Announcing dbt v1.3 and (soon) dbt-utils v1.0


We’ve just released dbt Core v1.3 (Edgar Allen Poe), which brings some very exciting new capabilities.
Much more on Python models, metrics, and the Semantic Layer will follow this week — but there's more wrapped into this release!
Custom node colors
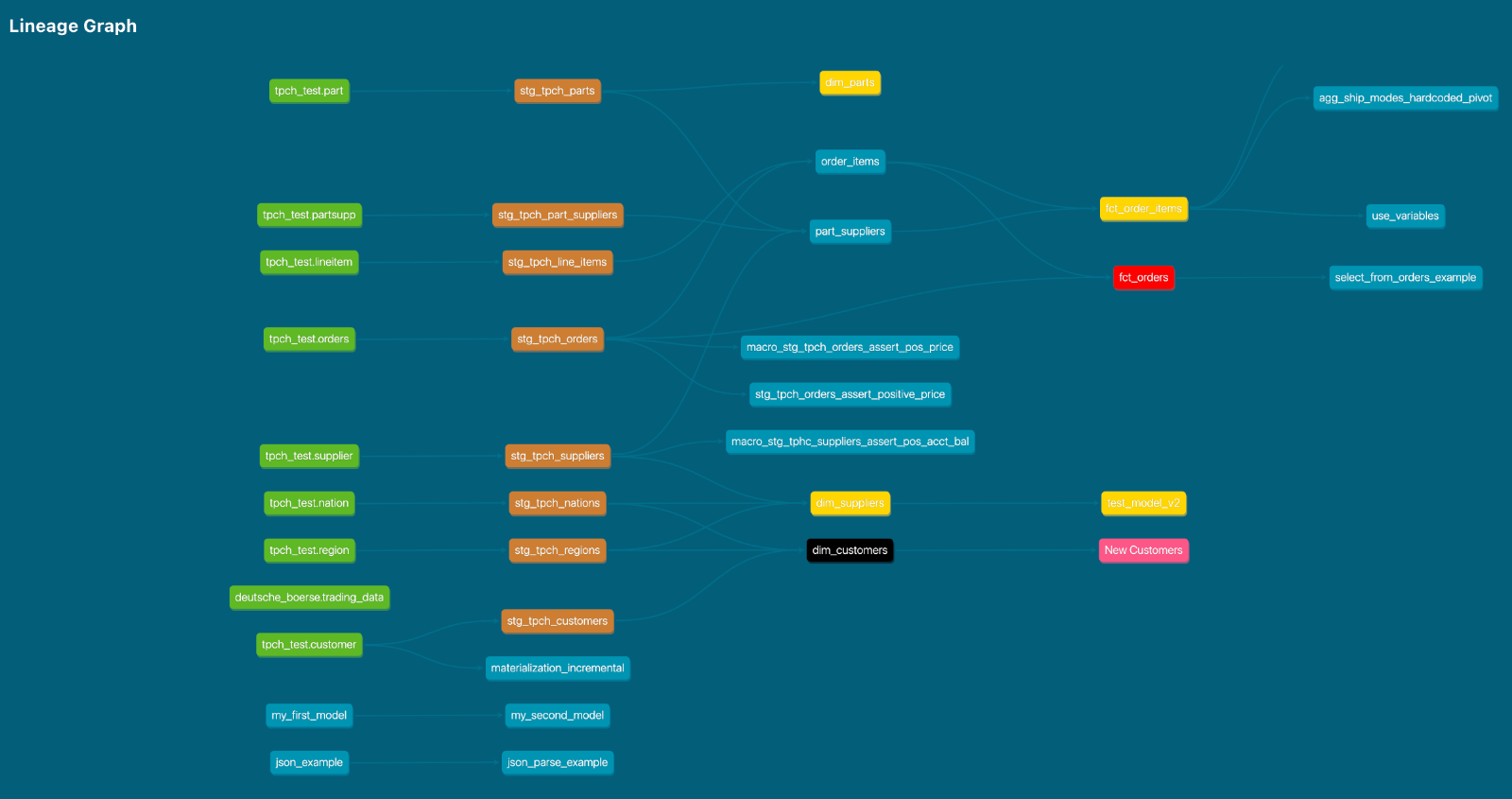
This release also includes a long-awaited feature: custom node colors in your dbt DAG. This was a community (well, colleague) contribution, spearheaded by some ambitious folks on the dbt Labs Solutions Architecture and Professional Services team. Thank you to Benoit, Sung, and Matt for making it happen!
