
What is data transformation?
Data transformation is the process of taking raw data and making meaning out of it. It forms the foundation of analytics work and is one way data practitioners create tangible value for their companies.
What is an ELT (Extract, Load, Transform) workflow?
An ELT (Extract, Load, Transform) workflow is a data transformation process commonly used by data practitioners in data warehousing, analytics, AI, and customer-facing data products. In this workflow, data practitioners first extract data from data sources such as databases or applications. Then, they load the raw data into a data warehouse where, finally, the data is processed and transformed in the data warehouse.

In ETL, data loading into your data warehouse happens after transformation in order to keep network bandwidth transfer and storage to a minimum. The cloud and commodity storage enabled a shift to ELT, which supports loading all of your data into your data warehouse and then transforming it in place. This enables greater flexibility in modeling, as you can transform the same data in multiple ways to implement different use cases.
Why transform data using an ELT workflow?
Leveraging an ELT workflow streamlines the data transformation process and ensures standardization of your data at scale in a fast, flexible, and reliable manner. That helps data practitioners provide stakeholders with high-quality, analysis-ready datasets faster.
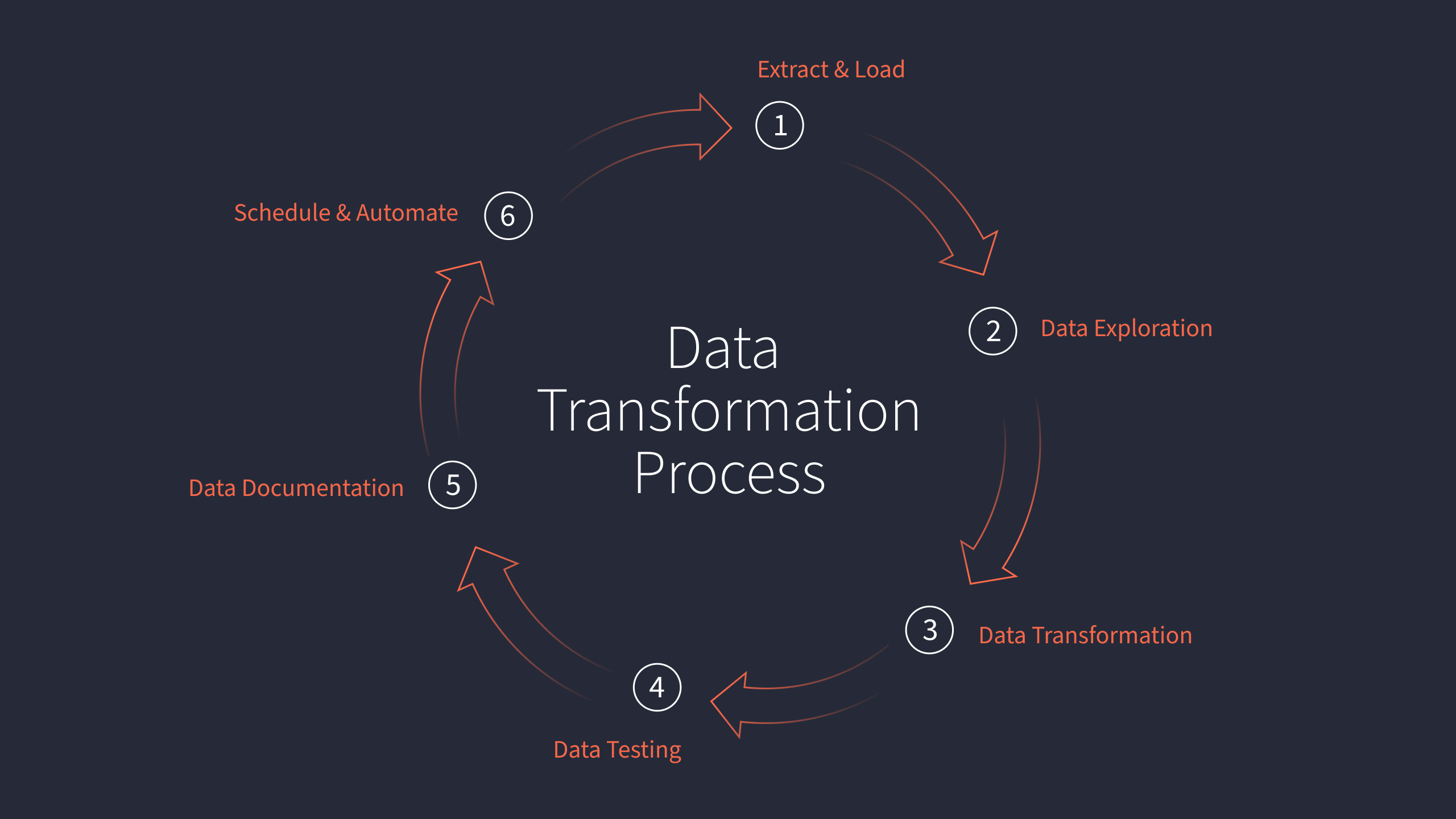
The 6 steps in an ELT workflow
We can break down the data transformation process into six generally-defined steps for an ELT workflow:
- Extraction and loading
- Exploration
- Transformation
- Testing
- Documentation
- Deployment
After these steps are taken, raw data takes a new form, as it now reflects your company’s needs and business logic.
Now let’s dive into each of the 6 steps of the data transformation process for a typical ELT workflow.
Step 1: Extract and load
If your team is following an ELT workflow, you’ll need to accomplish those extraction and loading steps before beginning your transformation work.
Extraction
In the extraction process, you extract data from multiple data sources related to your business. The data extracted is, for the most part, data that teams intend to use for analytics, data science, or AI work. Some examples of data sources are backend application databases, marketing platforms, and email and sales CRMs.
