
Challenge
Growing a data team as the demand for insights increases
Solution
Building a scalable data stack on Snowflake with dbt and Metaplane
Data has always played a critical role in driving Reforge’s business forward. Since day one, data was leveraged to understand important metrics like conversion rates and user engagement. As Reforge experienced rapid growth, their Head of Data, Daniel Wolchonok, wanted to make sure the data team kept up with this pace and made new metrics and insights available to the larger team.
"Now, we have a larger number of users and all the responsibilities of a SaaS business. We’re focused on metrics like new revenue, retained revenue, expansion, contraction, and churn. Our data needs have exploded and I expect that will only accelerate."
As the number of stakeholders relying on data skyrocketed, Dan and his team ran into scalability issues with their data warehouse performance and data engineering development practices.
The first data warehouse that Dan and his team built used Postgres, a popular open source OLTP database. When more teams started using data, queries routinely timed out for different stakeholders, making it harder for them to use data. After continually increasing to more powerful instances, Dan’s team felt like they were spending more time figuring out how to optimize their Postgres resource utilization rather than on what really mattered - bringing insights to the business.
Because Reforge didn’t previously have a dedicated data team, the data stack was developed by the engineering team using software engineering tools. The data models lived in the engineering team’s GitHub repo and were managed like a Ruby on Rails migration schema. Those systems worked well enough when the company was small, but they weren’t designed to scale with more complex data needs or a fast-growing team. Changes to data models in the core GitHub repo required submitting a pull request and waiting for engineering resources, so they’d take the quick and dirty route — making changes directly in the data warehouse. Of course, that meant there was no version control and sometimes those changes would break something downstream. The result was, as Wolchonok described it, “a bad experience for everybody.”
Building a scalable data stack on Snowflake with dbt and Metaplane
To Daniel Wolchonok and others at Reforge, it was clear that they needed to migrate to a scalable data stack. As a newly-formed and growing data team, they wanted a data stack built specifically to fit their needs, not one cobbled together from tools designed for software engineering.
"I want to empower each function with the best-of-breed tools, rather than one monolithic platform. There’s a wealth of tools out there that are really easy to stitch together.
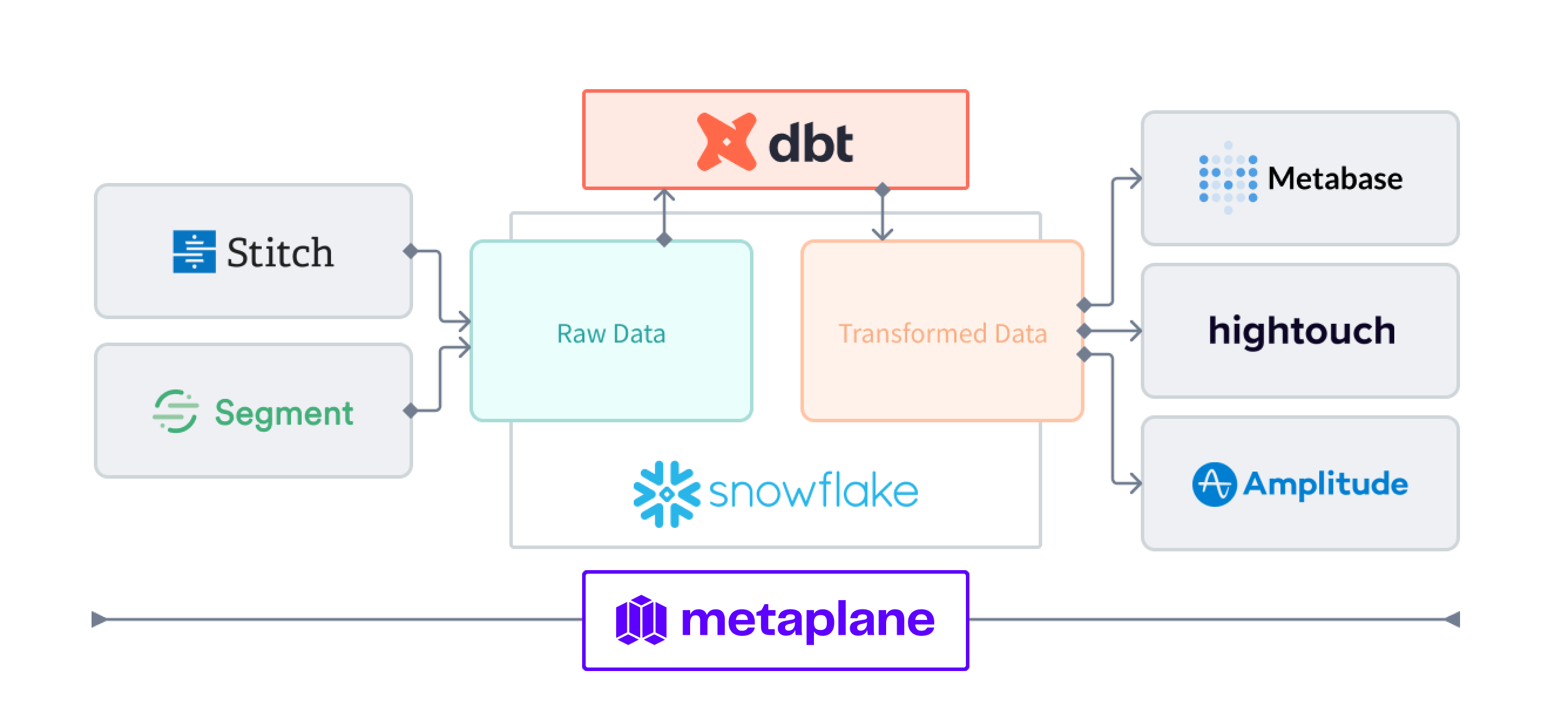
Reforge uses the best-of-breed tools to build a cutting-edge data platform that has helped power Reforge's use of data and rapid team growth.
