

We're thrilled to announce the release of dbt version 0.9.0. This version of dbt has been in development for over three months, and we have quite a bit to show for it! Read on to learn about what you can do with this new functionality including pivoting out columns and unioning incongruent tables.
A programming environment for SQL
SQL is a fantastic language for describing data transformations, but it comes with a key limitation: SQL queries can't automatically be built from the results of other SQL queries. Problems like these have historically been solved with Python scripts or an array of other brittle solutions.
These ad-hoc solutions frequently belong to the category of "things that work really well until they don't." Changing table schemas, data types, or business logic can all silently break these out-of-band database transformations. Fortunately, dbt 0.9.0 provides a way to define many of these dynamic transformations directly in your dbt project. Further, they can be tested, versioned, and monitored along with the rest of your analytical code.
The goal of this release of dbt is to empower analysts to build, test, and deploy complex multi-step SQL transformations with ease. To this end, dbt 0.9.0 ships with a new construct to solve problems that have historically required a non-SQL runtime: the statement.
What are statements?
dbt statements are SQL queries that hit the database and return results to your Jinja context. Here's an example of a statement which gets all of the states from a users table.
While the sql here should look pretty familiar to dbt users, the statement block is brand new. Any sql inside of this block will be run against the database and the resulting dataset will be saved into the Jinja context. The first argument to the statement function is a name used to reference this dataset. Above, we're using the name states. The contents of the states variable can be fetched using the load_result function (shown below).
-- Load the results of our statement and select the first column
{%- set states = load_result('states')['data'] | map(attribute=0)-%}
select
*,
-- Loop over each state
{% for state in states | list -%}
case
when state = '{{ state }}' then 1
else 0
end as "is_{{ state }}"
{% if not loop.last %} , {% endif %}
{% endfor %}
from {{ ref('users') }}Running this model results in:
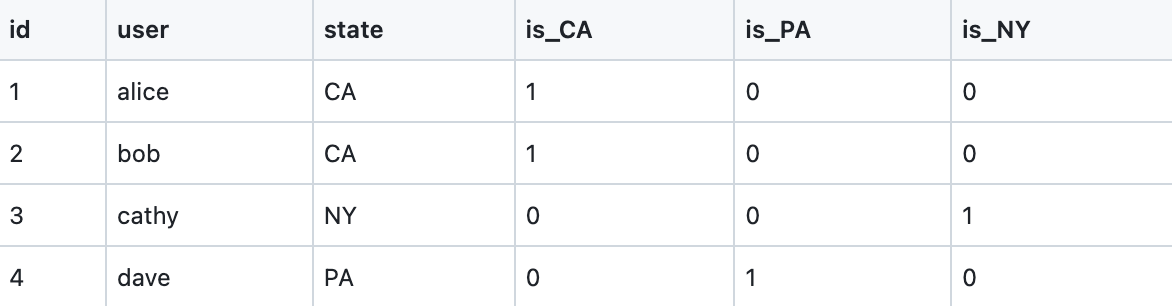
And just like that, we've written code to dynamically pivot out row values into columns. This code is specific to the state column of a users model, but we can easily encode this design pattern into a macro, then package it up for easy distribution. You can check out the resulting get_column_values macro here for use in your own dbt project.
Example: Outer Union
The SQL-standard union operator is used to combine datasets which share a common schema. Unfortunately, quirks in raw data frequently make this task more onerous than it should be. Frequently, tables share mostly identical schemas, with a couple of oddball columns which only exist in one table or the other.
Here's a simple example of two orders tables for the US and UK regions of an Ecommerce company. Note that the UK region has a returned_at column, while the US region does not.

To union these two tables, a fake returned_at column can be created in the ecom_us.orders subquery so that the resulting schemas match:
select
id,
user_id,
price,
null::timestamp as returned_at -- this column doesn't exist!
from ecom_us.orders
union all
select
id,
user_id,
price,
returned_at
from ecom_uk.ordersThis strategy works really well when only one or two columns are missing from both tables. Now, imagine that instead of just two tables you have a dozen, and instead of just one oddball column, there are 50 differing columns scattered across all 12 tables. Doing this by hand is not fun.
dbt statements are perfect to write this type of query dynamically. By querying database system tables, we can find the list of columns for each table in the union. Then, we can find the superset of these columns and build a complete union statement, filling in non-existing columns appropriately with null values.
