How to choose a data quality framework

last updated on Apr 09, 2025
The phrase “garbage in, garbage out” is as true now as it was when it was coined 60-odd years ago. In fact it may be more true than ever in the age of Generative AI. Your analytics and AI applications require high-quality data to yield accurate, relevant, and timely outputs to drive business decision-making.
High data quality requires a data quality framework. We’ll discuss what a data quality framework is and how to choose one—or, even better, create one customized to your business.
What is a data quality framework?
A data quality framework is a set of principles, standards, rules, and tools your organization uses to implement, test, and monitor the overall health of data. It provides a common foundation that individual teams can leverage to ensure their data is accurate, timely, and relevant.
Establishing a data quality framework builds trust between data teams and business stakeholders. Furthermore, it creates an analytics foundation built on governance, scale, and accountability.
How it fits within the Analytics Data Lifecycle
A data quality framework isn’t a one-time band-aid or a silver bullet solution to your data issues. Rather, it’s a process that you implement throughout every stage of the Analytics Data Lifecycle (ADLC). Your data quality framework will grow and mature—adding new data cleansing and quality rules, providing better support for early detection of data errors, detecting anomalies through AI, etc.—as you gather on what works and what doesn’t.
Components of a data quality framework
Any set of rules, processes, and tools you set up to manage data quality constitutes a data quality framework. There are also several pre-built frameworks designed to support specific industries or data sets.
Data quality frameworks differ in their focus and implementation (e.g., a focus on different dimensions of data, on a specific type of data, etc.). However, all of these frameworks will have the following components in common.
Data pipelines
Data pipelines define the workflow for ingesting data into your system and transforming, testing, and publishing it for consumption by data stakeholders. Data pipelines are the beating heart of your data quality framework, keeping high-quality data flowing to production.
Data pipelines may consist of a mix of manual and automated processes. For example, a data engineer or analytics engineer may check-in data pipeline transformation code that another engineer reviews. This approval would trigger a job that runs data tests in a pre-production environment before pushing the changes live.
Data quality dimensions
“Data quality” isn’t monolithic. It consists of a number of dimensions that include:
- Usefulness
- Accuracy
- Validity
- Uniqueness
- Completeness
- Consistency
- Freshness
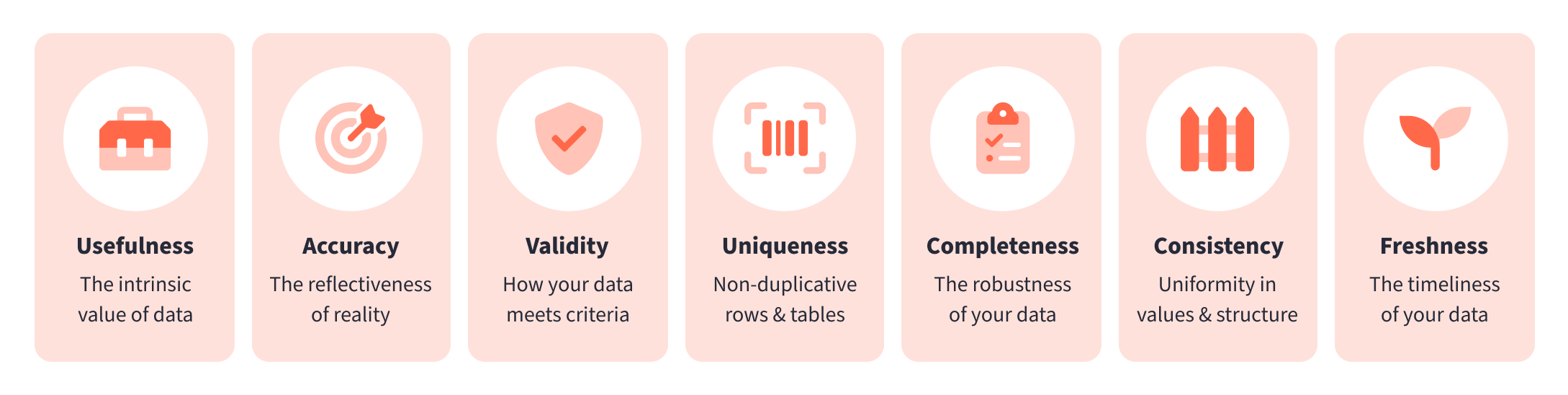
A data quality framework may focus on different dimensions, emphasizing some over others. That focus may also shift over time as your program grows and evolves.
Data quality and data cleansing rules
Data quality rules check for conformity to one or more of the above data quality dimensions. Common rules include:
- Unique record check
- Non-null fields
- Accepted values (e.g., status of an order, format of a customer ID)
- Relationships and referential integrity
- Freshness and recency
Data governance rules
Data governance is a set of rules and processes for collecting, storing, cleaning, and securing data for use. While it includes data quality, it also establishes rules for who owns data, how data is classified, and how your organization complies with the various data compliance and privacy regulations that govern your business (e.g., GDPR or HIPAA).
