The 5 essential data quality checks in analytics

Last edited on Oct 15, 2024
We’ve talked about the core data quality dimensions and how to think about them with intentionality. We’ve explained how to put those in a framework that is guided by your business. Let’s use this page to talk about the actual foundational data quality checks you should be running on your data, and how dbt Cloud can help make these tests simpler and automated.
We’ll cover the concepts of: uniqueness, non-nullness, acceptance, referential integrity, and freshness, and how these weave together in dbt to build a bedrock of data quality.
Uniqueness
There’s nothing quite like finding a duplicate primary key in a table, and the immediate shiver it sends down a data practitioner's spine. With a uniqueness test, you’re testing that all rows for a specific column are unique, keeping your data, your business users, and your spine happy.
You’ll most commonly test primary and surrogate keys for uniqueness in your data warehouse tables. Using some manual SQL, you’d probably write a little query like this every time you make an update to a table:
select
id
from your_table
group by id
having count(*) > 1Any ids that are non-unique will be returned with this query.
As much fun as it is to rewrite and execute this query any time there’s a change to your tables, there's a much faster and easier way to sniff out duplicates with dbt: the unique test. Using the uniqueness test, you add a unique test to any column you want in your dbt models:
models:
- name: orders
columns:
- name: id
tests:
- uniqueIn this example above, the id field will be checked for uniqueness every time you run your tests against your orders * table in dbt. Behind the scenes, dbt is compiling a test very similar to the original SQL above to run against your data warehouse.
Gone are the days of having count(*) > 1 strewn across your SQL worksheets—or even worse, missing a duplicate slipping into your data—in are the days of single lines of code-based, version-controlled tests that alert you when things are off.
Non-nullness
Non-null tests should check that specific column values are non-null. Some examples of these columns might be:
- Primary keys
- Signup dates
- Email addresses
- Order amounts
- …and any other column that if it was null or contained a missing value, would lead to incorrect metric calculations.
Similar to the unique test, you can define a not-null test in dbt with a single line of YAML:
models:
- name: orders
columns:
- name: id
tests:
- unique
- not_nullNow, the id field is checked for both uniqueness and non-nullness, like any primary key should be tested. This testing structure is particularly useful considering some modern data warehouses recognize primary keys, but don’t enforce them.
It’s important to note that not every column value needs to be non-null—there should be null values in your tables, so it's important to use this test wisely to avoid an onslaught of misleading test failures.
Accepted values
Data teams rarely have control over the quality of their source data—we’re the end receivers of backend databases, a variety of cloud data sources, and on the special occasion, the Google Sheet. But we do have control over the quality of our transformed data.
Data teams will transform raw data into meaningful business entities by cleaning, joining, and aggregating the data. During the transformation process, as dimensions and measures are updated and created, it’s important to check that column values meet your expectations.
For example, if you run a US-based ecommerce shop, you would expect the following to be true about your data:
- Order statuses should only ever really be
placed,shipped,delivered, orreturned - Orders can only have currencies in
USD
How would you check that these two statements are true in your orders table?
In a more ad hoc way, you could write some relatively simple queries…
select
order_id,
order_status
from orders
where order_status not in ('placed', 'shipped', 'delivered', ' returned')
select
order_id,
currency
from orders
where currency != 'USD'But writing these ad hoc queries over and over again doesn’t make sense as your data grows and changes over time.
Using dbt tests for accepted_values ,not_accepted_values, and accepted_range, you can easily define expectations for column values within a version-controlled YAML file, and have them raise errors when your data deviates from them.
The ad hoc queries from above would simply be replaced with a few lines of YAML:
models:
- name: orders
columns:
- name: order_status
tests:
- accepted_values:
values: ['placed', 'shipped', 'delivered', 'returned']
- name: currency
tests:
- accepted_values:
values: ['usd']Relationships and referential integrity
As you transform your raw data into meaningful models, your data will likely change format with new dimensions, measures, and joins. Each step of the transformation process creates room for the data to deviate from your expectations, which is why it’s important to test for relationships in your data models.
dbt is built on the foundation that data transformations should be modular, referencing each other to ultimately form a DAG—a lineage of your data. In dbt, whenever you make a new data transformation, what we call models, you can create a relationship test, which will check if a specified column in your new model has a valid mapping to an upstream model you specify.
