Welcome to the dbt ecosystem

last updated on Jun 03, 2024
Over the past few weeks, we've seen something exciting happen: two amazing companies in the modern data stack have launched major integrations with dbt.
- Fivetran is running dbt jobs directly inside the Fivetran interface.
- Census is taking data from your dbt models and piping it back into your operational tools.
These are non-trivial integrations---the product and engineering orgs at both companies have deeply invested in building this functionality. In this post I wanted to take a second to talk about this trend, where it's headed, and why I'm personally excited about it.
On trust and standards
Most of my professional career has been spent using proprietary software and being a part of organizations building proprietary software. While many software engineers are used to building and using open source software, data analysts traditionally have had little entree into this world. If open source still feels weird to you, well, it does for me as well! But every day that I live in this world I love it more.
The primary benefit of living in the world of OSS is that it's permissionless. The FSF would say that it's free, but I think that's a value-laden term that is actually less descriptive. Permissionless, for me, gets at the heart of the value of OSS: I can do what I want with the software and I don't have to ask anyone's permission.
dbt Core is licensed under the Apache 2.0 software license, an industry-standard "permissive" OSS license. The Apache 2.0 license gives users extremely broad latitude over what they want to do with with the software. Use it? Fine. Build it into your commercial product? Also fine. Develop a service that competes directly with the commercial offerings of the primary maintainer? Go for it :D
This permissionless-ness can be seen as a real cost to those who are investing real dollars in building the software---it can make monetization much harder!---but the thing it gets you in return is trust. Early adopters can have confidence that the source code isn't trash (or malware!) and that, worst-comes-to-worst, they could run the code themselves if the commercial sponsor went bust.
In later stages of a project, the value of trust starts to evolve:
- Users trust that the commercial maintainer can't lock them in to ever-increasing prices.
- Users trust that the software will be available to them regardless of the context in which they are operating (work / personal / new job).
- Other software vendors trust that they can use the software as a foundation for their own products because they maintain complete control over their own product roadmaps.
This trust creates a sense of investment and ownership on the part of users, which in turn creates positive feedback loops. Users tell their friends, write blog posts, and speak at events and the community grows. Users invest in the product by writing documentation, moderating community message boards, and contributing new code, improving the experience for everyone.
These positive feedback loops can, in turn, lead to these products becoming "industry standards". Five years ago Kubernetes didn't exist, today it runs a large percentage of the internet. This story has played out time and time again over the years, from Linux to the Apache web server to MySQL. None of these projects would have become standards if they weren't also open.
Our goal upon creating dbt was not to create a product to help some users with analytics engineering. It was to create a new way of working for all data analysts, to redefine how knowledge was created, cataloged, and consumed at all organizations. If we were going to achieve this, dbt couldn't "just" be a product---it had to be a standard. George Fraser, Fivetran's CEO, acknowledged this in April when we announced our Series A:
Over the last two years, dbt has emerged as the modern standard for managing the complex transformations that turn raw data into insight.
This thinking about standards drove our decision to open source dbt's code in the very early days, and it's one of the things that I'm personally most excited about today.
From standards to interoperability
Interoperability---the property of systems to work together---is one of the primary benefits of standardization. Think of the electric grid prior to 1938: every single generating station pumped out electricity with different voltage and current and this made it impossible to create appliances that plugged in in the way that we're used to today. It required a federal act in the US to standardize the grid and transform it into one that we'd recognize today.
