
James Densmore has spent the last 10 years of his career working in data. In his current role at HubSpot, a customer experience platform used by over 78,000 companies, he’s the Director of Data Infrastructure. The biggest change he’s seen over the course of his career is how modern cloud warehouses have effectively solved some of the most challenging problems in data management.
HubSpot was an early adopter of Snowflake, a modern cloud warehouse platform. “I can’t emphasize this enough,” James said. “We don’t have a dedicated database admin or anything like that on the team because with Snowflake, we just don’t need one.” As an example, James points to dynamic scaling, “We often have times where we have a critical backfilling job. With Snowflake you can scale up for that one job, run the backfill, then scale right back down. Dynamic scaling with Snowflake is something that analysts can do on their own -- no waiting for a data engineer.”
Snowflake cloning is another previously sticky data management problem. “Even five years ago, data teams would have maybe one dev instance and one staging instance of their warehouse,” James said. “Snowflake is more like an ecosystem. You don’t even think of it as an instance because people can use cloning to spin up so many different databases.” This functionality means that anyone who knows SQL can quickly—and more importantly, safely!—work with data in the warehouse without breaking anything for someone else.
Snowflake’s data lake serves as the central storage for all of HubSpot’s data, “We’re pulling in data from our in-house databases, APIs, a lot of flat files sitting in S3, and Kafka streams. It all lands in our Snowflake data lake,” said James. Snowflake makes managing this data easy, but with that set of problems out of the way, HubSpot’s data team started to feel pressure in another part of the ELT stack–transformation.
Attempting to solve data transformation with Airflow
“At any data organization in any company, you typically have a lot of analysts and fewer technical resources. This always creates a blocker to productivity. Whenever an analyst needs a new column or data grain, they have to go to a data engineer to get it,” James said. “We’re an organization of over 3,500 people. If we need to hire a data engineer for every 2-3 analysts, that’s just not going to be cost effective. It doesn’t scale.”
The early attempt at solving this blocker was using Apache Airflow to build and deploy SQL models. The combination of Snowflake and Airflow meant that highly technical analysts could build data sets without going through data engineers, but the process opened up new problems:
- A messy code base: There was a lot of copy/pasting between models and the result was a code base that was getting harder to maintain. “Even a little bit of copy/pasting makes maintenance difficult. If you need to change one line of code in a model, you need to find all the places where that code was copy/pasted."
- Difficulty determining model dependencies: Analysts needed to manually define the dependencies of every query meaning that deploying new models was time consuming and stressful. “In some cases the data engineering team needed to write custom tooling to determine dependencies.” As the number of SQL queries deployed in Airflow grew, so did the cognitive load for analysts who needed to make sense of all that code.
- Challenging to troubleshoot: When deploying new models is difficult, analysts make an obvious choice–fewer models. “Analysts were incentivized to have fewer models because the more complex the DAG is in Airflow, the more times you have to copy/paste the code,” James said. When something inevitably broke, finding the issue was painful. “An analyst would look back at a query after a week or month later and have no idea what it was all about.”
