
Today, March 9th, 2018, dbt turned two years old. Wow.
The first lines of code were written by Chris Merrick, now CTO at Stitch, something that I will always hold against him. It's hard to imagine a more humble initial commit.
Two years ago, Stitch didn't exist, and neither did Fishtown Analytics. I was a senior in college studying Computer Science and working part time at a BI startup called RJMetrics along with Tristan, Connor, Erin, and Chris. If you asked me what piece of software I was most excited about then, I would have breathlessly murmured something that sounded a lot like "jamjar." Certainly, I had high hopes for dbt, but I was unsure why anybody would care about our opinions on how modern analytics should be done.
Fast forward two years, and there's a pretty good chance that if you see an advertisement in the NYC subway, its performance is being analyzed with the help of dbt. This is something I'm both very proud of and completely shocked at, given that one of my foundational beliefs about the universe is that I have no idea what I'm doing.
There are tons of exciting things happening in the dbt world right now. Before I talk about product, though, I want to talk about the thing that's really the most exciting to me: the dbt community.
Community.
Our Slack community is 350 members strong as of this writing and growing every day. It feels like we're onto something, although still early.
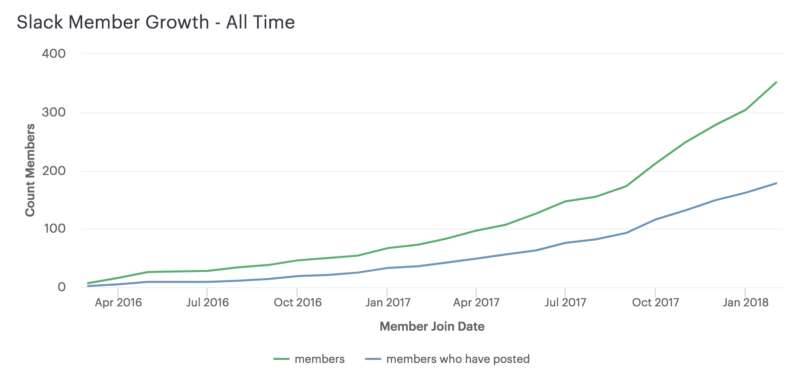
In the dbt Slack, people with roles like "data analyst", "data engineer", and "data scientist" all sit around the same table, and the result is a nuanced, but grounded, discussion of best practices in modern analytics. We've covered everything from performance tuning on Redshift to style guides for SQL. This is a truly special community, and one which I'm proud to be a part of.
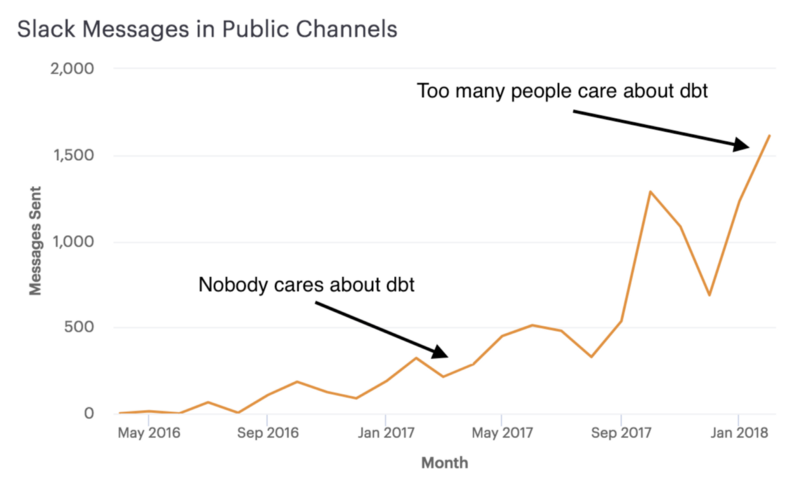
When Tristan, Connor, and I started Fishtown Analytics, we did so under the belief that analytics is a subfield of computer science. We stated this belief as a prior, but really, I don't think we had any idea if it was true or not. The past two years has been an experiment to reject that null hypothesis, and we haven't been able to do it yet! We've seen folks create amazing pull requests, give technical talks at meetups, and publish open source code to interact with dbt.
Today, a non-zero amount of traffic to dbt's GitHub page comes from links in job descriptions at companies you've heard of. These companies are looking for data professionals with experience using Airflow, Looker, Redshift, and... dbt. dbt has been shown on slides of analytics stacks at DataEngConf, it sits on the Mode Data Sources web page (next to Airflow), and it is currently used in production by roughly 150 companies that we know of. All of these things make me feel that dbt is a "real" part of the modern data ecosystem.
