

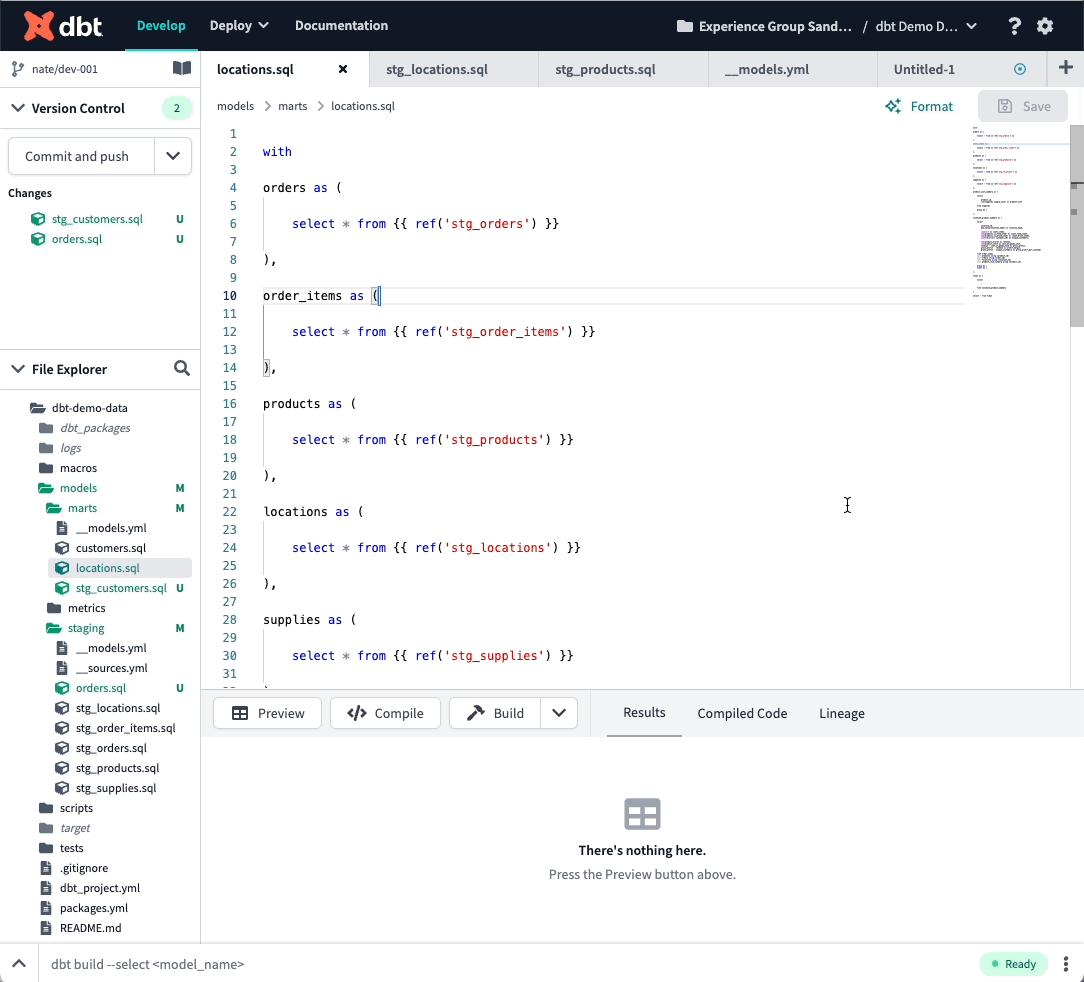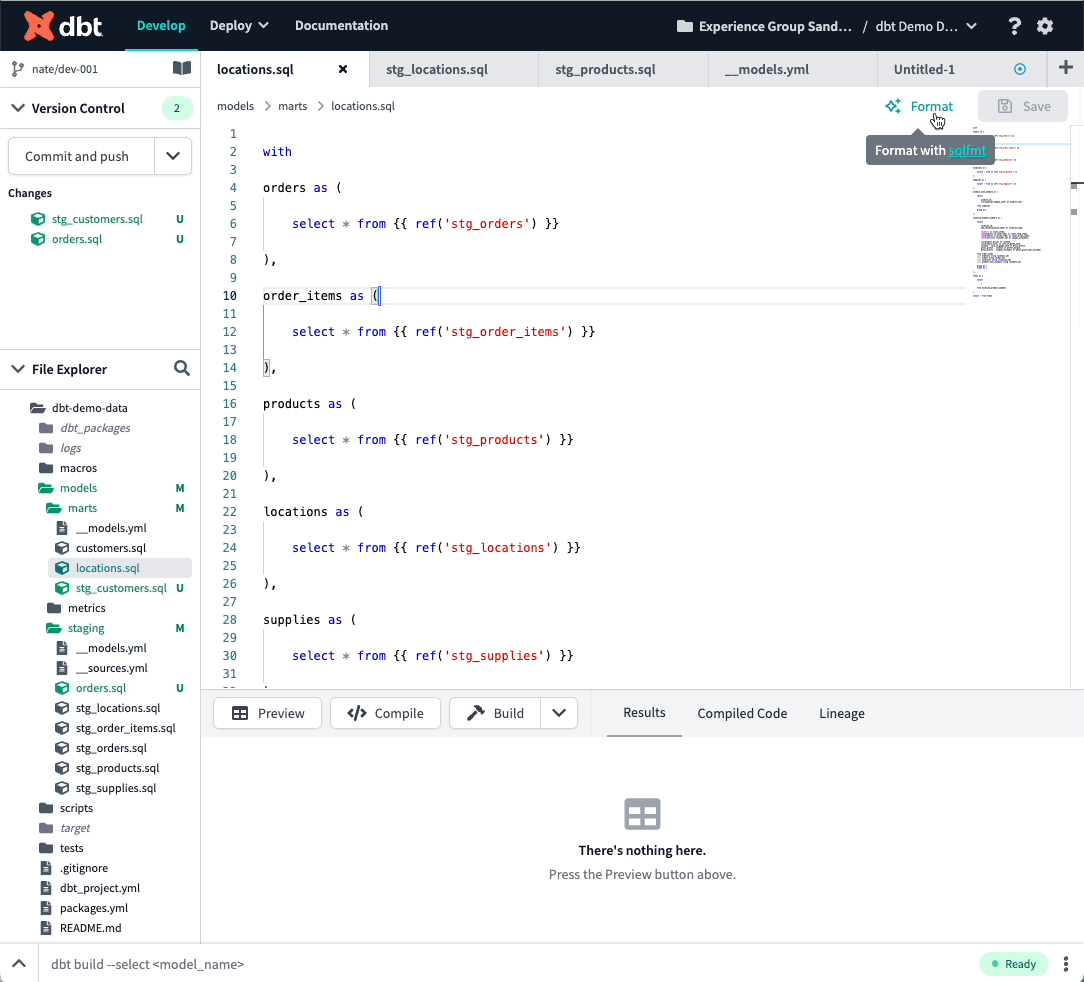