The next layer of the modern data stack

Last edited on Jun 03, 2024
If you’ve been following the dbt Labs (née Fishtown Analytics) journey over the past few years, you’ll be familiar with the torrid pace of growth in the dbt community and correspondingly lofty fundraising milestones. This chart of dbt adoption has been our single best way to measure usage for over five years now and the shape of the line pretty well summarizes the journey we’ve been on as a company and community:
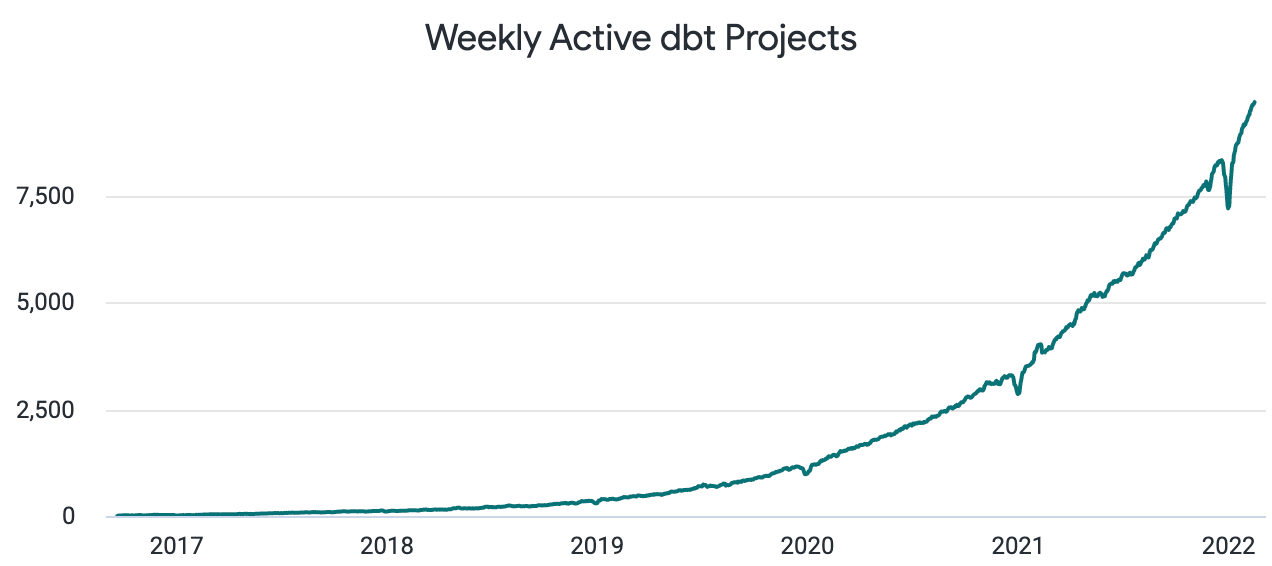
There are currently over 9,000 companies using dbt in production today. The last time we shared this chart we were at 5,500 and we’ve seen adoption consistently accelerate from there. I think it’s fair to say that dbt has officially become the industry standard way to do data transformation in the modern data stack.
In order to support the fast-growing community, we (dbt Labs) have had to scale up quickly across the board. Some stats about our past year:
- We tripled our customer count to ~1800.
- We 6x’ed revenue(!)
- We hosted 7,000 humans at Coalesce 2021.
- The dbt Community Slack has grown to over 25,000 data professionals and there are now 12 dbt Meetup groups in 8 countries.
- We finally stamped a 1.0 version of dbt Core, stabilizing the API for long-term support and improving parse time by up to 100x for our largest projects.
In order to support all of this growth, we 4x’ed the team, from ~50 to ~200, including growing engineering from ~15 to ~60. We’re doing what we set out to do—making the investments we need to support the community—but gosh it still feels so hard to keep up with you! In the grand scheme of things, we are still a tiny team relative to the size of the dbt ecosystem, and there is still so much we have to do to support our users and our partners that we aren’t doing yet.
We have more work to do; we will get there.
I want to take a second to reflect back on the journey. The ideas that became dbt were initially bouncing around in my head six years ago. Six years! We have come a long way as a community and as an industry and I am genuinely, heart-swellingly proud of what we have accomplished together ❤️
Data practitioners today are more strategic than ever to their businesses, are paid more, and are actually having more fun. We’ve also found our collective voice—the dbt Community is a group of data professionals like none I’ve ever seen. It’s been magical to be a part of this transformation with you.
