
Sinter just became dbt Cloud. Why the re-brand?
Tonight we put a permanent redirect from sinterdata.com to cloud.getdbt.com. Simultaneously, we launched a new design of the product: both a new user interface and some additional functionality.
I'll let Drew dig into the design & functionality changes in his post, but I wanted to take a minute to give some context on the rename. Why are we doing this? What are the implications for Sinter customers? How will this impact the broader dbt community?
To do this, I have to go back in time a bit. Bear with me.
Feeling around in the dark.
Drew and I started working on dbt and Fishtown Analytics full-time in July of 2016. We knew that dbt was extremely useful to us and to our clients, but we had really no idea if anyone else would see it that way. dbt was a pretty rough thing back then, but there were the seeds of something good.
We started to take it more seriously when our first real adopter, Casper, started using dbt in September of 2016. SeatGeek followed shortly thereafter in October. All the sudden, we had two real companies deploying dbt in production environments, and they were (by and large) very happy with it. This made us sit up and take notice.
With that seed of traction, Connor joined the team. Connor started building what became Sinter in his nights and weekends. It was this early traction that gave us the confidence to make this investment, so thanks to the folks at Casper and Seatgeek for taking a flier on us :)
We called the product "Sinter" because that word reflected exactly what we believed the product was for: bringing together a bunch of different data tools that, collectively, would solve problems for analysts. You have probably never heard the word sinter before (I hadn't), but here's the definition:
sinter: verb. make (a powdered material) coalesce into a solid or porous mass by heating it (and usually also compressing it) without liquefaction.
Take a bunch of stuff, smash it together, and turn it into something useful. We imagined Sinter hosting your Snowplow pipeline, scheduling your dbt jobs, hosting Presto, hosting Metabase... Sinter was going to be a one-stop-shop for analysts to solve their problems using hosted open source software, and dbt was going to be just one of many tools in that stack.
Getting stuck in a tractor beam.
There was actually no "pivot" away from this idea. It's not that one day we sat down and thought, you know what, that's a really bad idea, let's just focus on dbt. We just kept having new dbt users show up in Slack who loved the product and wanted more from it. We kept getting more consulting clients asking us to help them implement it. And the more we refined dbt, the more work we realized there was still to do.
Sinter was launched in January of 2017. For several months, we were the only users as we used it to deliver work for our consulting clients. This lack of uptake is hardly surprising given that we did essentially zero marketing for it.
But we found Sinter incredibly useful. We needed to continue to enhance it to make our own consulting work more effective, and we couldn't imagine not having it as a tool in our tool belt.
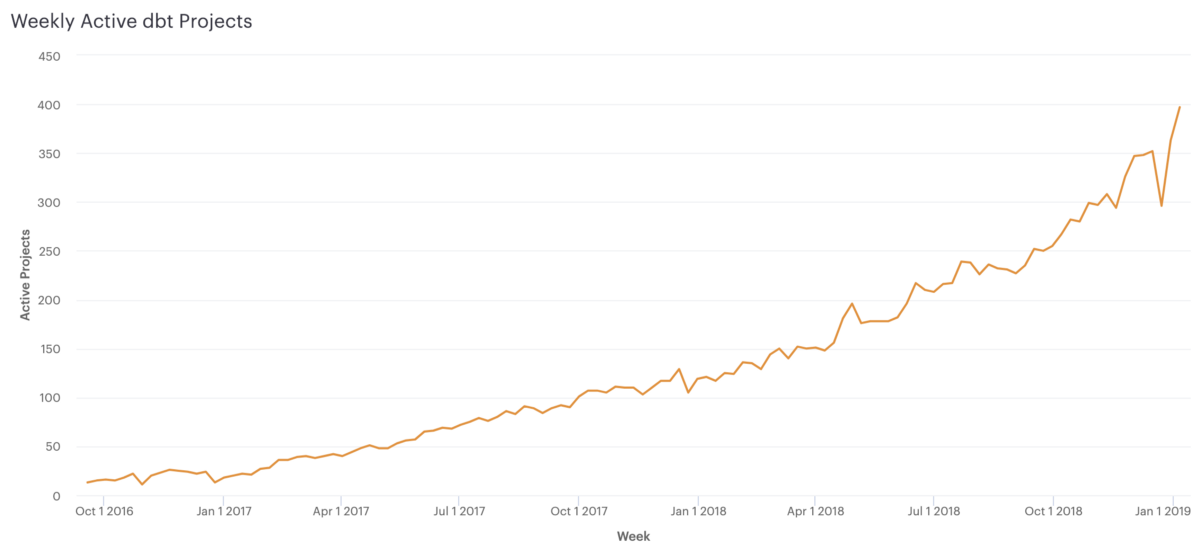
Over the course of 2017 and 2018, Sinter slowly, slowly gained a loyal user base. Today, over 100 companies use Sinter to schedule and monitor 15,000 dbt jobs a week, and growth closely mirrors the growth in active dbt projects:
We didn't decide that Sinter wouldn't host Metabase or Presto. We just never got around to doing that stuff---we were too busy building things we and our customers needed. In retrospect, this seems obvious, and I feel a little dumb saying it. But it was not at all clear that this would happen in late 2016 when v0.0.1 was coming together.
