
It's a truth universally acknowledged that for every action there is an equal and opposite reaction on Twitter.
If, like me, you've been hanging out on data Twitter recently, you might have sensed that there is something in the air. It's not quite a whisper anymore, nor is it yet a roar --- more a persistent hum of an industry abuzz with a question of self-identity. We are analytics engineers... but what does that mean, exactly?
Naming things is hard
In the past two years since the term entered our vernacular, the number of open roles seeking Analytics Engineers has grown nearly exponentially:
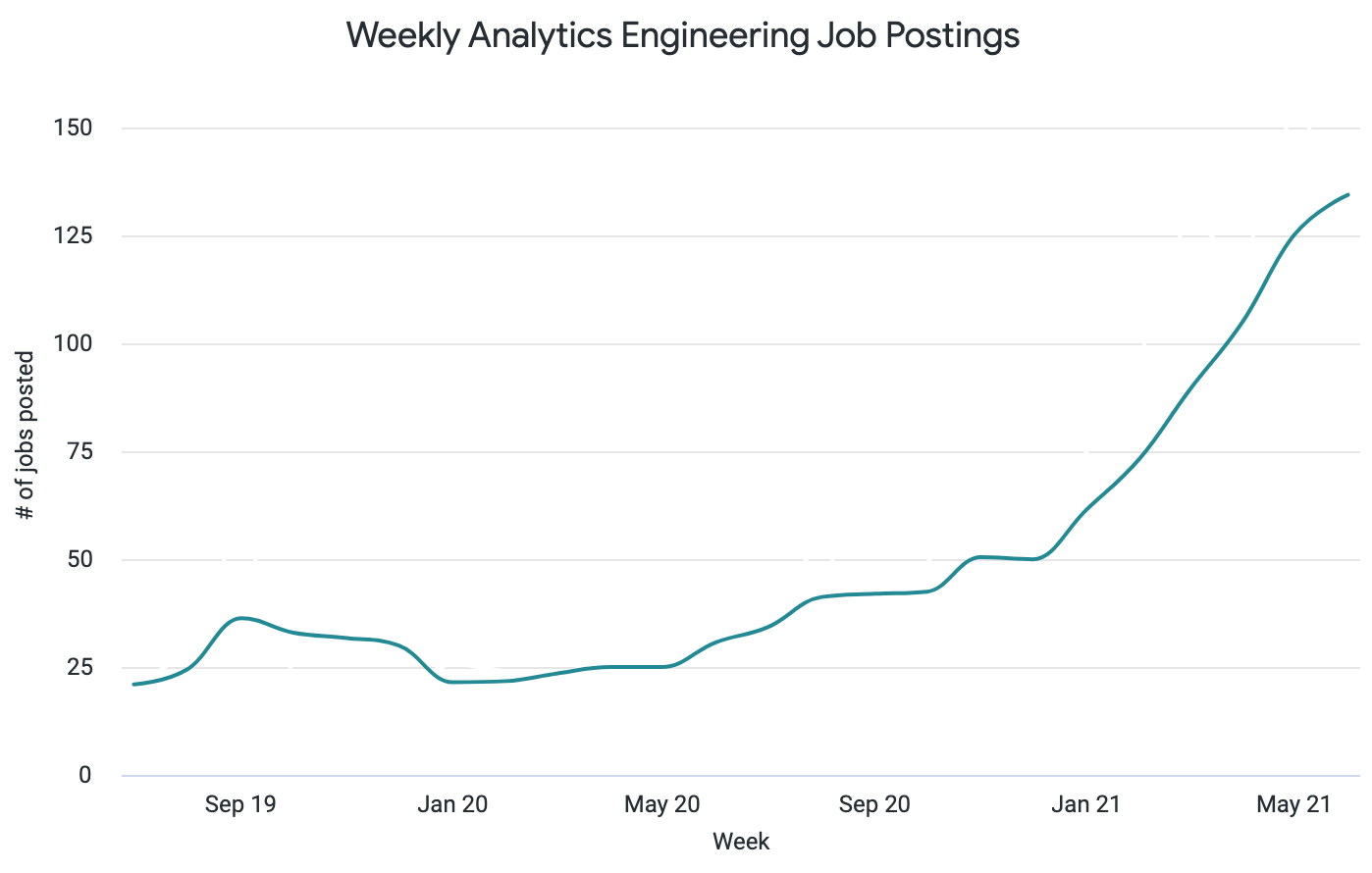
This role has been alive long enough that we now develop complex career ladders and chew on the nuances of when to employ a data engineer, an analyst, an analytics engineer, a machine learning engineer, a data scientist, an operations analyst...
