Data modeling techniques for modern data warehouses

Last edited on Nov 04, 2025
I remember the first time I showed a business user “under the hood” of the dbt project for our organization:
Them: “Wow! There are so many models and there’s so much work here; I would have never known that because of how intuitive the data is to use in Looker.”
Me: “😅😅...I know”
These data models formed the heart of analytics at our organization—powered every single dashboard in our BI tool— and the majority of business users at that time thought we conducted magic behind the scenes to get the data in the proper state. The validation of the work and energy that went into those data models from my colleagues who depended on that data was gratifying.
What is data modeling?
Despite how it may appear, data modeling isn't some fantastical process made up of *waves hands airily* magic 🪄. Formally, it’s the process data practitioners use to make raw data into meaningful business entities in their data warehouse.
There’s a lot of SQL (and pointedly not magic) involved during the transformation process. Data teams rely on tried and true techniques to create predictable and scalable data models.
Data modeling shapes raw data into the story of a business and, establishes a repeatable process that can help create consistency in a data warehouse: how schemas and tables are structured, models are named, and relationships are constructed. At the end of the day, a solid data modeling process will produce a data warehouse that's navigable and intuitive, with data models that represent the needs of the business and help build trust in data and data teams.
Data modeling techniques
Data modeling…the perfect balance between art and science, chaos and structure, and pain and joy 😂. At the end of the day, there are many ways to model your data and get it in a place that’s best suited for your business needs. Your downstream use cases, data warehouse, raw source data, and the skills of your data team, including analysts, will all help determine which data modeling approach is most appropriate for your business.