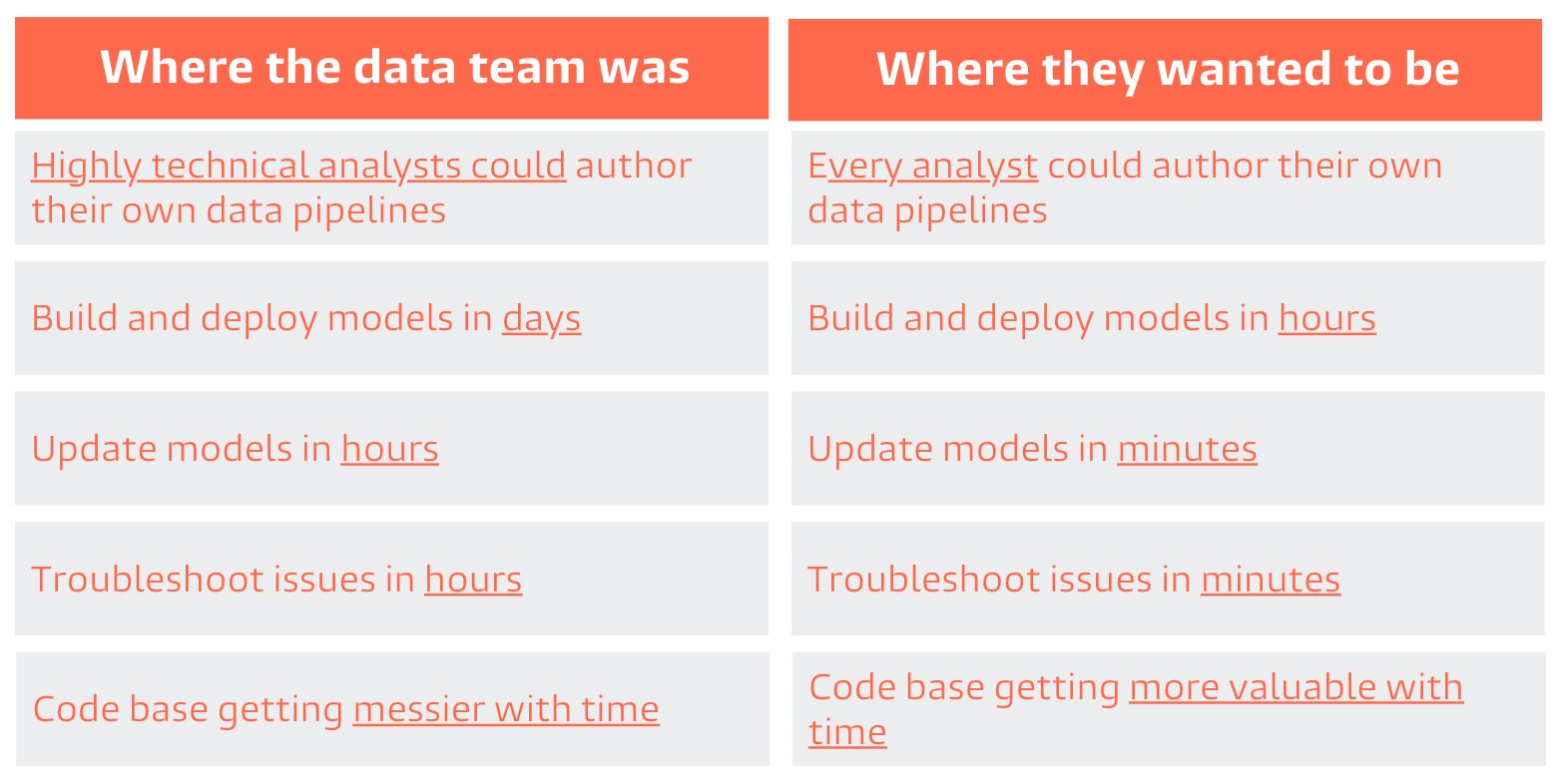
Even with best-in-class data warehousing, analytics velocity remained slow. HubSpot still had a huge gap between where they were and where they wanted to be in their journey toward empowering analysts.
Introducing dbt
“As an organization, we use the term ‘empowering’ a lot,” James said. “We have a highly autonomous company culture. We hire smart, trustworthy people and we want to make sure they have the tools they need to get their work done. That’s what we’re trying to do on our data team as well. We think empowering analysts to own their tools is the only way to build a productive analytics team at scale.”
Ultimately, it was the analyst community at HubSpot who discovered the secret to owning their own tooling–dbt. “We had some early adopters who advocated for dbt. They came to us and said, ‘Hey, I’m trying this out. I’d love to use it.’ And we said, ‘Great. Let’s do it.’” Two teams in particular were eager to start using dbt so the infrastructure team got things up and running.