Six years is a long time, though, and recently I’ve felt a visceral pull towards a new set of problems. As others have done such a fantastic job of pointing out, the modern data experience is still broken in so many ways. While dbt users have carved out a little portion of the “data value chain” and created order amidst the chaos, the minute you re-engage with the rest of the stack you realize that the industry as a whole is still a long way from achieving our original viewpoint.
Fortunately, I think dbt and its community might be able to start breaking down these barriers.
What, exactly, is dbt?
Back in 2017, I wrote a post where I posed, and attempted to answer, this question. I started with the easy, straightforward answer:
dbt is a command line tool that enables data analysts and engineers to transform data in their warehouses more effectively.
I started the post there as a way to build a bridge to something that our industry already understood: data transformation. Long-time data people understand what a data transformation product is; starting here allowed these folks to put dbt into a clear category. But as the post goes deeper, it eventually comes around to sharing how we think about dbt:
[dbt is a] programming environment for your database.
The speed, scalability, and expressiveness of modern SQL paired with the modern cloud data platform are stunning. The ever-evolving SQL language itself and the cloud architecture behind these modern data platforms are changing how data tools are built and how data work is done. What data practitioners need to harness these new capabilities is a programming framework that extends and enhances SQL. That programming framework is dbt.
Build a data pipeline? Check.
Test that data pipeline? Check.
These are both just different ways to use this same underlying dbt capability: to concisely express higher-order concepts that ultimately compile down into raw SQL.
But tests and transformations aren’t the only place where this capability is useful! When you bring this previously batch-based programming environment into an interactive context, you can all the sudden access it from every single place you analyze data.
Imagine being able to ref a model instead of selecting from a physical table name inside your BI tool! With this one change you could get native environment support everywhere you work. How cool would that be?! It’s time we had dev/staging/prod everywhere!