This flows directly from the properties of networks. In a world where a standard exists, interactions between participants look like this:
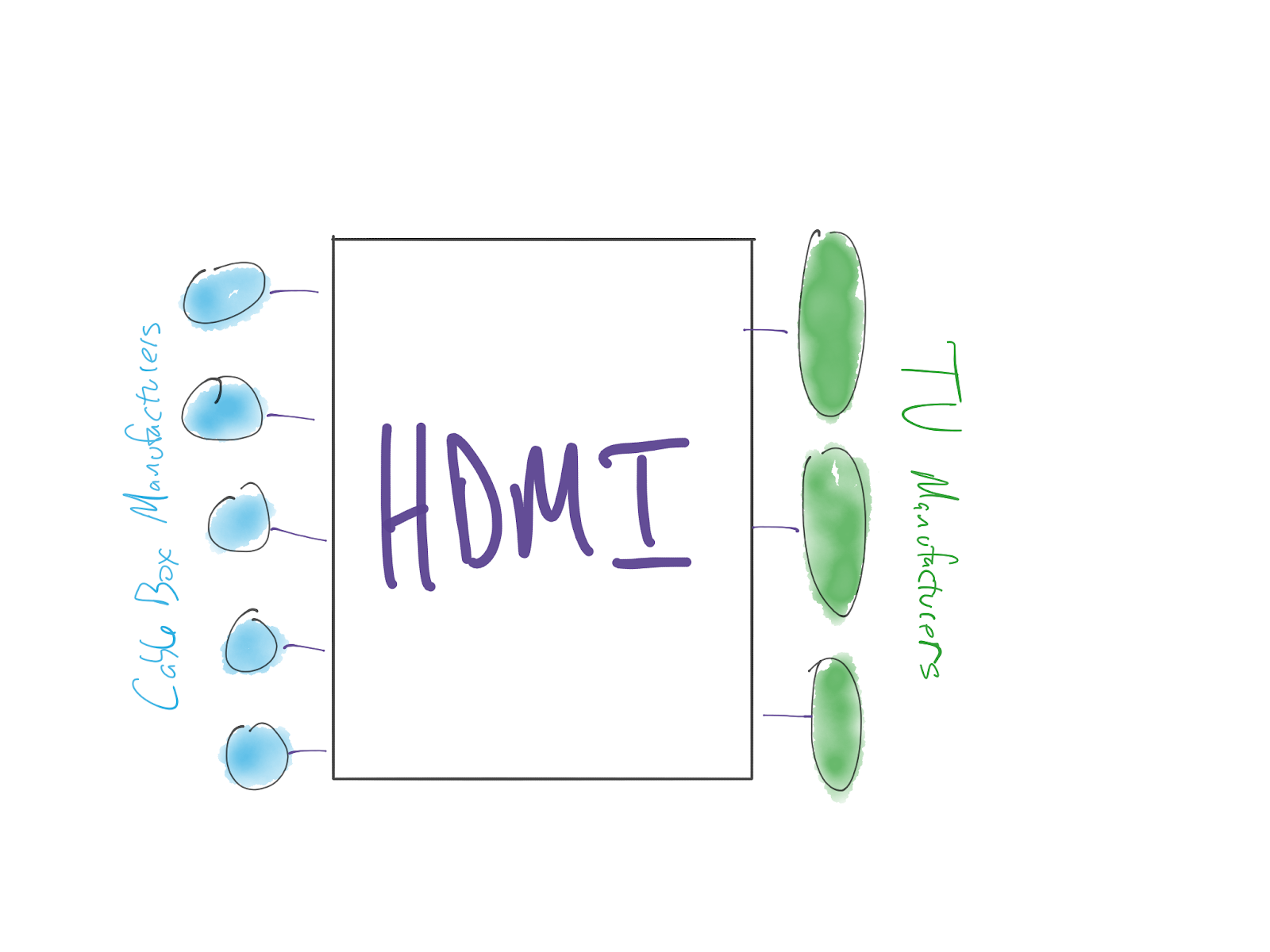
The total number of connections required is the number of participants wishing to integrate (in this picture, 8). The total number of connections required to connect all players without the HDMI standard in the above picture would be 15---a line between each cable box manufacturer and each TV manufacturer. And outside of a toy example with a tiny number of interconnections, this difference (additive vs. multiplicative) grows supra-linearly.
The SQL standard has been a huge accelerant to the modern data stack to this point. The entire ecosystem knows how to speak SQL, and as a result has been able to create a fairly cohesive, end-to-end user experience very quickly. All products in the stack today work together on the layer of SQL---they all interact primarily with the data warehouse, a gigantic SQL runtime.
But data in, data out is not the only way that these products could, theoretically, work together. Imagine, for a second, some other scenarios:
- What if there were a single shared place where all BI tools could go to to find metadata about a table or column in a data warehouse? When it was created, by whom, how, what it's supposed to be used for, etc. Users analyzing data inside of BI tools would absolutely love to have this information at their fingertips as they work!- What if there were a standard way to know the answer to "How fresh is this data?" and "Are there errors in the source data?" Would you want every dashboard you ever looked at to report this info to you? I would.- What if there were a way for data ingestion products (like Fivetran) to not only publish data transformation packages (cool in and of itself!) but to publish data visualizations on top of their standard datasets that everyone could use? This would be a great starting place for any company's nascent data stack.
These are just the things that come obviously to mind; I'm sure you creative humans will come up with much better ideas. The point is, though, that each one of these possibilities requires interoperability across different layers of the modern data stack. And standards are the most effective way to drive interoperability.
The birth of an ecosystem
This is why I'm excited about the announcements from Fivetran and Census. They're the first real commitments made by other vendors in the modern data stack to support dbt as a first-class part of their products. These companies are making real bets on dbt as a standard.
I believe that over the coming months and years there will be far more companies building native integrations to dbt. There will be many experiments run in this space and some will work out better than others, but the promise of integrating the modern data stack together on a layer above SQL is too big to be ignored. It will happen.
I also believe that these integrations will start out pretty thin but will deepen over time. It takes a long time for a snowball to start rolling downhill, but once it does, it's hard to stop. Companies that start to contribute to the dbt ecosystem will recognize its dynamism and be excited to continue doing more. Bring it on.
Our goal---as Fishtown Analytics---is to do two things. First, we want to support this nascent ecosystem and encourage its growth. This includes continuing to aggressively innovate on dbt Core, both in growing its product surface area as well as maturing its APIs. It also includes collaborating with companies as they look to integrate their products into the dbt ecosystem.
Second, we want to build commercial software that makes this ecosystem a) more turnkey, b) more accessible, and c) more reliable. As dbt becomes increasingly widely deployed, we're committed to making sure that the infrastructure required to run dbt is available to everyone, from the smallest one-person data teams to the largest enterprises in the world.As a long-time user of the modern data stack, I have kind of just accepted that the tools in it just aren't that well integrated with one another. But that's going to start changing. I'm incredibly excited to see that future start to come to life and to see how it takes shape.
VS Code Extension
The free dbt VS Code extension is the best way to develop locally in dbt.