This page is going to cover some of the most common types of data modeling techniques we see used by modern analytics teams (relational, dimensional, entity-relationship, and data vault models), what they are at a high level, and how to unpack which one is most appropriate for your organization.
Relational model
A relational data model is a broad way to represent data and their relationships to other data. In a simple relational model, data is stored in a tabular format (think rows and columns) and connects to other tables via foreign keys.
At the end of the day, almost all of the data modeling techniques we discuss here and see in the real world are a type of relational model. These models are the building blocks of most modeling techniques.
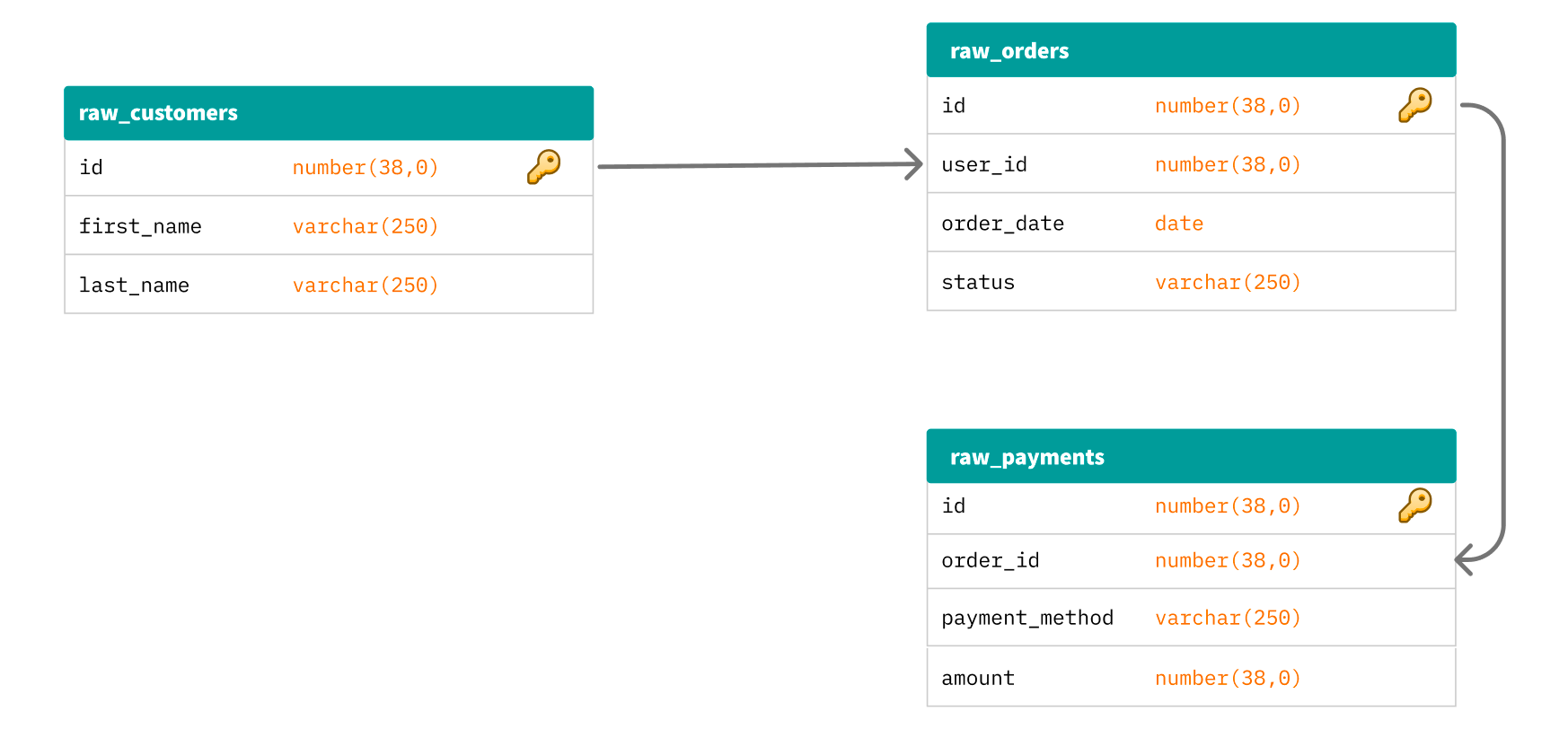
Relational models themselves don’t necessarily give data teams the best way to scale their data models because of their focus on relationships rather than business logic or use cases. Instead, they offer a foundation to build more robust relational modeling processes, such as dimensional modeling, to establish data models that scale in an organized and repeatable manner.
Good fit for:
- Low-volume data and a small number of data sources
- Simple use cases for the data
- Low-medium concern around data warehousing costs (because relational models often need joining to be made meaningful)
Dimensional data model
Dimensional data modeling is one of the predominant models used in modern data stacks, as it offers a unique combination of flexibility and constraint. Dimensional modeling is a type of relational model that categorizes entities into two buckets: facts and dimensions.
- A fact is a collection of information about an action, event, or result of a business process. Facts typically describe the verbs of your business (ex., account creations, payments, and email events).