It's sometimes difficult for me to internalize dbt's nascent success. I remember hacking on dbt in Brooklyn coffee shops, dreaming that someday we'd have a hundred active companies. Here's what that path looks like:
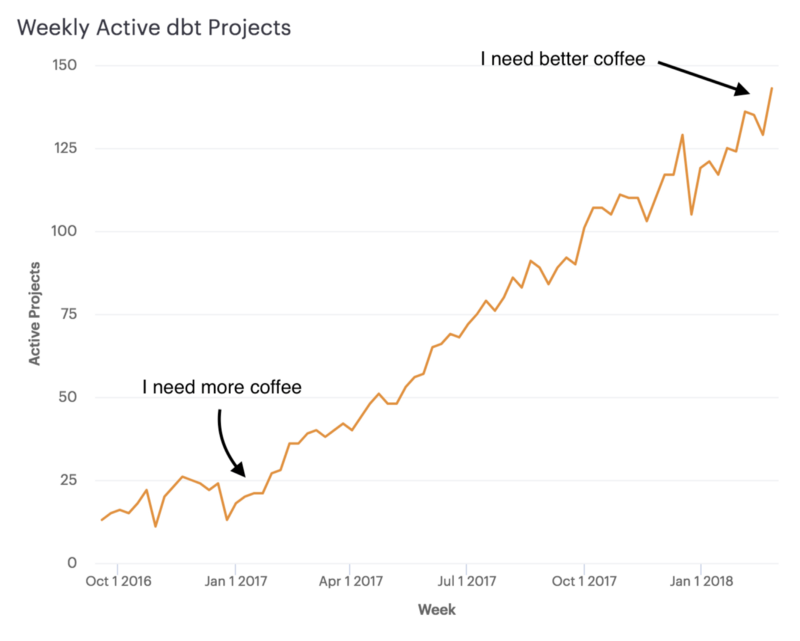
I don't know exactly where that line will go from here. What I do know is that we're going to continue building foundational features to enable data analysts, scientists, and engineers to collaborate on building high-quality analytics. As long as our community continues to need what we're building, we're going to continue to invest in dbt.
Fishtown & dbt
But...why exactly is Fishtown Analytics investing in dbt? What's in it for us, given that we're giving the product away for free? This is an atypical model for software businesses, and we frequently get asked what our motivations are. This makes sense: implementing dbt is making a real investment, and it's important for users to understand and buy into the product's trajectory. Today, we're the primary drivers of that trajectory.
This is a very interesting topic --- we think that the path we're going down is one that will be increasingly common in the future. At some point either Tristan, Connor, or I will sit down and write that post, but for now, I wanted to share some high-level thoughts.
- dbt is currently and will always remain open source. We strongly believe that core technology infrastructure should be open source. Locking yourself into a closed-source ecosystem for core infrastructure is to leave yourself completely vulnerable to the whims of an outside party. In order for us to ask our users to make a huge investment to learn and implement dbt, we have to give our users the confidence that they control their own destinies.
- Fishtown Analytics exists solely to support dbt and its community. Tristan, Connor, and I are not consultants at heart. We're product and engineering people, and we're fascinated by analytics. We have a consulting business so that we can dogfood our own product and control our own destiny by being profitable. We want to build dbt into the best product possible, and we believe we need time and experience to do that. This journey will take a decade or more, and that's just not the right timeline for venture capital.
- If we grow the community, revenue will follow. While dbt itself is open source, there are many opportunities to build commercial products in the dbt ecosystem. There are plenty of great companies that have similar business models: Elastic, HashiCorp, Github, MongoDB, and many more. There is even a term for this business model: open core. Today, we're focused on building dbt and its community; in the future we will also invest in building commercial products on top of it. Sinter (now dbt Cloud) is our first experiment in this vein.
- We invest about 1 FTE of engineering time into dbt today. Connor and I both spend about half of our time working on dbt today. We're currently hiring a full-time engineer who will be 100% focused on writing dbt code --- if you know anyone who would be a good fit, please send them our way. This person will be making commits to a product you use every day.
- The Fishtown Analytics consulting business is healthy and growing. We're certainly not getting rich here, but we currently have 7 team members and are adding analysts as quickly as we can hire and train them. (We currently have one analyst opening.) As we continue to grow the consulting business, we'll continue to invest more in building dbt.
Finally...building dbt and watching the development of the community is just fun. It's why all of us are excited to go to work every morning.
Product
Today, we released dbt version 0.10.0, a huge milestone in our journey to change the way that modern analytics is conducted. We think that analytic code, not just analytics tools, should be open source. But writing useful open source analytic code is hard: it requires designing that code with multiple layers of abstraction so that the same code can run on slightly different datasets.