This is just where it starts—there are entire new constructs that only make sense in an interactive setting. dbt today begins and ends with tables and views in your database. But used in an interactive environment it will help you define your business metrics in a way that can be consistently applied to every analytical experience at your company. Finally, a single source of truth built on open standards instead of vendor lock-in!
And the power of this new experience doesn’t stop there. Community members have floated the idea of using this interactive dbt layer to define semantic entities. Partners have expressed a desire to use it to build dynamic governance and privacy tooling. All of these (and more) are use cases that can be implemented on top of a real-time dbt compilation layer.
This direction for dbt implies a fundamental architectural change to the way that the modern data stack works. Whereas the data flows in the modern data stack used to look like this:
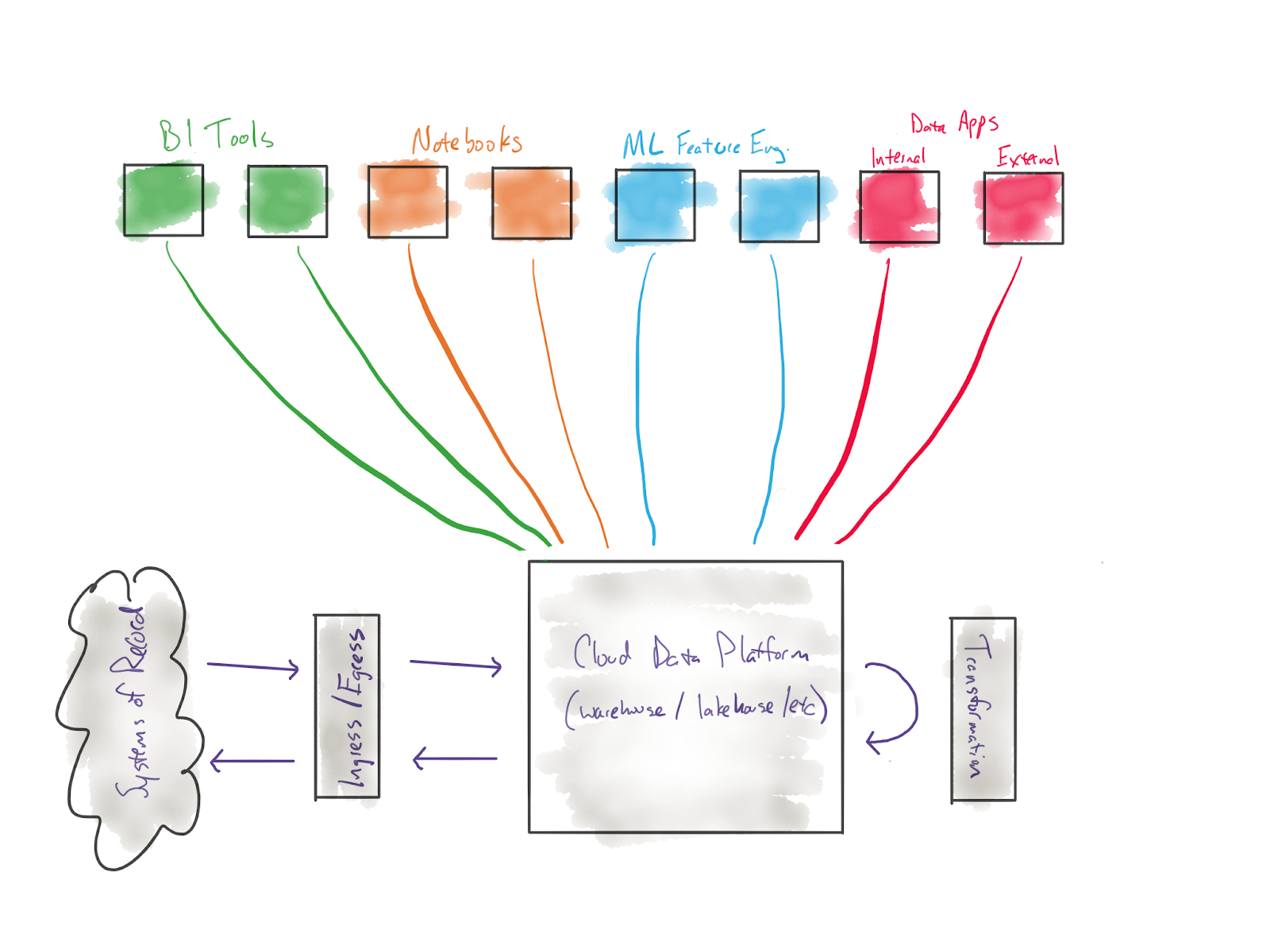
…they will now look like this:
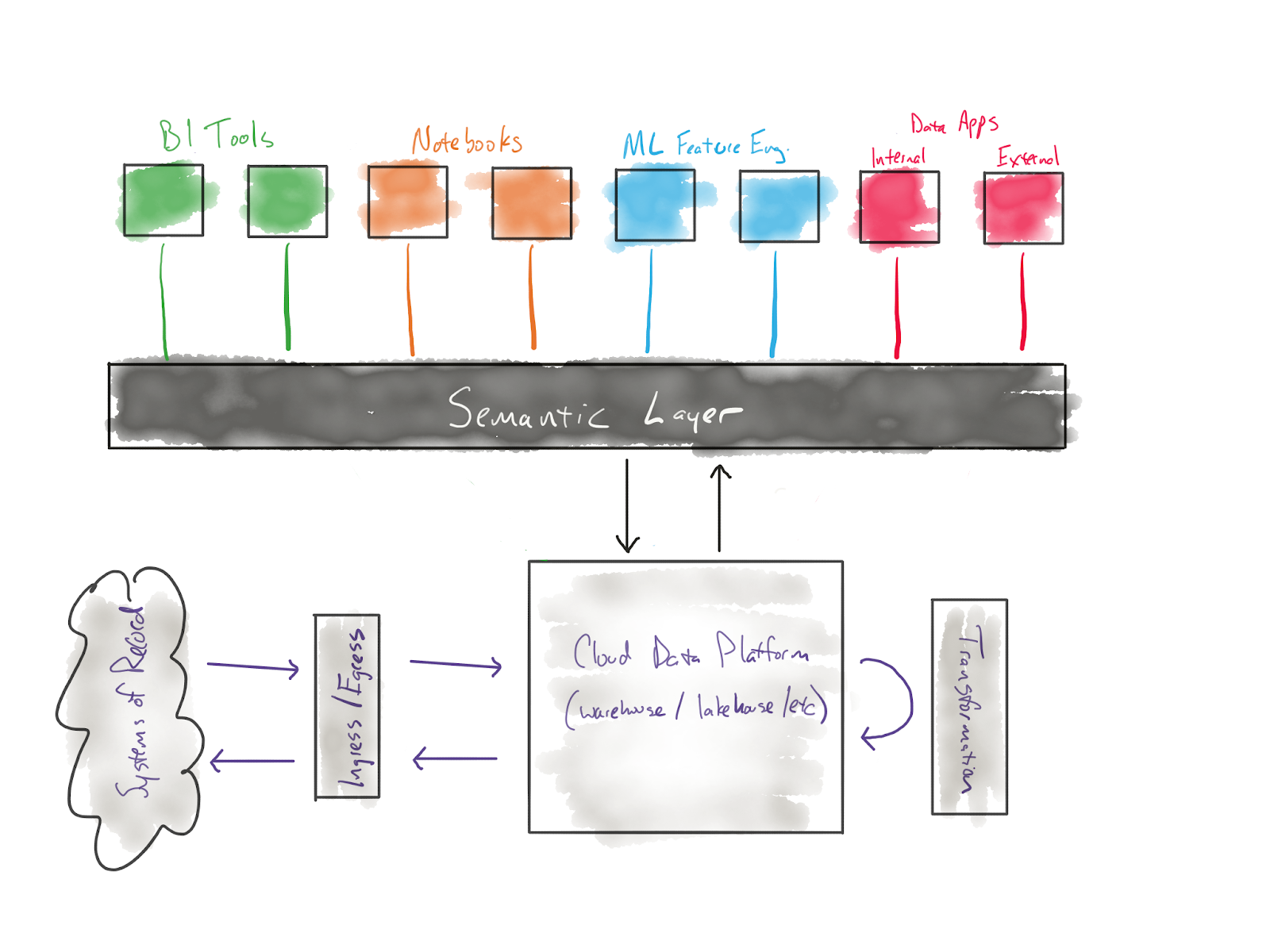
That middle layer will be dbt code and will utilize any existing programming construct that dbt authors can express—refs, macros, sources, whatever—and will ultimately give analytics engineers superpowers that today are hard to even conceive of. This will start with obvious stuff but will go deeper over time. We believe that expressing data constructs in this fundamentally novel and open layer of the stack will create a ton of whitespace for brand new products to be built, for brand new innovation to happen.
To be incredibly clear, we don’t want to build all of this new stuff. As always, my goal is for dbt Labs to empower practitioners, to empower the ecosystem. What we do want to build is the open source framework that empowers it and the production infrastructure that it runs on.
What does the community need from us?
I have said this publicly before: I think my most important job is to continually answer the question “What does the community need from us?” Starting in 2019, the biggest answer to that question has been that we need to hire across the board to support our community, customers, and partners.