You can find the full code for this "outer union" macro here. Below, you can see the source code for a dbt model which uses this macro as well as the resulting compiled SQL.
{% set orders_tables = [
ref('orders_uk'),
ref('orders_us')]
%}
{{ union_tables(orders_tables) }}The source code above is compiled to SQL that looks like this:
select
'analytics.uk_orders'::text as _dbt_source_table,
"id"::integer as "id",
"user_id"::character varying(255) as "user_id",
"price"::character varying(255) as "price",
"returned_at"::timestamp without time zone as "returned_at"
from analytics.uk_orders
union all
select
'analytics.us_orders'::text as _dbt_source_table,
"id"::integer as "id",
"user_id"::character varying(255) as "user_id",
"price"::character varying(255) as "price",
null::timestamp without time zone as "returned_at"
from analytics.us_ordersWhich, when run, creates a table that looks like this:
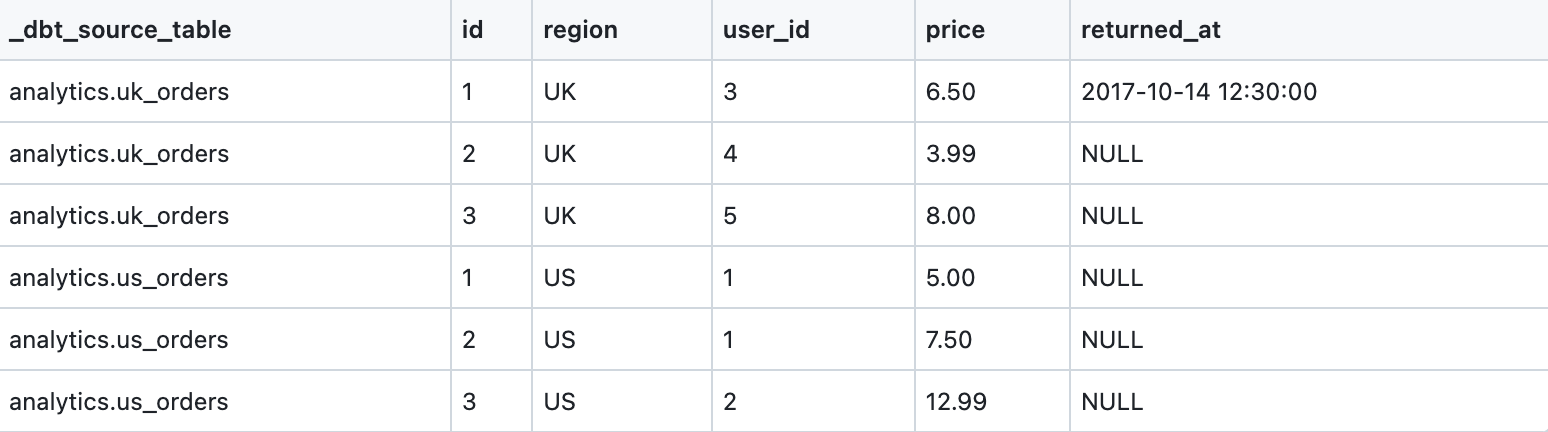
What else can you build?
These are just a couple of examples of the powerful and exciting new functionality made possible by dbt 0.9.0. In the past few months we've played around with building date-partitioned tables in BigQuery, automatic table compression for Redshift, and more. And we're sure we've just scratched the surface.
To check out some more examples, take a look at the dbt-utils and Redshift dbt packages. We always welcome new contributions, and we'd love to hear from you if you're interested in open-sourcing a macro that you've built!
You can find instructions on how to upgrade here, and be sure to swing by our Slack channel if you haven't already.
Published on: Oct 25, 2017
2025 dbt Launch Showcase
Catch our Showcase launch replay to hear from our executives and product leaders about the latest features landing in dbt.
Set your organization up for success. Read the business case guide to accelerate time to value with dbt.





