Introducing support for Python, dbt’s second language

last updated on Jun 24, 2025
This week we launched v1.3 of dbt Core, which includes support for Python models in dbt. The feature is available now in both dbt Core and dbt for users on supported data platforms: BigQuery, Databricks, and Snowflake.
Python models are:
.pyfiles in a dbt project (canonically in `models/`)returnand persist a data object (dataframe) in the data platform- “compiled” by dbt (canonically in
target/), then executed in the data platform
The goal of this addition is not to fundamentally change the way dbt works! We want to keep Python models looking and feeling like dbt models – that is, models transforming data.
Important clarification: Python models are not machine learning (ML) models. In SQL, dbt models represent a single SELECT statement that materializes an object in the data platform. This is true in dbt Python models, with a series of data transformation methods on dataframe objects returning a single data object to be persisted in the platform.
Check out for my colleague Doug’s post on the Developer Blog for more guidance on how this works and intended use.
When to turn to Python
Again, the goal of Python models is not to fundamentally change dbt – dbt users are already familiar with SQL, and we think that for the immediately foreseeable future the vast majority of models should continue to be in SQL. But we do want to offer practitioners a new tool in their belt for real problems that are better solved in Python.
Those problems include things like:
- Advanced statistical calculations
- Parsing and analyzing text inputs
- Complex operations on date and time
- Basic forecasting models
- Generating synthetic data
- Enrichment via metadata
- Feature engineering for machine learning
- Light machine learning workloads
- …
All of these scenarios can now be realistically tackled in dbt with a relatively small price in performance by using Python. And if you just prefer writing Python code over SQL? (Like the author of this blog!) You can now contribute to your organization’s dbt project alongside SQL-first practitioners.
Getting started with Python
First, ensure your dbt Core profile or dbt connection is set up properly to use Python models with your data platform. See the docs on specific data platforms for details.
Then create models/first_python_model.py in your IDE and write:
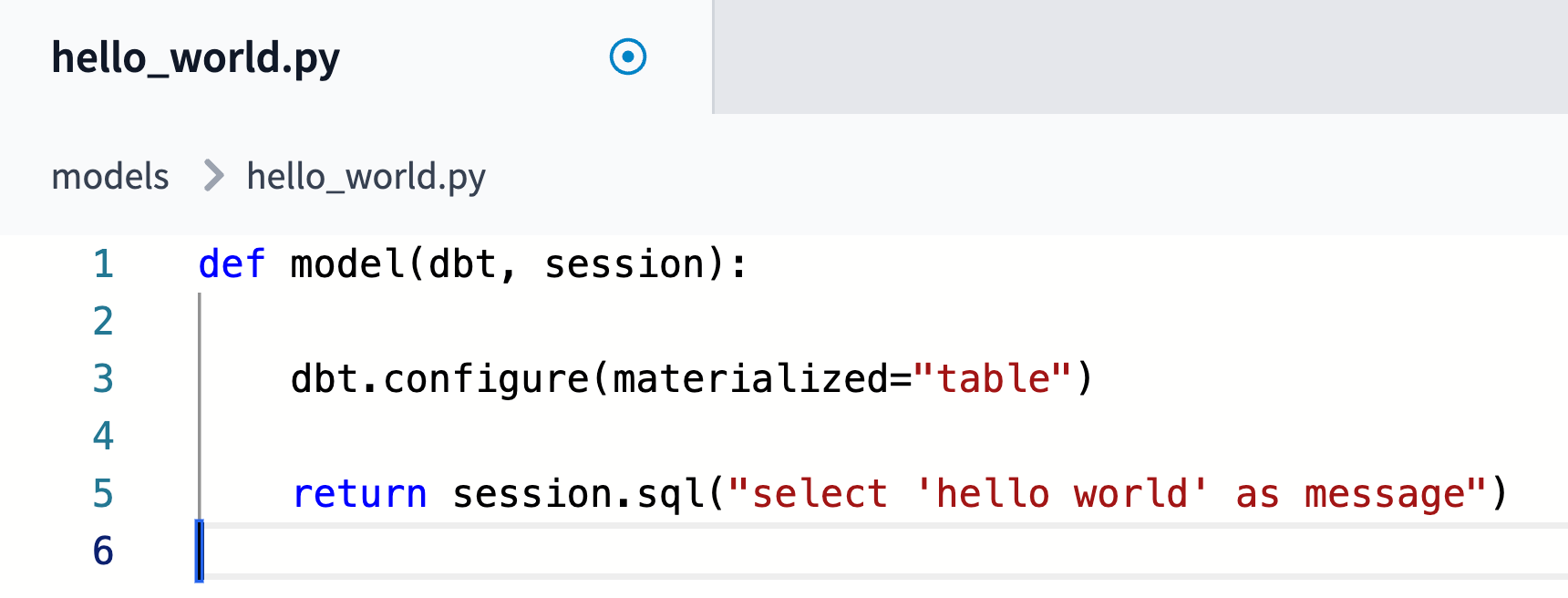
Run that model with dbt run -s first_python_model , and congrats!