Another way of putting it is: visuals matter. While this feature may seem only cosmetic to many, it makes a real difference for anyone who wants to help others understand their DAG at a glance — for example, present bronze, silver, and gold data layers in their appropriate metallic sheen.
Maturity
It’s been a year since we released dbt Core v1.0, and wow! We’ve seen the number of weekly active projects continue to grow—and the size of those projects continue to grow, too. Over 80% of projects have upgraded to using v1.0, with minimal hiccups along the way.
We are taking stock of what we need to do in the year ahead. On the docket:
- Make dbt-core easier to use and build around, starting with a new CLI that improves upon the current experience.
- Investigate how we can support dbt deployments with multiple projects, across business domains.
- Put our critical code in the right places, starting with a reassessment of where we house complex materialization logic and cross-database macro utilities.
Maturity in open source also means keeping track of our dependencies, especially the ones we share with other popular tools in the data ecosystem. Last year, Jinja released major-version 3, and we’ve upgraded to support it in dbt Core v1.3. We wanted to be careful about this—Jinja is bound up in so much custom user-space code—so we used the extended v1.3 beta period as our proving ground. Sorry to all the Airflow users who’ve had issues installing because of version conflicts (I understand Airflow added a new feature literally for this exact reason). We think Jinja-SQL is sticking around for a bit — and we’re happy to welcome Python! It’s not either or, it’s yes and.
For now, we’re excited to announce one more marker of maturity:
The future is now later this month: dbt utils is turning 1.0!
It’s time for dbt utils to tick over to 1.0 and commit to what was already unofficial policy: you can rely on dbt utils in the same way as you do dbt Core, with stable interfaces and consistent and intuitive naming.
dbt utils started as a handful of reusable functions to simplify Fishtown Analytics’ consulting work. Since those humble beginnings, it has grown into a key component of data transformation in some of the most complex analytics projects, from scrappy startups to Fortune 500 companies. Over a third of dbt projects install it every week, making it production-level software despite what its version number suggested.
To get there, we kicked off a GitHub Discussion in February about the future of dbt utils. It describes a much-loved package with a bit of an identity crisis:
- Should it be a training ground for experimental projects? 🙅♂️
- A cluster of macros that you shouldn’t use yourself but make other package vendors’ lives easier? 🙅♀️
- A group of essential tests and macros to make your life easier as a dbt user? ✅
What's new
First let’s have a look at the cool new things that come with this release:
- Many tests now support
group_by_columns— recognising that some data checks can only be expressed within a group, and that others become more precise when done by group. get_single_valueandsafe_dividemake tiny introspective queries and avoiding div0 errors that little bit easier.
dbt utils 1.0 is now a slimmed-down package that knows what it wants to be when it grows up. And what is that? From the same discussion:
Code in dbt utils should be useful even if there was only one database engine in the world.
This means that the cross-database macros that have built up over time needed to go. Adapters are the perfect place to implement this work, drastically reducing the need for “shim” packages like tsql-utils and spark-utils. As the number of data platforms providing adapters for dbt continues to grow, this became more and more important.
The other big change is a tidier and more consistent API. dbt utils evolved organically over time – a big piece of the magic of packages is that if you know how to make a dbt project, you know how to contribute – but that means that every macro has its own unique way of doing things. The requirement to commit to a consistent API for the next couple of years was a great forcing function to apply a series of long-promised deprecations. This does mean there’s some breaking changes — take a look at the changelog for the full details, but if your project is up to date you shouldn’t have many problems.
Thank you to everyone who has contributed to dbt utils, whether that’s by making a code contribution, opening an issue to describe a bug or feature, or just linking another community member to thepivotmacro when they ask for help to build their own. We’ve come a long way since the initial commit in 2017!
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