Companies should be able to use the same codebase to sessionize web event data, amortize monthly recurring revenue, and attribute purchases to marketing campaigns. Much of the design of dbt has been specifically directed at achieving this vision, and we've made huge strides. We currently have over 25 companies (that we know of) who are all using the same code to sessionize their Snowplow events. In each instance, the Snowplow dbt package is configured for the specific client environment, but the core code itself is unchanged.
In order to distribute these shared dbt packages, dbt 0.10.0 includes a brand new package manager. Here are some example packages:
- Snowplow session modeling (fishtown-analytics/snowplow)
- Utility macros for common data challenges (fishtown-analytics/dbt-utils)
- MRR calculations on top of Stripe data (fishtown-analytics/stripe)
It's totally absurd to us that thousands of analysts across the globe are continually re-implementing the same transformation logic on top of common datasets. Everyone's Snowplow data is pretty much identical. Everyone's Stripe data is pretty much identical. Rather than spending time rolling their own (possibly buggy) transformations, we hope that analysts collaborate on authoritative versions of models and macros that work with these shared data sets. All of us are smarter than any of us.
In programming languages like Python or Java, developers craft modules to reuse code across projects. When programmers want to make Twitter bots, they don't begin by implementing a Twitter API client --- they import twitter and then get to writing business logic. Since SQL has historically lacked a runtime, this wasn't really possible to do in the analytics space before. dbt's new package manager, and its associated package hub (coming very soon), will help bring about this new world for analysts.
I could not be more excited. This release transforms analysts from tool users into tool makers. Finally, there are mechanisms to design and share reusable SQL packages.
dbt 0.10.0 also has a bunch more stuff in it: support for BigQuery date partitioned tables, improved Snowflake warehouse management, and more. See the whole changelog here.
Roadmap
Fishtown Analytics is totally bootstrapped --- we've never taken any VC money, and we've been profitable from the beginning. This gives us a unique advantage over some of the other organizations operating in the data space: We have time. We don't feel pressure from investors to make a ton of money, and we've never felt compelled to build anything that won't stand up over the coming decade. I am reminded of one of my favorite quotes (about programming, anyway) from Structure and Interpretation of Computer Programs:
Pascal is for building pyramids: imposing, breathtaking, static structures built by armies pushing heavy blocks into place. Lisp is for building organisms: imposing, breathtaking, dynamic structures built by squads fitting fluctuating myriads of simpler organisms into place.... As a result the pyramid must stand unchanged for a millennium; the organism must evolve or perish. Our industry moves quickly. Most of the technology mentioned in this post didn't exist five years ago! If dbt is going to survive for decades, it must be an organism. It will shift with changing currents and morph into different shapes as required. dbt is not a pristine and perfect monument --- it is the amorphous embodiment of a set of tried and true ideas.
dbt is not only an organism, but a virus. It infects the minds and organizations of the analysts who use it. Analysts frequently get started with dbt to build tables incrementally, but quickly find themselves making base models, writing schema tests, and building macros. They issue Pull Requests to their coworkers, and contribute back to dbt's open source packages. In the future, we want to expose the internals of dbt in a way that maximizes the adoption of these core workflows across data teams.
Today, dbt is a command-line application which bundles SQL compilation, database adapters, and a user interface into a single executable. There is currently no way to use part of dbt --- it's all or nothing. Instead, I'd like to see dbt become a collection of interoperable utilities that can be combined to facilitate analytics.
In 2018, we intend to split dbt into a client-server application. This decoupling will make it possible to build new user interfaces (think: running dbt from your browser) as well as lowering the barrier to entry for new users. A central dbt server which handles requests from many dbt clients will expose a new world of possibilities: query logging, performance monitoring, and federated database authentication, just to name a few. If you're happy with your current dbt workflow, you'll still be able to use it pretty much as-is; but, if you're experiencing growing pains related to deploying dbt across a team of analysts, then this change is totally for you.
In pursuit of making dbt into a client-server application, we'll need to build out a stable API. In addition to powering dbt clients, this API will serve as the substrate upon which myriad analytical tools will thrive. Tool builders will be able to harness the power of dbt's jinja-sql compilation engine, database adapters, and rich ecosystem of packages to further empower analysts to solve challenging data problems.
In the best case scenario, dbt will do for data what Ruby on Rails did for web development. That's the idea, anyway. Let's check back in another two years to see where we end up. Until then, I'll see you on Slack.
VS Code Extension
The free dbt VS Code extension is the best way to develop locally in dbt.





