Semantic Layer as the Data Interface for LLMs

Last edited on Oct 15, 2024
This post first appeared in The Analytics Engineering Roundup.
On November 14th, Juan Sequeda and the data.world team dropped a bombshell paper that validates the intuition held by many of us—layering structured Semantic Knowledge on top of your data leads to much stronger ability to correctly answer ad-hoc questions about your organizational data with Large Language Models.

At a high level, this paper does the following things:
- Creates a benchmark series of business questions with varying levels of complexity that might be asked of an analyst at an insurance company, based on a subset of a standardized dataset.
- Asks GPT-4 to generate queries to answer the questions by producing:
- a SQL query (given the database’s DDL as context)
- a SPARQL query (given the knowledge graph as context)
- Compares the results of both queries against a “gold” reference query. Responses are graded as correct if they return all necessary rows and columns.
The results are, to put it mildly, impressive.
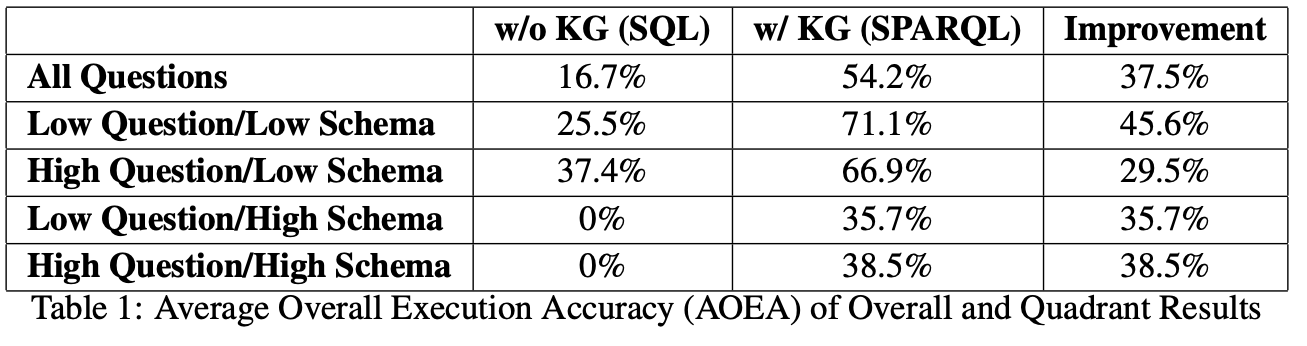
Using GPT-4 and zero-shot prompting, enterprise natural language questions over enterprise SQL databases achieved 16.7% accuracy. This accuracy increased to 54.2% when a Knowledge Graph representation of the SQL database was used, thus an accuracy improvement of 37.5 [percentage points].
There are three super interesting pieces to pull out of this:
- Overall, the system running on top of the knowledge graph was more than 3 times as likely to generate an accurate answer.
- For the easiest questions, accuracy was over 70% when combined with the knowledge graph - getting close to something you could reasonably use to generate first-pass answers to ad hoc questions in a real world environment.
- Knowledge graph encoding had a zero-to-one effect on the high schema complexity questions. 35% correct isn’t great, but it’s something, compared to the straight SQL queries being completely unable to answer the questions.
I really think that for those of us that are fascinated by the intersection of LLMs and organizational data, this paper is going to be a landmark event. I want to give the hugest amount of credit to the team that put this together: it was an intensive labor that combined deep technical and domain knowledge with a clear commitment to truth seeking. They even released an open-source repository where you can validate the results of the paper yourself. We owe a big debt of gratitude to the team that put this together.
You can experience this workflow today
Back in the heady days of February 2023, I wrote a post called Analytics Engineering Everywhere that theorized that the Semantic Layer would be a key interface for LLMs because each is strong where the other is weak. LLMs are fantastic for translating contextual questions and natural language into usable answers, but they struggle with hallucinations and consistency. I also shared some early work that the Community was doing around querying dbt Metrics via LLMs.
Since that article was published, two things have changed.
The first is that the dbt Semantic Layer, now powered by MetricFlow, is generally available to all dbt Cloud customers. Having a fully-featured Semantic Layer on top of your existing transformation workflows means anyone with a dbt project can implement the building blocks to start experimenting here.
The second is that there are now multiple companies working to help you do that in production. There is Delphi, who I linked to in my prior writeup. There’s Dot, a data driven chat interface. There’s Seek AI, who just achieved best in class SQL generation benchmarks. All three of these companies directly integrate with the dbt Semantic Layer.
To put it simply - if you are building on top of a modern data stack, you are building the foundation for an AI-powered analytics workflow to drive your business forward.
Putting it into practice
You had to know we were going to try this out ourselves right?
Myself and two members of the DX team, Jordan Stein and Joel Labes decided to see what it would look like for us to replicate this in dbt and share it with the Community. This involved two streams of work:
- Create a dbt project that translates the dataset from the paper into dbt models, with semantic models layered on top.
- Build a Hex notebook where we could validate the results from the benchmarking dataset and quantify the performance of natural language questions against the dbt Semantic Layer.
Before we talk about the results, I want to give a couple of caveats:
- We focused solely on questions in the “high question complexity / low schema complexity” subset, i.e. those which required aggregation and didn’t require excessive numbers of joins. These are the closest analogues to the type of questions we’d expect people to be answering in the dbt Semantic Layer.
- We did no data modeling in dbt in advance. The sample dataset is in 3NF, whereas dbt projects tend to follow dimensional, denormalized or data vault modelling patterns. Because of this, three of the questions in this cohort required more multi-hop joins than MetricFlow currently supports, so we weren’t able to replicate those questions. If we had lightly transformed the data, it’s quite likely we would have been able to match their results.
- We added relevant natural language documentation in the dbt project. To us, it’s a feature not a bug that you can use natural language to describe your data and have it accessible to the LLM as well. As an example, we found that adding this description moved several of the questions from being answered correctly 0% of the time to 100%.
So what were the results?
Very promising. If we look at the subset of eight questions which were addressable, we saw an 83% accuracy rate for natural language questions being answered via AI in the dbt Semantic Layer. This includes a number of questions which were correctly answered in 100% of attempts.
The full results, including the generated queries and their responses for every iteration, are available both on the GitHub repo and as a Google Sheet.

