligned, along with all of the operations that its objects support.
The diagram below shows an example of how data domains could function in practice. The domains themselves can be loosely categorized into whether they are source-aligned, customer-aligned, or aggregates of data. Each domain itself is aligned, not with a set of technologies, but with the part of the business that it supports.
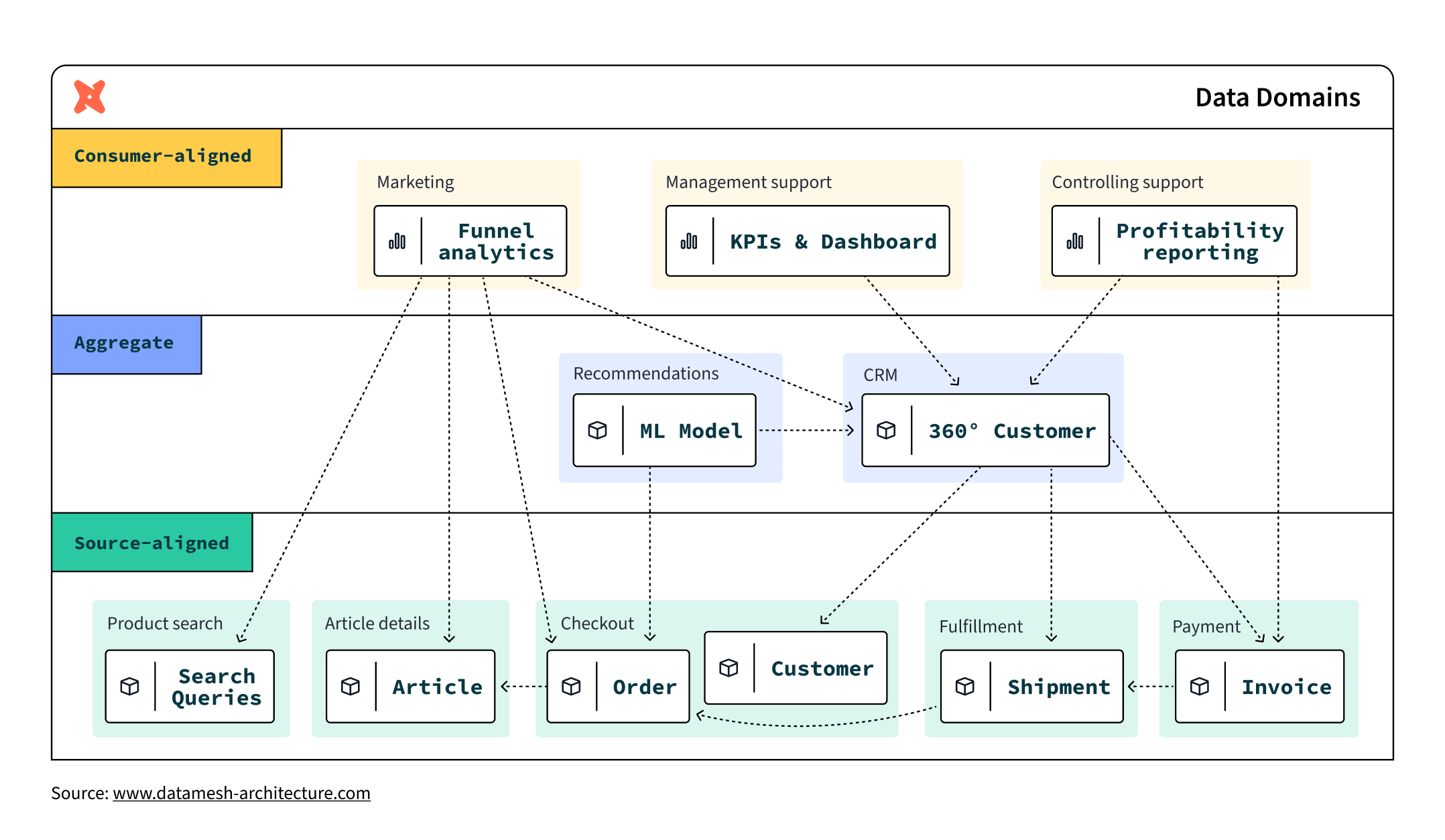
(source https://www.datamesh-architecture.com/)
No matter how you structure a data domain, one principle doesn’t change: Data domains should be owned by the team closest to the data.
Data domain examples
Consumer-aligned data domains are structured around the needs of data consumers, like business teams or end users. Here are a few examples:
- Customer analytics: Aggregates customer behavior and engagement metrics to support marketing and sales decisions.
- Revenue reporting: Provides financial insights to stakeholders through structured, consumer-friendly datasets.
Source-aligned data domains are organized around upstream data sources within the business. Here are a few examples:
- Transactions: Captures raw sales or payment events from point-of-sale or ecommerce platforms.
- Inventory: Reflects stock levels and movements from warehouse or supply chain systems.
- HR systems: House employee records and operations data from core human resources platforms.
The challenge with centralized ownership
In the absence of clearly demarcated data domains, many organizations store corporate data that is maintained by a single, central data team. That team "owns" the data from a technical standpoint. Any changes to its structure or format require that business owners file change requests with the engineering team.
This model works for many companies...up to a point. Over time, these large, monolithic data structures become harder to navigate. Complex interdependencies develop between teams, requiring each team to understand other teams' data schemas to accomplish even mundane tasks.