This test is particularly useful if you're joining multiple models together, potentially introducing new rows, and changing the relationship between upstream and downstream models.
Freshness and recency
Let’s say it together: data is only useful to business users when the data is fresh and end users know the data is fresh. Stale data—data that is delayed from a source to your data warehouse or BI tool—holds up analyses, insights, and ultimately, decisions.
If you’ve been on the receiving end of the message from a stakeholder, “This dashboard hasn’t refreshed in over a day…what’s going on here?” you know that data freshness—and at its core—the stability of your data pipelines, is a challenging thing to monitor. Without tools to catch data freshness, your data team is always picked to chase in a never-ending game of duck duck go.
dbt supports the concept of source freshness and recency tests, both of which can help you unpack the freshness of your data in a more automated way:
- Source freshness: Using the source freshness capabilities in dbt, you can snapshot the “freshness” of your source data and receive warning and error messages when your data’s freshness falls below your expectations. Within the dbt Cloud UI, you can visually see the health of your data pipelines, and quickly be alerted when things go awry.
- Recency tests: With dbt, you can also create recency tests against specific timestamp columns to check that data is coming in at regular intervals that your team specifies. This is particularly useful for high-volume, event-driven data, such as web and email analytics.
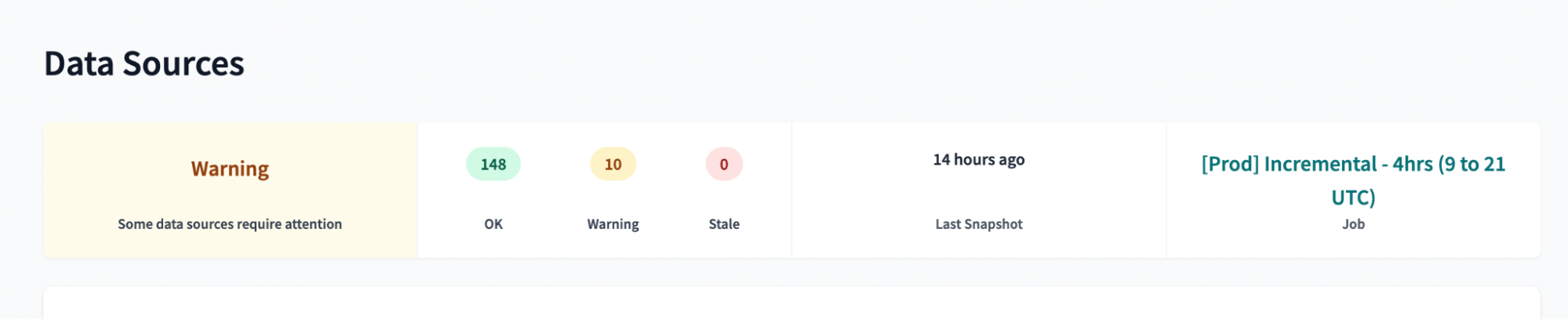
dbt additionally encourages the use of dashboard status tiles, which indicate the freshness and quality of data exposed in BI dashboards. Using these tiles, business users can automatically see if the data they’re looking at is accurate and fresh, all within the space they feel most comfortable.
Start with simplicity, work towards complexity
These five core data tests, as simple as they seem, can take you far. It’s amazing what happens when primary keys are actually unique, and data quality errors appear in a timely manner (and are discovered before a business stakeholder finds them 😉).
The tests we’ve outlined in this post is not the end-all of your data quality checks, but is a great place to start to build out a solid foundation for your data quality. Aided with a tool like dbt, that supports these generic tests, custom tests, and testing-specific packages, your data quality checks will be built for volume and complexity.
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