Snowflake as an easy-to-use and scalable warehouse
Searching for a warehouse that is easy to get started with but could scale with their needs over time led Dan and his team to adopt Snowflake. Snowflake made it simple to set up development, staging, and production databases so that the data engineers could easily move data from Postgres to Snowflake. After finishing the migration, it was immediately obvious how the separation of storage and compute allowed the data team to focus on helping their teammates answer questions about the business, rather than worrying about provisioning resources or storage costs.
"It’s blown me away how quickly you go from getting by with some quick and dirty hacks to needing tools like Snowflake and dbt to break up and model datasets, manage testing, staging environments, deployment, all that stuff."
dbt Cloud for implementing data engineering best practices and showcasing the impact of data
Introducing dbt has been a milestone for Reforge because it encouraged data engineering best practices and made it easier to migrate to Snowflake. When Reforge switched to Snowflake, all they needed to do was swap the source and the transformations would run in their new Snowflake environments. Using dbt Cloud made it easier to build and maintain models over time, rather than data engineers making changes directly to the warehouse. When dbt became a part of Reforge’s CI/CD process, the data team felt empowered to own data modeling changes end to end.
With dbt, it also became easier for Reforge to showcase how data is used across the organization. Being able to see a visualization of the DAG and data lineage helped the team understand and share how data is being used.
"Engineers can see how the data they model in dbt becomes data that other teams are acting on. They can understand why we make certain requests. It makes a world of difference in their motivation and satisfaction."
Metaplane for Data Observability
Even before his work at Reforge, Dan was aware of the challenge of data monitoring and had experienced first-hand the chaos that can happen when data issues go unnoticed. Because the data team is growing and wears many hats, they found themselves responsible for managing thousands of objects in Snowflake. Before Metaplane, it wasn’t uncommon for them to find out tables had been missing weeks of data or the distribution of data had considerably drifted from source systems.
Dan and his team also found it hard to keep up with the fast pace of changes from upstream application databases. While they were at the center of data, they could be the last to find out about a data quality issue. Dan and his team were often digging around in the database looking for new tables and trying to understand changes just from column names and relationships. It was fine early in Reforge’s existence, but it was clearly not scalable.
Since implementing Metaplane, Dan and his team have been the first to know about data quality issues and changes in their data. When an engineer accidentally loads contacts to the wrong place, the data team finds out immediately, allowing them to fix the problem before it compounds or goes unnoticed for weeks. With Metaplane monitoring the data pipelines and reporting back, Reforge’s Head of Data has built a different reputation with his team - one of trust.
"Because of Metaplane, I spook people with how quickly I find data issues now. I know when events are created with crappy names, when there are new attributes, when someone puts a unique ID in a segment event. It helps me understand what's going on with our data and helps me catch issues that are painful to untangle."
Results
- Reforge now has a scalable data stack built on Snowflake, dbt, and Metaplane that can service the entire organization and scale with a rapidly growing team
- Using dbt and Snowflake, the data team was able to easily migrate from a poorly performing Postgres instance to a Snowflake environment where they didn’t need to constantly tune resources.
- After migrating to Snowflake, BI queries and dbt transformation queries that used to take hours now take minutes.
- Functions across the company have access to consistent and accurate data based on sophisticated data models built in dbt — everyone is working from the same set of data.
- Using Metaplane, the Reforge data team is the first to know about data quality issues. When issues occur, the team has a starting point to find the root cause and an understanding of the downstream impact to models and BI dashboards.
What's Next at Reforge
Focusing on what matters most for Reforge’s continued success: insights from data
As Reforge’s team grows, they can now focus on what is most important to the business - enabling the larger organization to ask questions and find insights in the data.
They no longer need to worry about tuning their warehouse to handle increased loads because Snowflake can handle any workload size. The data team now manages data models in a scalable way and can be confident changes aren’t being made directly to the warehouse. And, as the company grows, Dan can easily show how the data is being used. Lastly, the data team has preserved trust with the growing organization because they are the first to know about data quality issues and can broadcast issues they are fixing to the larger team.