But in 2021 something new started to show up. Time and again, our most forward-thinking community members were musing publicly about the future of the modern data stack, and suggesting a new role for dbt to play in that future. I would read newsletters with sophisticated takes on what folks believed our product roadmap should look like and then would get a series of Slack DMs after-the-fact from curious practitioners expressing excitement and enthusiasm. It was surreal; I felt like there was this industry-wide conversation about what dbt should become and I just got to listen in.
I am personally so excited and enthusiastic about the road ahead. But I want to be really transparent: I never would have had the courage to move so aggressively in this direction without the groundswell of support from you, the community.
Oddly enough for a startup founder, I’m a fairly conservative human, and this roadmap makes me nervous in its level of ambition. It not only relies on us building sophisticated technology, it relies on partners building on top of that technology and community members truly internalizing its potential and imagining new ways of working. dbt Labs cannot make this change happen in a vacuum—it will require all of us to see it manifest in the world.
We have a proof of concept of the dbt Server live today, and we’re actively working with a small set of design partners to iterate on the metrics experience. And we have an early version of the package that will generate metric SQL published as well (comments welcome!). But there’s a lot more to do before this work becomes real production infrastructure. We will share more the minute we can.
This fundraise—and the $4.2b valuation—are simply a recognition of how big this opportunity truly is, an acknowledgement of how much work is left to do, and a vote of confidence that we can collectively get there.
If this got you curious, excited, or intrigued, share your thoughts in #dbt-metrics-and-server in dbt Slack, or feel free to DM me (I’m @tristan). I’m spending a ton of my time these days thinking about, talking about, and working towards this version of the world and I’d love to hear from you.
My co-founder Drew, and our new CPO Margaret, will also be hosting a dbt Community AMA on March 4, 2022. Anna, our Director of Community will be moderating. Come hang out! Say "hi"👋🏻 to Margaret, talk about the metrics layer, and share your ideas for the future.
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