Course correcting.
By the second half of 2018, we had shelved the "do lots of things" idea in favor of focusing on dbt---we were just too excited about the potential of the product and the community. We also realized that that dbt and Sinter are two complementary parts of a single user experience. Our product roadmap has come to rely on having both a hosted, stateful, scalable application as well as a stateless, client-side compiler and runner. We need both of these parts to deliver the kinds of experiences we're excited about.
We realized that this change in plans necessitated a re-think. If dbt and Sinter were actually two parts of the same product, we wanted there to be no ambiguity about this fact. One time I was on a call and the person on the other end said "Hey, have you heard about Sinter? Someone built a product on top of dbt!" I had to say... "yeah, it was us!" That kind of market confusion had to be fixed.
We struggled with how to resolve the ambiguity for a long time, but eventually decided to call the two products dbt Core and dbt Cloud. dbt Core is the open source data transformation tool and dbt Cloud is the hosted service that sits behind it. The entire product is just dbt.
Sustainability and open source.
This decision is also about creating a sustainable business around dbt. We've actually discussed this publicly before---in a post that Drew wrote almost a year ago he specifically called out our goal to create an open core software business:
While dbt itself is open source, there are many opportunities to build commercial products in the dbt ecosystem. There are plenty of great companies that have similar business models: Elastic, HashiCorp, Github, MongoDB, and many more. There is even a term for this business model: open core. Today, we're focused on building dbt and its community; in the future we will also invest in building commercial products on top of it. Sinter is our first experiment in this vein.
Clarifying the branding around dbt Cloud will help with its user onboarding and word-of-mouth, both of which are critically important for a SaaS business. In that same post, Drew also said this of our commitment to open source:
We strongly believe that core technology infrastructure should be open source. Locking yourself into a closed-source ecosystem for core infrastructure is to leave yourself completely vulnerable to the whims of an outside party. In order for us to ask our users to make a huge investment to learn and implement dbt, we have to give our users the confidence that they control their own destinies.
Are these two goals---building an open source product and building a sustainable software business on top of it---in conflict with one another? The software community is abuzz these days about exactly this question. As one observer writes, open source is going through a mid-life crisis.
We believe it's vital for open source sponsors like Fishtown Analytics to find sustainable business models that allow them to continue to invest in the projects they sponsor. We also believe that they must remain committed to the long-term sustainability of their communities while they do so. Accordingly, we're not fans of licenses that limit the freedoms of users, such as the SSPL. We empathize with MongoDB's side of that argument, but that's not the path for us. Instead, our approach is simple:
- We will continue to invest in both dbt Core and dbt Cloud.
- We will make all stateless SQL compilation and running functionality open source under the Apache 2.0 license, forever, as a part of dbt core. This is the heart of the dbt user experience---modeling, testing, database adapters, package management, etc. You will always have a first-class experience using dbt even if you never pay us a dollar.
- We will continue building dbt Cloud as a proprietary product and make it available as both a SaaS and on-premise offering. dbt Cloud will enable use cases that are best facilitated via a cloud product.
We believe this approach will provide the best possible user experience, the most sustainability for the community, and the best chance of us building a sustainable software business. We do, however, acknowledge its challenges. The SFOSC, a newly founded organization devoted to sustainable open source communities, specifically calls out the challenge with this approach. From their site:
The difficulty with [open core] is that it can be hard to determine where the right line is for a given feature --- does it belong to the proprietary software, or the open core?
We've already found ourselves having these kinds of conversations. Most functionality has a clear home, but some does not. As we feel our way around in the dark on this issue, we'll use our deepest convictions as a guide:
We started Fishtown Analytics to change the way that analysts work. We believe that analytics is a subfield of software engineering, and that its tools and methodologies should mirror those used by software engineers.
We believe the core of an analyst's workflow should be accomplished using open source tools, as are the core parts of a software engineer's workflow today. This allows analysts control over their own careers --- they can choose their own tools, master them, and take them from job to job. They can participate in communities not for years but for decades. They can be nurtured by these communities and in turn give back.
Today, most products built for data analysts are 100% proprietary. We believe that's changing. In the future, analysts, like software engineers, will pay for software products for their convenience and efficiency, not out of lock-in and lack of choice.
Final thoughts.
Thanks to you, the community, for joining us on this journey. We continue to work on dbt because we're excited by how you've responded to it. dbt may be the fastest-growing and most disruptive product in the BI market today.
Drew, Connor, I, and everyone at Fishtown Analytics are excited about this rebrand. We believe it's going to help us build a better product, and eventually we believe it's going to help us grow a larger team around that product. We're committed to making that a win for every stakeholder.
See you in Slack :)
VS Code Extension
The free dbt VS Code extension is the best way to develop locally in dbt.