These early adopters found that dbt empowered them in three important ways:
1. Empowered to do data modeling the right way: “We talk about guardrails vs. gates. We don't want to put up gates for people, but we do want to provide guardrails. Guardrails are best practices that allow people to move quickly and confidently.” dbt provided the technical infrastructure for analysts to own data transformation along with a set of best practices. “dbt makes it easier to do data modeling the right way, and harder to do it the wrong way.” One example James points to is incremental models. “In the past, most analysts on our team weren’t comfortable with incremental models. So they would either work with a data engineer or just do a full refresh every day.” In other words, analysts had a choice–wait for an engineer until you could do it the right way, or do it the faster but more expensive way. With dbt, an analyst can configure an incremental model using the is_incremental() macro. Because dbt provides clear guardrails around how to build an incremental model, analysts are more likely to use them.
2. Empowered to define model dependencies: With Airflow, defining model dependencies was limited to data engineers or the most technical analysts. In dbt, model dependencies are defined using a “ref” function to indicate when a model is “referencing” another model. dbt sees these references and automatically builds the DAG in the correct order. This intuitive approach to “layering” data models means any analyst who knows SQL is able to model data.
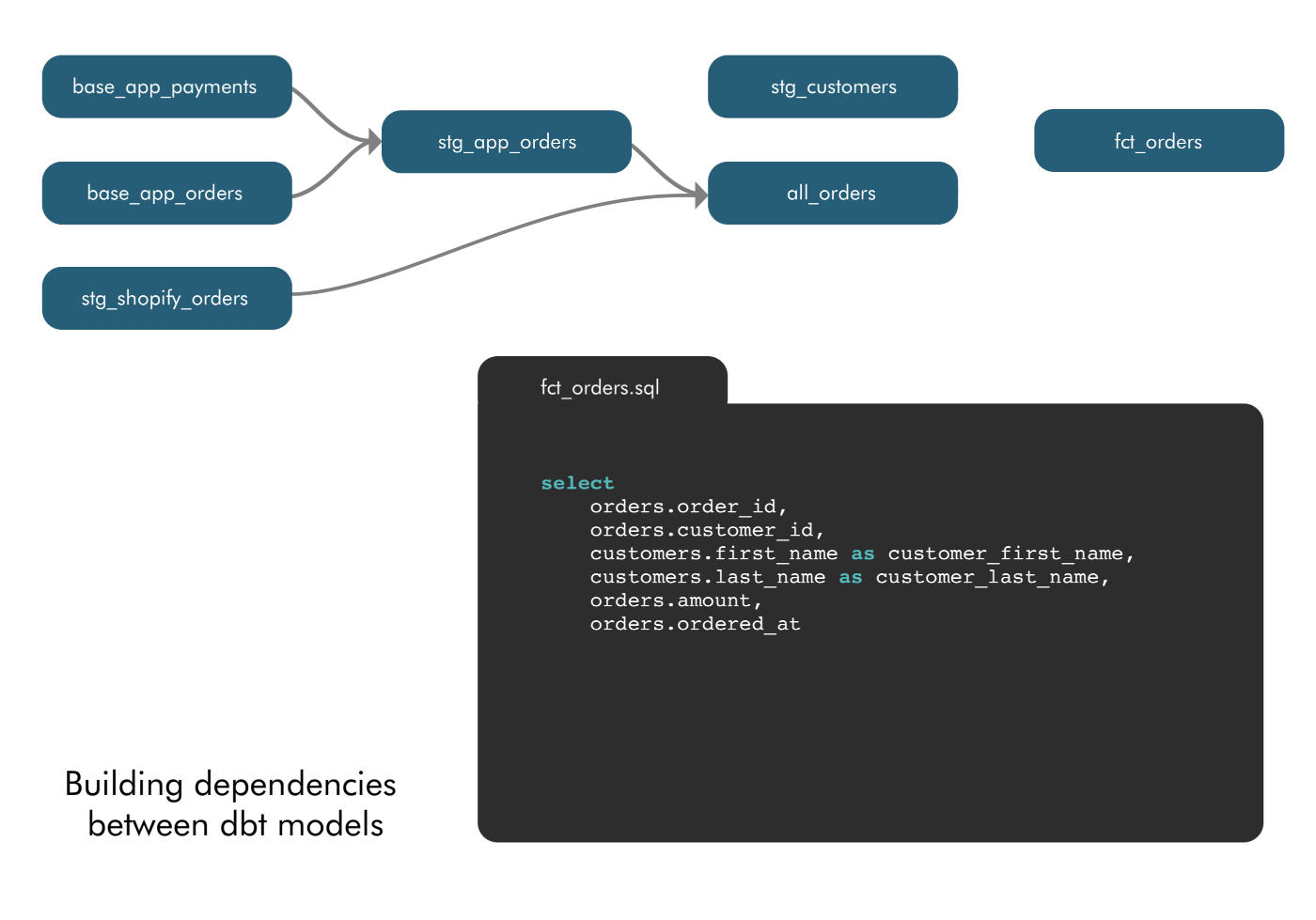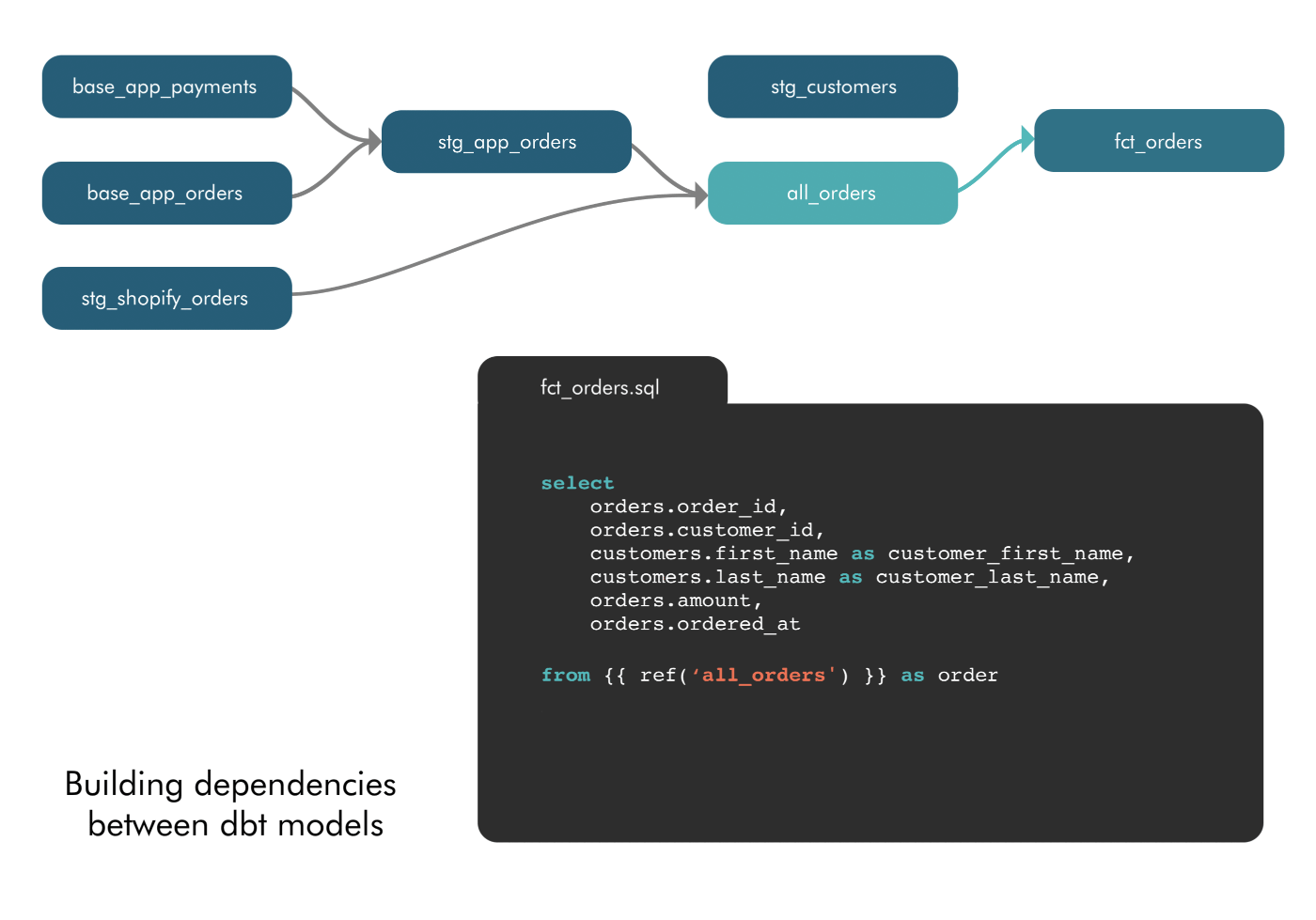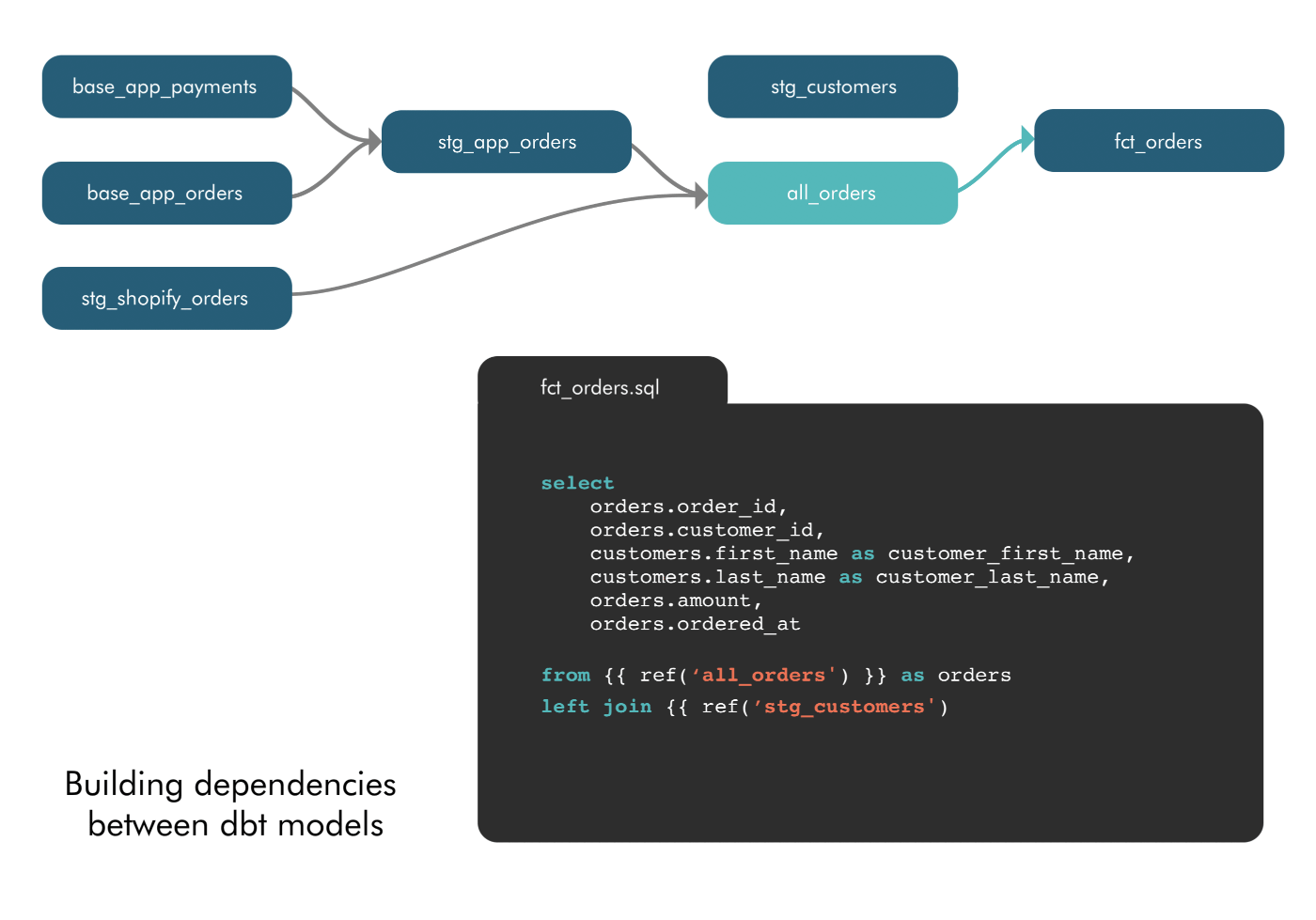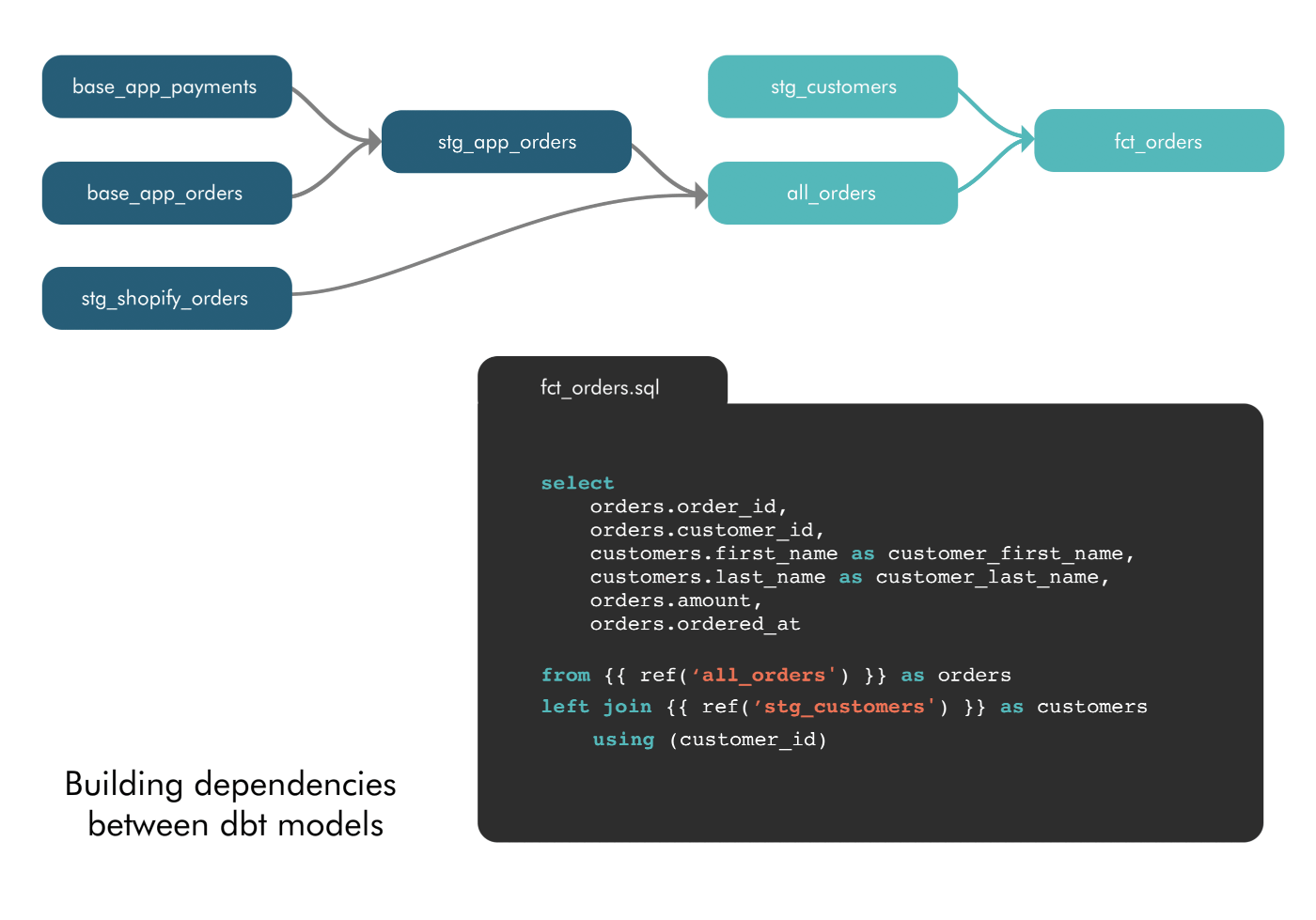
3. Empowered to update and troubleshoot models: The ease of referencing models ends up, “totally changing the way people write SQL,” James said. When dependencies are easy, analysts start to break their queries into smaller pieces. This