Organizations are going through a similar epistemological shift. Adopting a modern data stack goes hand in hand with some serious rethinking of the role of data humans in an organization (because sociotechnical systems yo). Businesses are experimenting with different models of organizing data teams. These models all in some way reflect the diversity of business areas where data is becoming a critical part of the conversation. A tell tale sign of this happening: teams adding the word 'Analytics' behind a growing list of business functions like Finance, Product, Marketing, Engineering, Operations, Sales, Support...
The future still feels very much unwritten, but the conversations we are having today will be critical for the shape of our industry tomorrow. The first critical conversation we need to have is about reclaiming and redefining the labels we use to describe ourselves -- instead of letting those labels define us.
Analytics vs Engineering: the false dichotomy
Words matter. Adding the word Engineer to the word Analyst nearly two years ago took the data industry by storm --- here are the people who straddle the lines between analytics and data engineering, who simultaneously have enough business context and experience with data tools to design reusable solutions, abstract away the rote work, and allow the business to focus on and trust in the insights within their data.
And yet both the words 'Analyst' and 'Engineer' carry with them a ton of baggage that the term Analytics Engineer both uses as a launching point and gets inevitably mired in. The inherent tension in the term invites questions like:
- Does Analytics Engineering replace Analytics (or something else)?
- Is it a new role in addition to those that already exist?
- If yes, what does that mean for how we organize ourselves?
Regardless of how one answers those questions (and the answers so far vary!), the term also traps us in having to constantly re-establish the 'technical' nature of the role to the rest of the business... and to ourselves:
There is no such thing as a "non-technical" data analyst. Your colleagues spend their days translating business logic into code. That code might be Python, LookML, SQL, or a wildly complex Excel formula (Yes, you can write code in Excel). Building a marketing attribution model, forecasting, and calculating Monthly Recurring Revenue is all quite technical. Your analysts very likely have a far better grasp on the inner workings of the business. That's technical knowledge too! - Emilie Schario
Down one path, analytics engineering becomes the barrier between engineering and analytics. Rather than needing to be an impossible combination of statistician, developer, and business expert, analysts can simply be great critical thinkers.[...] With the help and support of analytics engineers, analysts can learn the technical skills they need (just as I did at Yammer), and focus on being the curious puzzle solvers they are. - Benn Stancil
Analytics is engineering.
Success in modern software engineering isn't measured by technical complexity but by clarity, reliability, agility and impact --- it is a collaborative practice, grounded in an ecosystem of open tools that enable automating the rote mechanics and focusing on the higher order problems. The term engineering itself is derived from the Latin ingenium , meaning "cleverness" and ingeniare , meaning "to contrive, devise".
Similarly, good analytics isn't measured by the complexity of the methodology, but by the impact of the insight. Analytics is ingenuity. It is finding something novel, and saying --- "Oh, now that's interesting!" -- and then turning it into a meaningful abstraction to help others see what we see.
So let's not focus on arguing what is 'technical' but on collaborating to abstract the automatable. Ingenuity is asking ourselves "How can we make something easier for ourselves in the future, and many others in the process?". Ingenuity is connecting disparate systems, enabling them to work together, and creating a whole that is greater than the sum of its parts.
It's time for labels that empower and not other.
We need a new metaphor, one that reflects this fundamental insight: the practice of analytics engineering is more than the sum of both analytics and engineering.
3 reasons why the future is purple
A member of our community (hi Stu 👋) shared a metaphor with me recently that didn't just pull an insight deep out of my subconscious, it hit me in the face with it 🤜 🤤.
This metaphor paints a world where humans with a deep understanding of business context in a particular domain are called red people ❤️. And humans with a breadth of technical expertise are called blue people 💙. Purple people 💜 are the people in between --- they have a little bit of both that enables them to translate between red and blue:

What makes this metaphor so powerful (aside from planting this Sheb Wooley earworm in your brain, you're welcome) is that it affords us the ability to talk about the work we do --- no, the ability to talk about who we are --- unchained from the societal habitus we occupy.
In the rest of this article, I'll be using this metaphor to describe the 3 fundamental reasons why I think the future of Analytics Engineering is purple and what this means for the evolving modern data stack.
1. Purple people are serial generalists
Becoming purple involves spending time in different spaces --- some red, some blue --- and building experience in different domains, tools and tech stacks.
The concept of a data generalist is not a new one. T-shaped people is a popular metaphor for the depth of business domain expertise and breadth of technical expertise that typically characterizes a data scientist. What separates "purple people" from the T-shaped generalist is a lack of preconceived notions about someone's specialization. In fact, purple people prefer not to specialize at all --- they remain focused on the business problem at hand, and using the right tool for the right job.