The single-team approach also doesn't scale well. As more and more requests come in, the data engineering team becomes a bottleneck and falls further and further behind. Additionally, the data engineering team isn't the true owners of the data - the data producers are. That limits how much data engineering can actually do, further increasing friction between them and data end users.
How data domains change the way we think about data
Data domains address this by parceling out data schemas into self-contained definitions owned and maintained by the business team that owns the data. The team owns the data storage and all processes - generation, collection, data pipeline transformations, APIs, reporting, etc. - that accompany it. Its output is a data product - a data container or a unit of data that directly solves a customer or business problem.
This is a hallmark of data domains: they are decentralized. Domain teams work independently while registering their work products - their data sources and targets, reports, etc. - with a central authority, such as a data catalog. This approach, known as federated computational governance, enables business teams to move quickly without sacrificing compliance and accountability. This ownership change is why data mesh is called a socio-technical change, because ownership and architecture changes.
You can think of a data domain as a "service oriented architecture" for data. Each data domain team is responsible for maintaining its data boundaries and the operations that support them.
The benefits of data domains vs centralized ownership
Organizations managing large-scale data systems often face a key architectural decision: whether to centralize data ownership or distribute it across domain-specific teams. A domain-based approach offers several compelling advantages that can improve data accuracy, streamline collaboration, and accelerate development.
Accuracy
Domain ownership shifting to business teams means, data domains theoretically foster greater accuracy in data. This is because that team knows its business better than others in the organization, and thus is in the best position to make decisions around how the data is structured and managed.
Separation of concerns
Data domains also foster clearer separations of concerns. This makes it easier to onboard data and software engineers onto a project. New engineers don’t have to understand a company’s entire data landscape to get started. They only need to understand the data and operations supported by their part of the business.
Cross-team synchronization
This separation of concerns also simplifies cross-team synchronization. With data domains, a team can decide which of its data it exposes to other teams and which data remains internal. It can also define standard data operations via APIs. This enables teams to interface with one another using clearly-defined contracts, as opposed to understanding the (usually undocumented) intricacies of their full data schemas.
Faster development times
Finally, data domains can enable faster development times and a shorter time to market for new data products. Data domain teams are smaller and more focused than a general data engineering team. That enables them to work more like a small, service-oriented software engineering team. The team can define a strict scope of work, ship new versions of its products iteratively, and make quick changes in response to shifting conditions.
How data domains work
So how does a data domain work in practice? Each organization will have its own unique implementation. But here are a few general guidelines on how to move to a domain-oriented approach.
Initializing and developing a data domain
In a full data mesh architecture, data domain teams are usually supported by a centralized data platform. The centralized data platform standardizes data storage, data transformation, data tools, and practices.
This enables data domain teams to remain focused on the domain-specific portions of their business instead of reinventing the wheel regarding data management. It also ensures consistent technical support and cross-team data governance.
In a self-service infrastructure, a data domain team can request the data storage, computing power, and other tools required to design and implement its domain and data products. This enables domain teams to operate largely independently from the centralized data engineering platform team, thus accelerating data product delivery.
Designing a data domain
When designing a data domain, domain teams need to answer a few fundamental questions:
- Where are we sourcing our data?
- What does our data schema look like?
- What transformations must we apply to our source data to work with it efficiently?
- How do other teams access our data?
- Who has what rights to which data sets?
- Which data should be public and which data should be internal to our team?
- Which data needs to be tagged as sensitive - e.g., Personally Identifiable Information (PII)?
Before shifting to a data domain framework, companies should settle on tools and conventions for codifying these design decisions. These tools should be a standard part of a self-service data infrastructure.
dbt data models and model contracts are examples of tools you can use here. dbt models use simple SQL or Python models to define how to transform data between source and destination formats. You can also define data access rules through simple declarative YAML markup. Model contracts further define the conditions that the domain team guarantees to its external consumers that its data fulfills.
Registering the components of a data domain
As part of a self-service data infrastructure, the centralized platform team will also offer a method for registering new data products, their sources, contracts, and their outputs from a data domain. Registration:
- Enables other teams to find a data domain team’s data products and use them in their own data products
- Identifies the owners of a data domain so that other teams can easily find and work with them
- Enabled securing and classifying all data in a company to ensure compliance with industry standards and legal regulations
Registration is usually managed by a data catalog, which tracks and manages all of the data in a company’s data estate. The data domain team ensures that its assets - data sources and destinations, models, contracts, APIs, data products, etc. - are registered in the data catalog. The team is also responsible for tagging all of its data appropriately for compliance and adhering to corporate standards around data quality.
Managing and revising the data domain
Data domain teams publish their data products with their accompanying contracts. At a minimum, contracts specify an owner, a version, a description of the data that the product exposes, and the conditions that data meets (e.g., field is non-null, is maximum x characters long, contains a specially-formatted string, etc.).
Because data domain teams are small and lean, they can work agilely and release new versions of their data products iteratively. Teams can publish new versions of their contracts to the data catalog, which in turn will notify downstream teams that an update is available. Typically, the data domain team will commit to maintaining backward compatibility support for the old contract for a limited time. This increases trust between teams, as it creates a commitment that the team won’t break another team’s project.
Data domain teams will also need to make changes as teams that they are dependent on change their contracts. For example, a sales team might depend on product roadmap information from an engineering team to create reports related to upcoming features. If the engineering team changes the format of its data, the sales team will need to change its own data processing and storage logic.
Data Domain FAQs
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.