- A dimension, on the other hand, describes who or what took that action (think: users, accounts, customers, and invoices—the nouns of your business). Together, fact and dimension models form the tables that describe many modern businesses and offer an intuitive way to design the entities in your data warehouse.
Before the rise and wide adoption of cloud data warehouses—where storage is cheap and compute costs become the larger concern—data teams often designed dimensional data models into star or snowflake schemas to concretely define fact and dimension tables. This clean breakup of models aimed to reduce the cost of large, wide tables with many columns.
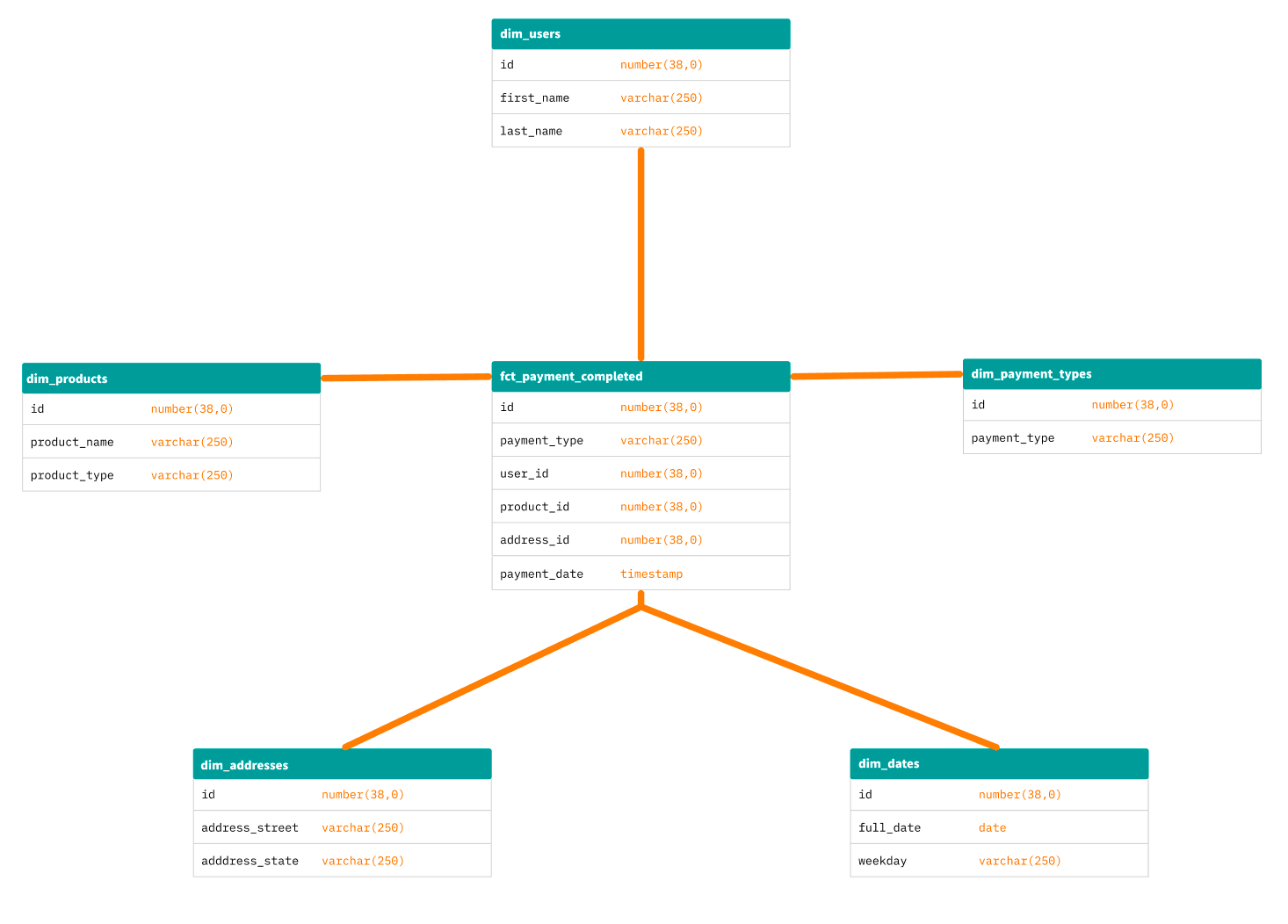
Good fit for:
- Medium-to-large number of data sources
- Centralized data teams
- End-use case for data is primarily around business intelligence, embedded analytics, and providing insights
- Teams that want to create an easily navigable and predictable data warehouse design
Read more here on how we like to structure our dbt projects and data models.
Entity-relationship data model
Entity-relationship (ER) data models have entities at the heart of their modeling. ER modeling is a high-level data modeling technique that's based on how entities, their relationships, and attributes connect:
- Entities: Typically represent core business objects, events, or functions; some examples of an entity could be customers, accounts, and products.
- Attributes: The columns that describe an entity.
- Relationships: The actions or relationships that join entities together. For example, customer and product entities can be joined by a purchase action.
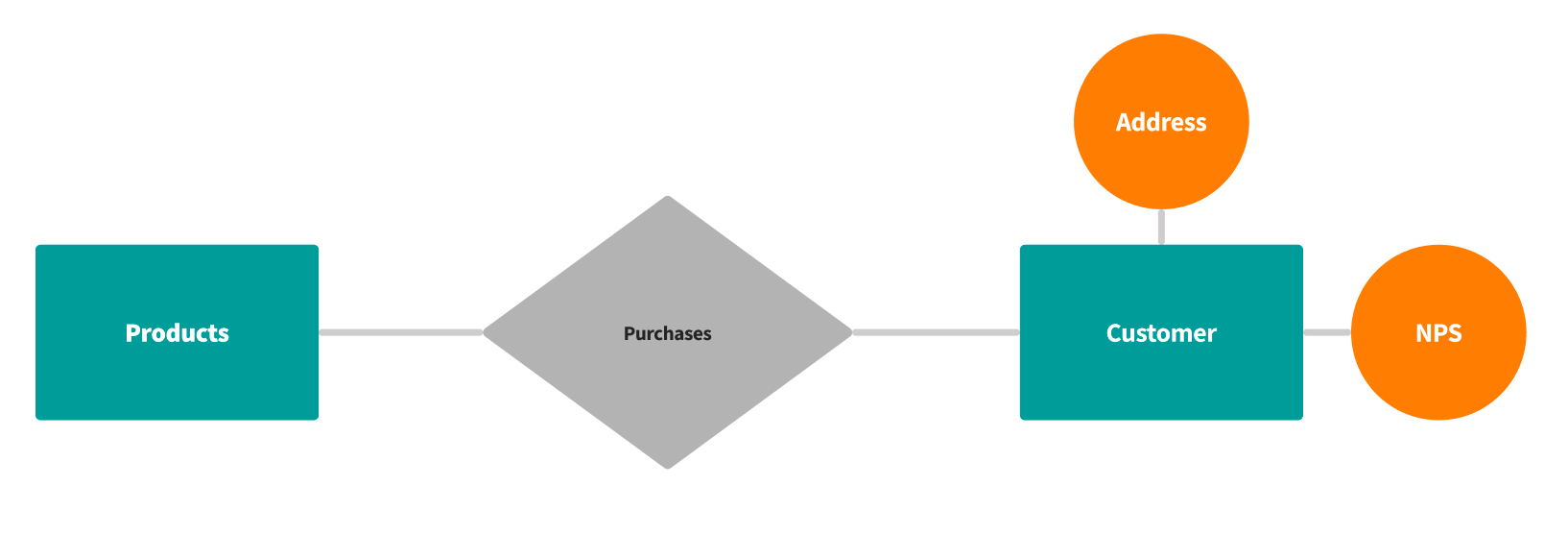
The focus of ER modeling is often around the processes of a business. Relational models can connect any which way, but ER models are meant to form an architecture that's relatively concise and based on actual business procedures (events) and entities.