Data quality monitoring
Detecting data quality issues proactively eliminates errors from data before they negatively impact data stakeholders and business decision-makers. Data quality monitoring constantly inspects incoming data and generates alerts at every part of the data lifecycle, testing data in its raw, transformed, and production form.
Data quality tools
Last, you need high-quality tools to power your data quality framework. Tools like dbt Cloud act as a data control plane, accelerating data delivery, tuning data quality, and optimizing compute costs. They help data teams scalably build, deploy, monitor, and discover data assets so organizations can move faster with trusted data.
Popular data quality frameworks
There are several data quality frameworks. Below is a short list of some of the more well-adopted ones, along with where and how data teams use them.
Data Quality Assessment Framework (DGAF)
Developed by the International Monetary Fund (IMF), the DGAF defines a structure for evaluating your organization’s current practices against standard best practices for data quality.
The DQAF tracks data quality across six dimensions—prerequisites, assurances, soundness, accuracy and reliability, serviceability, and accessibility—along with a set of elements and indicators for each dimension. It’s used primarily by governmental bodies, international organizations like the IMF and the UN, and organizations evaluating data for policy analysis or forecasts.
Total Data Quality Management
Total Data Quality Management is a holistic framework developed at MIT. Rather than insist on a defined set of metrics and data dimensions, it breaks down data quality into four stages of defining, measuring, analyzing, and improving the data quality dimensions that matter most to your business.
ISO 8000
ISO 8000 is an international standard that provides guidelines and best practices for improving data quality and creating enterprise master data (an authoritative version of the data most critical to your business). Governmental bodies and many worldwide companies—including Fortune 500 companies in the US—have used ISO 8000 to improve data quality and reduce costs.
Data Quality Maturity Model (DQMM)
The Data Quality Maturity Model (DQMM) is an umbrella name for a number of data quality frameworks that define different levels of data maturity, along with guidance on how to assess and improve your organization’s current level.
One example is ISACA’s CMMI, which most US software development contracts. It defines five levels of maturity—Initial, Managed, Defined, Quantitatively Managed, and Optimizing.
Choosing a data quality framework
Truth be told, most organizations these days shouldn’t bother with choosing an existing data quality framework unless it’s a business requirement—e.g., you do work for a government that makes adherence to the framework a condition of signing contracts.
Most data quality frameworks were created a decade or more ago, when the data world dealt with fewer data sources and less overall data. In today’s world, where data growth is exploding exponentially, most companies need a more flexible and scalable approach.
Defining your own data quality framework
That doesn’t mean you don’t need a data quality framework! Rather, we recommend defining your own based on the needs of your business. This includes:
- Defining which quality checks matter to your organization and individual teams.
- Determining where to test. (We recommend continuous data quality testing across all environments, including raw sources.)
- Establish a peer review process built on mechanisms such as pull requests.
- Repeating and iterating over this framework, adding new checks, procedures, and metrics.
Using the ADLC to create a workflow
The Analytics Development Lifecycle (ADLC) is a process to create a mature analytics workflow that builds data quality into each step of the data lifecycle and iterates over your data quality framework. The ADLC consists of six stages that you apply to every data change:
- Plan: Involving all stakeholders to define the business case for a data change, along with a data quality test plan and data quality metrics
- Develop: Enable multiple stakeholders to build data transformation and business logic using the languages they already know
- Test: Subject all code to a thorough code review and run unit, data, and integration tests in each environment
- Deploy: Use an automated CI/CD process to push well-scoped changes to production; enable rollback mechanisms to revert to the status quo if you detect issues with the change in production
- Operate and Observe: Catch errors before your stakeholders or customers do with continuous data quality monitoring
- Discover and Analyze: Enable data stakeholders to find and use high-quality data sets easily to build analytics solutions, such as BI dashboards, reports, and data-driven applications

dbt: Your data quality framework tool
Whether you adopt a data quality framework or create your own iteratively, your framework will only flourish if you have the right tools to implement it.
With dbt Cloud, you can bring your data quality framework from theory to reality and reliably deliver high-quality data to your business:
- Use testing and version control to validate assertions about your data and track code changes through all stages of deployment
- Use CI/CD pipelines to automate data transformation code deployments
- Spot and fix issues quickly using column-level lineage and embedded health status tiles in analytics tools
- Auto-generate documentation for all of your data transformation models
- Implement data governance in a scalable manner with dbt Mesh
- Deliver high-quality, tested metrics to stakeholders using the dbt Semantic Layer
For more details, read our deep dive on building a data quality framework with dbt Cloud. Or book a demo today to discuss how to bring a dbt Cloud-driven data quality framework to your business.
VS Code Extension
The free dbt VS Code extension is the best way to develop locally in dbt.