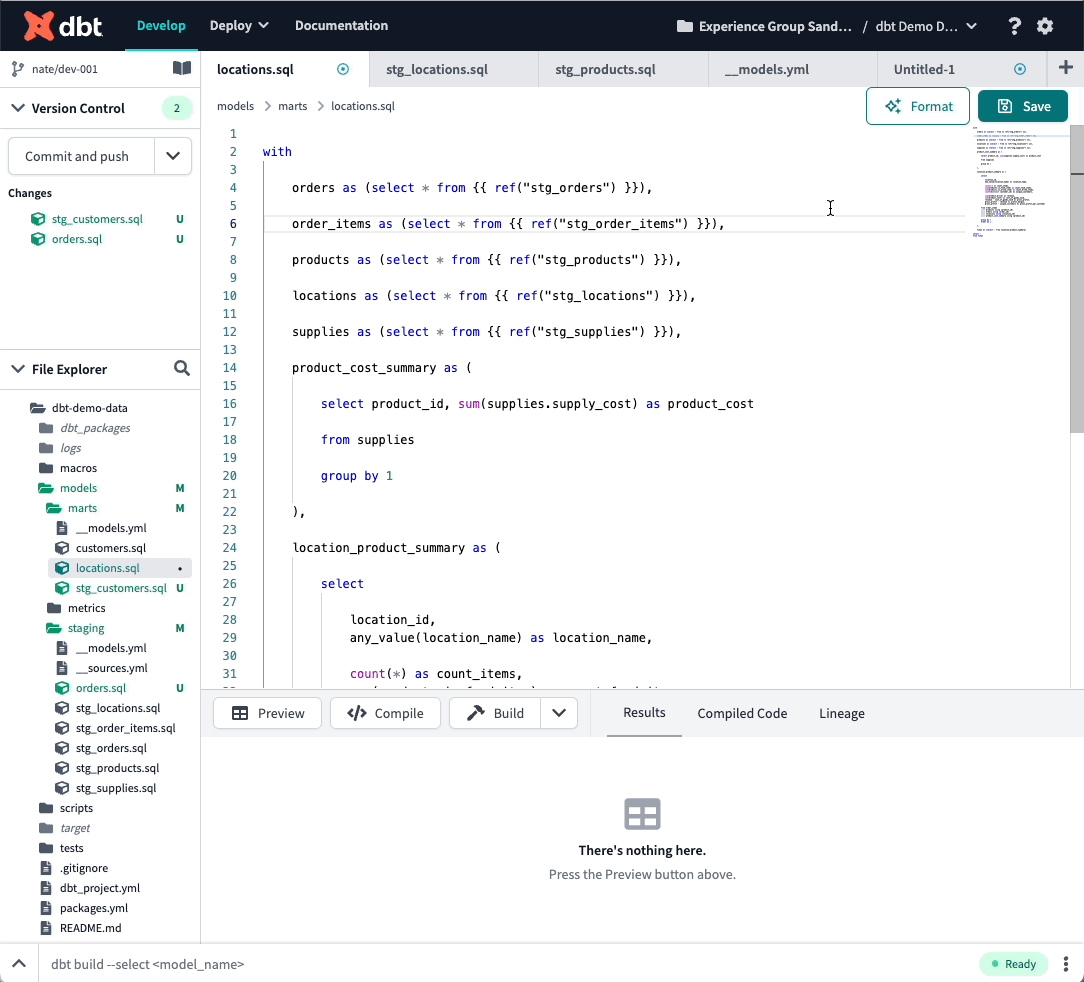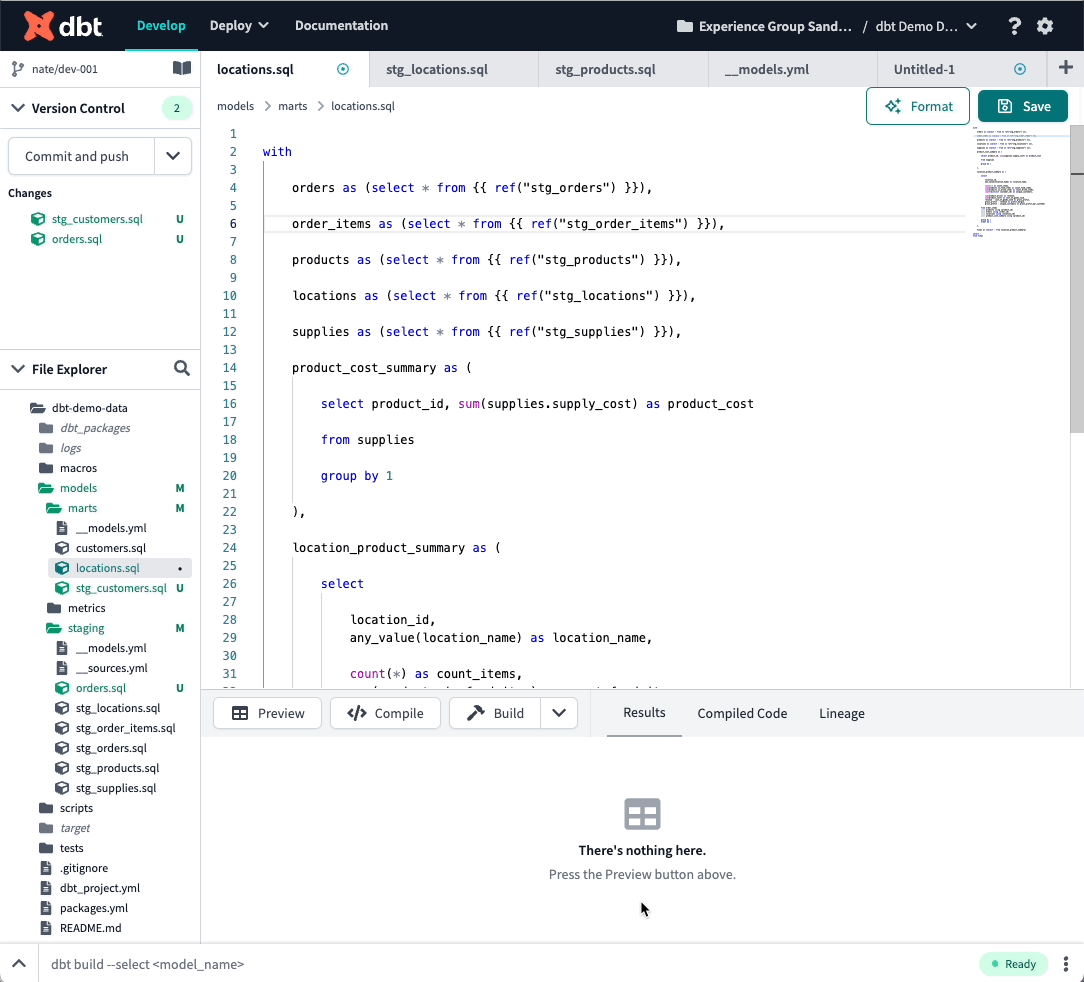
Today, dbt Labs is announcing the new and improved Cloud IDE, available to all users by the 28th of October.