follows one of the oldest best practices in software engineering–modularity. Modularity makes it easier to update and collaborate on models as well as troubleshoot issues. Well-named models are organized into schemas. So, if your sales pipeline numbers aren’t updating one morning, instead of sorting through 200 lines of SQL lumped into one query, you can jump into the sales schema, find the troublesome model, and make the fix.
Rolling out dbt to the analyst community at HubSpot
The data team at HubSpot is a hybrid model. James’ team acts as the centralized resource owning infrastructure, tooling, and some core data models. Analysts are largely decentralized, sitting within a given business function.
Today, two of HubSpot’s analyst teams have fully migrated to dbt. The first was HubSpot’s partner team. “HubSpot works with a lot of sales and marketing service providers. The classic example is a digital marketing agency who works with HubSpot to both sell the HubSpot product to a new small business and help them really get set up on HubSpot," said Ashley Sherwood, the Senior Data Analyst on HubSpot’s partner team. “Our partner channel is an important part of our business, which leads to us asking a lot of questions about the program.”
The question: “How many months since this partner’s last sale?” is straightforward. Things get complicated when you want to track changes to this answer over time. Using dbt, Ashley was able to fan out sales records by month, then group by partner. The resulting table showed one record per partner per month. With this data grain, the business users on the partner team were empowered to use Looker to do their own iterative exploration independent of analyst support.
This exploration resulted in a far more nuanced understanding of partner states such as who was active, dormant, or reactivated, and who was at risk of becoming dormant. “We'd been able to report on how many new sellers that we had, but never the attrition of sellers falling off. This led to us bringing a lot of pieces together for 2020 planning in a really exciting and new way.”
In addition to getting more analyst teams using dbt, James’ team is also migrating HubSpot’s testing infrastructure to dbt. “We have a legacy testing framework that works quite well for us. But being separate from dbt, it doesn't make a lot of sense,” James said. “We’re currently adopting the dbt testing framework so analysts will be able to write their own data quality tests as well.”
Finally, they want to help all of the analysts at HubSpot to flex their SQL muscles. “Most analysts learn SQL on a very small, simple SQL database. When you switch to a highly scalable, columnar database, it opens up new possibilities,” James said. “This is about education. We want to continue building an internal community around Snowflake and dbt to empower our analysts to get the most out of what these tools can do together."