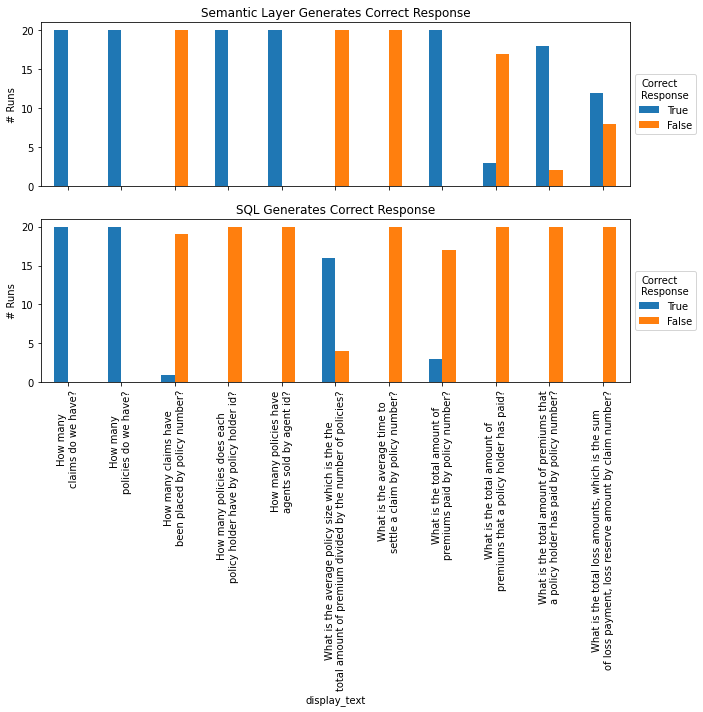
The questions attempted by the Semantic Layer with a 100% failure rate are the ones that required too many joins.
What this proves is that there is room, right now, to deploy these systems on top of your dbt project and have a subset of business questions answered to a high level of confidence.
Where to from here?
We are sharing this as an early experiment/proof of concept to show how LLMs can be deployed on top of the dbt Semantic Layer and bring trusted, accurate data into LLM based workflows. I’d love to see other attempts at replication, tests against the full question benchmark and the results of these questions when run within the tools above like Seek, Dot and Delphi. Our hope is that the dbt Community will spend time researching, validating, experimenting and building on top of this.
For analytics engineers who are curious what our role is in an LLM enabled world - I think this has given us a peek into the future. Doing this project was SO MUCH FUN. We still had to deeply understand the data and determine the best way to query it. We still had to use all of our analytics engineering tools and experience.
The analytics engineering skillset is a natural fit for creating the systems that will enable businesses to combine their enterprise data and LLM systems. Analytics engineering is at its heart about adding context and structure at the intersection of technical work and domain expertise in order to build a shared understanding of the world. Now, we’ve just got a powerful new tool in our toolbelt.
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