However, ER modeling can still be vague around long-term database structure. It’s more of a way to show how tables can connect. It's useful for understanding database architecture at a higher level. To make ER models more meaningful and scalable, data teams often take the foundational learnings from an ER model to form more complex data model architectures like dimensional modeling.
Good fit for:
- Low-complexity data that connects neatly together
- Simple, business-focused downstream use cases for the data
- Central data teams that have deep knowledge of the facets of their data
Many data sources you ingest into your data warehouse via an ETL tool will have ERDs (entity relationship diagrams) that your team can review to better understand how the raw data connects. Slightly different from an ER model itself, ERDs are often used to represent ER models and their cardinality (ex., one-to-one, one-to-many) in a graphical format.
These ERDs will often look a little like the relational model shown earlier. Using these diagrams together with another data modeling technique, such as dimensional modeling, helps data teams efficiently wade through raw data and create business entities of meaning.
Data vault model
A data vault model abstracts entities, their relationship to each other, and their attributes into separate tables called hubs, links, and satellites:
- Hubs: Contain the unique key of the entity they represent, as well as a hashed representation (as a surrogate key). Some example hubs for a typical DTC shop would potentially be h_customer, h_product, and h_payment.
- Links: Contains the foreign keys to other hubs. In our example shop above, an h_customer hub would likely have a link to an h_payment hub by having a link containing the customer id and a payment id.
- Satellites: Contain the attributes or descriptors of an entity. For a h_customer hub, a satellite could contain information like customer shipping address, email, NPS, etc.
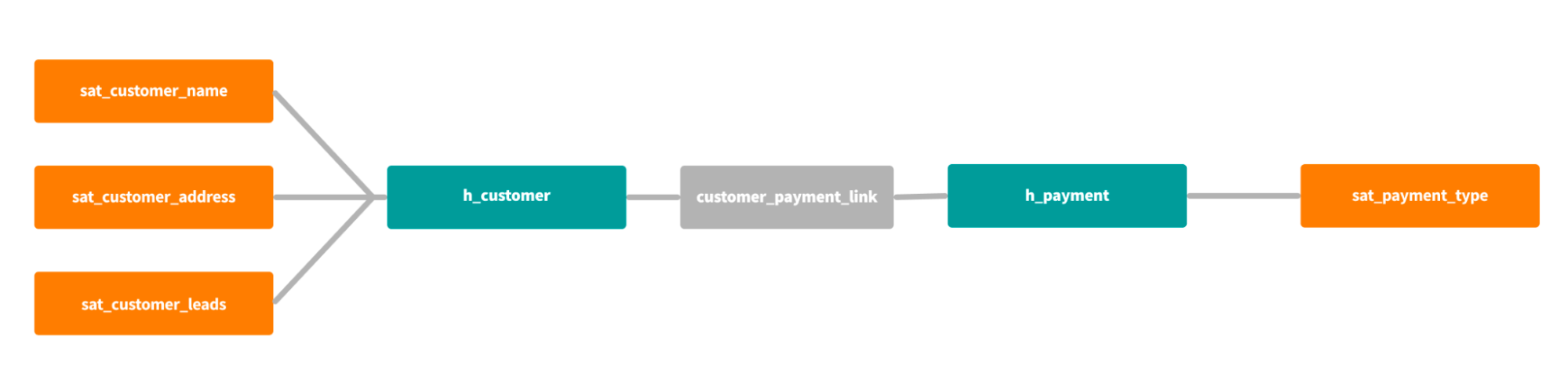
Data vault architecture was invented to easily track data changes by having an insert-only mindset; whenever a row changes in a classical data model, a new row is either added or the existing row is modified. In a data vault world, data updates are represented only by new rows.