You would typically extract this data from systems by interacting with an Application Programming Interface (API) or command-line tools via custom scripts. You may also rely on the use of an open-source or Software as a Service (SaaS) ETL tool to remove some of the technical lift.
Loading
During the loading stage, you would load the extracted data into the target data warehouse. Some examples of modern data warehouses include Snowflake, Amazon Redshift, and Google BigQuery. Examples of other data storage platforms include data lakes such as Databricks’s Lakehouse.
Most SaaS applications that extract data from your data sources will also load it into your target data warehouse. Many teams employ tools such as FiveTran or AirByte for this. Custom or in-house extraction and load processes usually require strong data engineering and technical skills.
Step 2: Data exploration
Once you’ve loaded the raw data into your data warehouse, you need to understand it. Exploring your data helps you understand what you have, what might be missing, and whether anything looks malformatted or inconsistent. This enables you to create a data transformation plan, addressing any deficiencies that may impact overall data quality or produce errors for downstream consumers.
During this stage, you’ll find yourself:
- Looking at available table relationship diagrams (Entity-Relationship Diagrams, or ERDs) and join keys to understand how data joins itself together
- Identifying which columns are potentially missing values or have misleading column names
- Writing ad hoc queries to perform some light analysis or summary statistics on the data—how many rows are there? Are primary keys unique? Is there a primary key?
- Understanding how currency, timezone, and data types differ across data sources
There is no perfect recipe for exploring your raw data; do what feels necessary for your data sources. If you have high confidence in the accuracy and completeness of your raw data, this step may feel less laborious than if you question the integrity of your data. (Which, if you’re a data practitioner, is probably your natural inclination😉.)
Step 3: Data transformation
Up until now, you’ve loaded your raw data into your data warehouse, you’re familiar with how the data is structured, and you have a general plan for approaching it. Your data is finally ready for your modeling process to begin!
When you first looked at this data during the data exploration stage, you may have noticed a few things about it:
- Column names may or may not be clear
- Tables are not joined to other tables
- Timestamps may be in the incorrect timezone for your reporting
- JSON is abundant and may need unnesting
- Tables may be missing primary keys
Hence the need for transformation! During the actual transformation process, data from your data sources is either:
- Lightly transformed: Fields are cast correctly, timestamp fields’ timezones are made uniform, tables and fields are renamed appropriately, and more.
- Heavily transformed: Business logic is added, appropriate materializations are established, data is joined together, aggregates and metrics are created, etc.
Common ways to transform your data include leveraging technologies to write modular and version-controlled transformations using SQL and Python. Other solutions include writing custom SQL and Python scripts automated by a scheduler or utilizing stored procedures.
Step 4: Data testing
Your data is modeled now and feels generally right. But how are you confirming the quality of the transformed data? How do you ensure that the key metrics and data you expose to downstream users are trustworthy and reliable?
At this stage, you should conduct data testing that meets your organization’s standards. This may look like:
- Testing primary key for uniqueness and non-nullness
- Ensuring column values fall in an expected range
- Checking that model relations line up
- Any other relevant quality sanity checks
Step 5: Data documentation
It’s not just enough to transform your data. After all, other teams will likely want to consume what you create. Plus, new team members should have clear insight into what you’ve done so they can maintain and evolve what you’ve built.
To make your data transformations meaningful and useful for other data consumers, you should create and maintain robust documentation for your data. This is something you can - and should! - do throughout the process itself as you create your models and code your transformation logic.
We recommend you start by documenting the following during your transformation process:
- What is the primary purpose of the transformation or data model? What is the main reason this transformation was created? What important reports is it powering in your BI tool?
- Key columns that have business logic implemented in them or ambiguous column names
- Aggregates and metrics
Why document your data transformation process?
You should write documentation for data transformation processes so that those who weren’t involved in the original process can understand it. This makes your decision-making explicit so that consumers and maintainers don’t have to parse SQL code or comb through revision histories to divine your intentions. Instead of focusing on the how of a transformation for more technical users, you should focus on the why of a transformation for business users.
Well-written transformation documentation welcomes business users into the fold of analytics work. It’s a foundational way to ensure that data consumers feel comfortable and empowered to use the data your team works so hard to build.
Step 6: Schedule and automate
Your data transformations are created, tested, and documented—now it’s time to get them out into the world. At this stage, data practitioners will push these transformations to production. This is the process of running them in a production environment in the data warehouse. These production-ready tables are what analysts will query against for analysis and what a BI tool will read off of. These data transformations will need to be refreshed, or updated, on a cadence that meets your business needs using some type of scheduler or orchestrator.
Rinse and repeat!
After you build your foundational data transformations, your focus will likely shift to optimizing, governing, and democratizing the work. For each new data source, business problem, or entity needed, there will always be more data transformation work to get done.
A good data transformation process is simultaneously rigid and flexible. It establishes enough guardrails to make analytics work worthwhile and organized, with enough room to be interesting, challenging, and customized to your business.
The dbt approach to the data transformation process
In a data stack, data transformation plays a crucial role. Its purpose is to create clean, well modeled data sets to enable business users to extract meaningful insights from them. Using data transformation tools like dbt facilitates the transformation process and empowers your team to build and document data workflows collaboratively. This enhances efficiency and contributes to overall progress within the organization's data analytics capabilities.
Last modified on: Apr 02, 2025
2025 dbt Launch Showcase
Catch our Showcase launch replay to hear from our executives and product leaders about the latest features landing in dbt.
Set your organization up for success. Read the business case guide to accelerate time to value with dbt.