You probably want to ref or source some data. A more typical dbt Python model would look like:
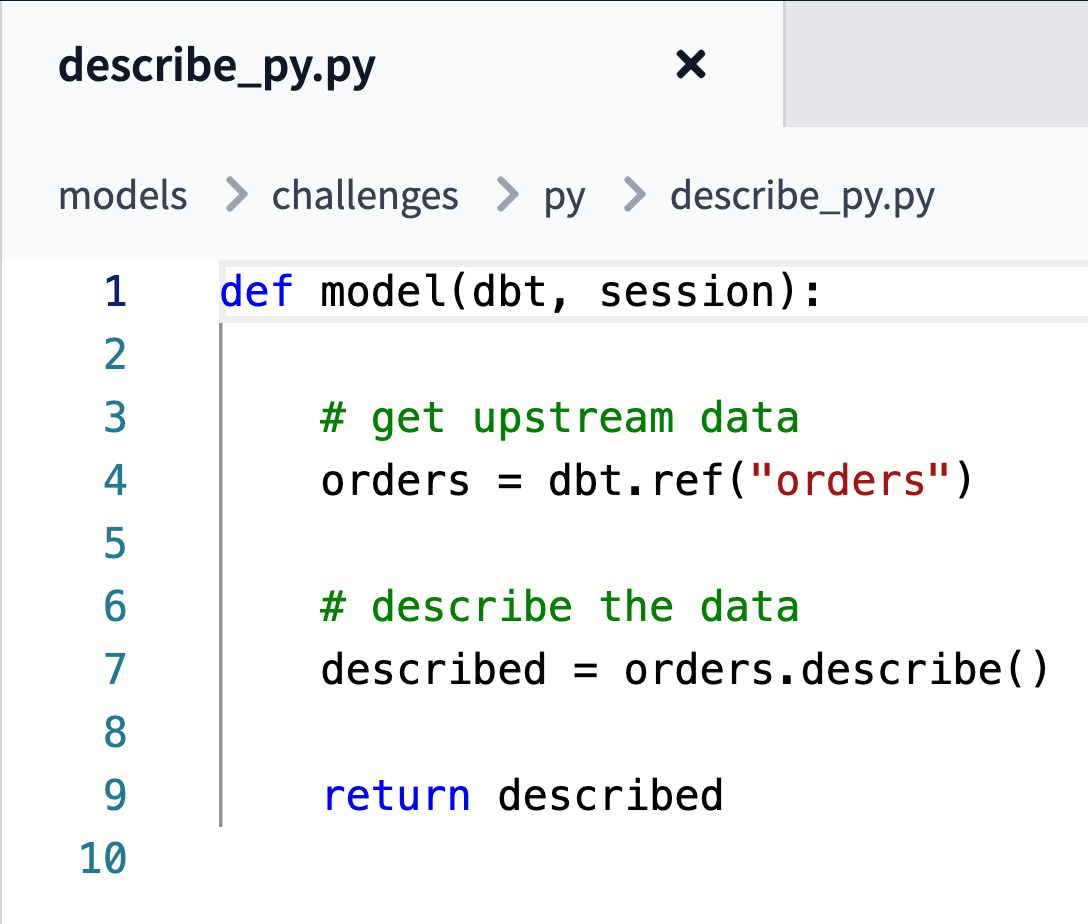
Things you can’t or shouldn’t do
dbt Python models in v1.3 have a narrow set of intended use, even as they open a broad set of possible use. We strongly encourage all but the most advanced users to stay within the bounds of intended use: data transformations in a dbt model.
Since all dbt transformation is pushed down to a data platform, you are naturally limited by what your data platform allows. For example, depending on your organization’s infrastructure choices, you may not be able to make external API requests. Snowpark, for instance, does not support external API requests by default in its current public preview state. Even if your platform does, you should also not import requests and build a dataframe from API requests to perform the EL part of your workload or trigger cloud services.
If you’re an advanced user who wants to help us push the boundaries of dbt, we’re interested to hear about your experiments! See how to give us feedback below, and let us know what you accomplish with Python.
The future for Python models in dbt
This is the first step on a multiyear journey for dbt into Python and a truly polyglot workflow. We do recognize that there is more work to be done to allow us to fully realize its potential. In our immediate future, we are focused on the ergonomics of the new functionality and on making it accessible on more adapters.
Below are some of the key additions we’re planning to make to Python functionality in dbt in the near future. While this isn’t meant to be a comprehensive roadmap, we will aim to address everything noted here in the next couple of dbt releases.
Ergonomics
We have a good sense of some of our top priorities for features related to ergonomics. These include:
- Code reuse across models
- Runtime/environment/package and compute management
- Testing authored natively in Python
- Using Python docstrings for docs
- Flexibility in usage patterns with product encouragement toward SWE best practices
We’ll continue to improve the user experience as we receive more feedback from the community.
Adapters
We are notably missing support for Redshift in our initial release, and we are currently studying how best to make that possible. More investigation is needed, but we intend to support Python models in all adapters dbt Labs maintains.
Beyond those adapters, we’re eager to work closely with the maintainers of any adapter that can support Python models. Let us know in GitHub or Slack if you’re interested in contributing to any!
Give us feedback!
You can help us prioritize the features we work on and engage with our open-source software via Slack, GitHub, or Discourse. We host weekly office hours – you can find details in the #beta-feedback-python-models channel in Slack.
Thanks for reading!
VS Code Extension
The free dbt VS Code extension is the best way to develop locally in dbt.