Like other data models that encourage staging and mart layers, data vault architectures also support using raw, business, and information vaults. The consistency in the structure of a data vault encourages data teams to build a layer of organization for their data; this “safety” layer allows some teams to build other types of data models on top of these foundational models.
Data vault modeling can feel repetitive or prescriptive, given the consistent structure of hubs, links, and satellites.
Good fit for:
- Enterprise teams where the ability to audit data is a primary concern and data modernization is needed
- Teams that need flexibility and who want to make large structural changes to their data without causing delays in reporting
- More technical data teams that can manage and govern the network-like growth of data vault models
Graph data model
A graph data model abstracts data into points and connections between those points. The points are called “vertices” and the relations are called “edges”
- Vertices: Represent objects in the model. For example, users of an app, locations of facilities, sensors in an array. They may contain data being “labeled” or “colored” by the associated information.
- Edges: Represent connections between the objects. For example, users following other users, locations connected by routes, sensors connected by cables. Edges may be directed if the connections aren't symmetric, like a follow.
Graph data models are robust, granular models that store the data about relations between objects in full detail. Modifying a graph model requires a system that can identify any object, and identify its relations to other objects. This information gathering process is often called “crawling.”
Graph models are powerful in their detail, but this comes at the cost of storage efficiency. Every object and connection must be stored as a piece of data for the graph, meaning a graph with 10 vertices may require upwards of 100 pieces of data to store. Large graphs are notoriously challenging to compute, requiring specialized algorithms.
Good fit for:
- Graph models are best suited to technical scenarios where all the specifics matter
- Data systems that involve physical networks like an IoT network or sensor array.
- Research teams that need exact information
- Enterprises that want to develop powerful models using all of their available data systems.
Hierarchical data model
A hierarchical data model abstracts data into parent-child relationships between objects, forming tree structures. All relationships in a hierarchical model are assumed to follow the same pattern:
- Parents: any object in a hierarchical model can be the parent of another object. A parent can have any number of children
- Children: any object can be the child of another, but each child has only one parent. A child can be a parent of its own children in turn.
As defined, the parent-child relationship is one-to-many, so hierarchical models are used to abstract situations where nested one-to-many relationships are common, for example, in physical assembly systems where products are composed of components which are in turn composed of parts.
Hierarchical models are similar to graph models, but because of their regularity, they're much easier to store. All you need to do is associate a list of children with each parent.
Hierarchical models are fairly specific, so they do not work in every scenario, but when they do, they are highly efficient, making them a popular model in many cases.
Good fit for:
- Systems with nesting components, such as assembly diagrams where components are formed of other components and basic parts
- Branching data systems in which one object relates to many downstream objects
- Information with nested scopes like national to state to city level focus
The best data modeling technique is a consistent technique
At the end of the day, there’s no clear “right” or “wrong” data modeling technique for your data and business. However, there are ones that are probably more appropriate and aligned with the skillsets of your team. Before you commit to a data modeling technique, ask yourself (and your team members):
- What are my primary end-use cases for the data?
- Who needs to be able to query my final data or navigate through my data warehouse?
- How many data sources am I dealing with? How complex is my data?
- Which data modeling technique best suits the raw data formats and warehouse I work with?
- What would governance and standardization look like with this modeling technique?
💡 Want to go deeper on how to structure modular data models with dbt? Explore our guide to modular modeling techniques.
Like most analytics work, there’s a fine line between rigidity and flexibility with data modeling; you’ll likely never have a full warehouse of perfect dimensional data models that meet Kimball or Inmon’s standards because you adjust these techniques to your data and the needs of the business.
The dbt approach to data modeling
And while data modeling is more art than science at times, there's still a vital need for governance in this practice. Using a data transformation tool that supports any data modeling technique, peer review, integrated testing and documentation, and version control is the first step to governing and creating a consistent process for your data modeling.
Next Action
Ready to learn more about how dbt can support your data modeling efforts? Take a look at some of the resources below to see how modern data teams are transforming (😉) the way they tackle data modeling with dbt:
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