Purple people play the role that is required of them in the moment and enjoy doing so. It's not a lack of focus --- it's an organizational superpower. Moving from problem to problem enables purple people to build bridges between disparate entities across the business, connecting technology and people in new and productive ways. Sometimes this looks like operations, sometimes embedded analytics, and sometimes straight up organizational plumbing.
2. Purple teams create shared organizational context. This benefits everyone.
Purple teams have the power to bring together siloed tools and siloed practitioners. They create a common language across the business that enables working collectively and at a higher abstraction.
A common career path for purple people can look like jumping around between what are on the surface very different roles --- some flavor of analytics, data science, data engineering, operations, people management (and many more!). Each iteration builds a new and different kind of empathy for the problems at hand. Helping purple people grow in their careers is therefore less about gaining a predefined set of skills and more about growing the scope of their impact on the business and on others around them.
In the coming years we will see more and more examples of purple people. You will know them by titles like "Analytics Engineer", "Operations Analyst"... or some combination of business function + "Analytics/Analyst" that doesn't yet exist but soon will. And this is a Good Thing ™️ --- organizations need more and different kinds of purple people.
3. Purple teams are diverse teams
By nature of their diverse interests and non traditional career pathways, purple people come with a huge diversity of social and educational backgrounds. Each purple person also has their own superpower: some folks are strong tech leads, others great communicators, others still may be phenomenally detail or process oriented. Collectively, a team of purple people may have experience across several business functions: product, finance, sales, marketing, software engineering, design...
Building purple teams means intentionally hiring for this diversity --- the greater the distribution of experiences and perspectives, the more different types of problems a purple team can wrangle together.
Hiring purple teams is therefore both easy (so many choices!) and incredibly hard (which are the right ones?). Building purple teams doesn't mean finding unicorns. It means hiring for adaptability, an ability to learn, and empathy for the data customer. This foundation enables folks who both skew more red and folks who skew more blue to work with and learn from each other. Purple is an orientation, not a destination.
The most exciting thing though (and Benn 💯 wrote about this first) is that purple teams are not beholden to a red or a blue pipeline, nor the skill, stereotype and diversity challenges that come with that. Hiring and developing purple people is how we will satisfy the growing need for analytics engineering in the next few years in an inclusive way.
Purple teams need purple tools
Now that we've established that going purple is pretty powerful, let's talk about how to build a data stack that helps purple people make the most of their potential.
1. It's OK to move up the stack
Purple teams are not afraid of automation replacing parts of their workflow. They welcome automation and moving up the stack because their greatest contributions lie in that which cannot be automated --- a shared context and a collaborative ability to integrate disparate pieces into a greater whole.
Purple people aren't interested in solving the same problem over and over again. They'd like to do it once, learn a whole ton, and then automate it for everyone else. Purple people will therefore be the organizational champions for technology that reduces time to insight for everyone else.
We are already seeing a shift in our industry towards automation and abstraction in MLOps (e.g. DataRobot, AzureML Studio) and Analytics (e.g. Sisu, ThoughtSpot) --- solutions that represent data paths well travelled. These tools aren't optimizing for purple people directly, but purple people get excited about them because they help everyone move up the stack and refocus on solving new problems.
2. The future of purple tools is open source
The day to day of what a purple team works on will always look different --- it's shaped by a combination of the business problem that needs solving, the blend of purple experiences that lend themselves best to the problem, the state of tools in the modern data stack, and the reusable abstractions that already exist in the ecosystem.
Purple people are frequently first to a problem --- and first to a solution --- in their respective organizations. This means that as we develop more purple people, they will want to build more and more abstractions, helping others move up the stack in the process.
The data stack of the future will make sure these abstractions are modular, reusable, that they are able to integrate flexibly into many scenarios, and that we share them with one another. This means continuing to make the purple parts of our data stack open in the same way all of the foundational tools and frameworks in a software engineer's toolkit are open --- to foster collaboration, remixing and innovation.
The foundation of our data ecosystem began with open source tools --- Hadoop, Spark, Tensorflow, Keras, Pandas, NumPy, Project Jupyter... As we all move up the stack and stand on the shoulders of these giants, we must continue to create space for purple people to do what they do best --- make our data solutions better in new and exciting ways.
So let's build the next generation of the data stack to enable us, the purple people, to spend less time engineering, and more time ingenuing. An open stack that isn't built exclusively for a particular set of practitioners or to solve a particular problem. Rather, an open stack that supports integrating modules with flexibility to solve new and evolving types of problems. An open stack that enables us to work on improving it, together.
💜 The future is open. ☮️ The future is purple. 👩🎤 And it's already here.
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