In my last note to you, I shared that we were working to address the performance and reliability issues that have hindered the Cloud IDE. I’m incredibly excited that we can finally launch what our team has been working on over the past few months — to get you the IDE experience you deserve. I’ll walk you through the outcomes of the performance upgrades that we promised, the ergonomics improvements that you’ve asked for, and on top of that, some nifty quality-of-life enhancements we’ve been working on.
(Note: the New IDE experience represents performance, reliability, and functionality-focused improvements, separate from — and building on top of — our recent UI improvements you may have read about.)
The bread and butter of the product remain the same. The goal of the dbt Cloud IDE is to make it easy for you as an analytics engineer to build data models without having to think too much about things like environment setup or configuration. You should not need to deal with pip, homebrew, dotfiles that are unnecessarily difficult to find, or navigating different versions of dbt to do the work you need. That’s why we do all of that on the Cloud IDE for you already. It’s meant to be the easiest way for you to discover and explore all things dbt.
Components of the dbt Cloud IDE include:
- Code editor: The IDE code editor supports writing and running SQL and Python (!) in the context of your dbt project.
- Integrated console: The IDE integrates with the tools you need to develop a dbt project. The Cloud IDE provides an easy way to test and invoke dbt commands by using the open source dbt rpc server to connect to your data warehouse and build dbt projects. This allows you to preview your data model using data from your warehouse and visualize and navigate along your DAG in the IDE for easier development.
- Version control your code: Version control is a core element of analytics engineering. The cloud IDE supports a simplified git workflow by connecting to your pop which makes it easy for both experienced and less experienced users to collaborate on data models.
To reference Tristan when the IDE was originally launched almost 3 years ago:
“While dbt’s heritage as a command-line tool has been empowering for a large group of users, it’s also acted as a barrier to entry to many others. Learning the command line shouldn’t be a prerequisite to building a mature analytics engineering function, nor should you have to learn to manage Python virtual environments on Windows.”
So what exactly is different about this new IDE? Let’s start with some performance highlights:
Performance Upgrades
Building code in the IDE should be seamless. The tool that you’re using should not add more distractions to the data work that is often already confusing and difficult. In that vein, the primary issues we set out to tackle include the startup time (start the IDE), interaction time (to save and commit), and reliability in the IDE.
To address these problems, we entirely rebuilt the front-end app and made significant changes to the product. This includes 1) developing a new internal architecture to avoid the constraints we saw in Classic IDE and 2) re-platforming the IDE onto newer, more modern technologies.
We were able to significantly improve these key metrics, and the biggest callout here is that performance of these metrics no longer depends on the size of your projects. In the past, the larger your project (1000+ data models), the slower IDE becomes. That is no longer the case with the new IDE!

“It feels like a lot of the acute problems with the IDE have been resolved. We’re then left with the benefits of easier git flow and abstraction, visualized lineage, interactive compiled SQL, no local install requirements, and environment management from dbt Cloud.” - David Jayatillake
Ergonomic Improvements
While we set out first and foremost to address performance issues, during our rebuild of the application we were able to address some common ergonomics issues as well. We’ve added or improved on:
- Organization: Drag and drop files in the file tree, organize your tabs, multiple tab close, and display file state when there are changes
- Navigation: File selection, file picker (cmd + O), bread crumb, DAG, file change section
- Execution: Build button for easy dbt commands, Shortcuts to popular commands, Preview/compile selected code
Those are just some highlights! There are many other features that I won’t get into details in this post. I’d love for you to poke around the IDE and see what you think.
Oh, and in addition to that, we also rebuilt the product documentation section and included common tips and tricks on how to use the IDE.
“Generally speaking the beta IDE has been a success for my workflows. I used to do 100% in a text editor (Atom) and then run dbt commands from the command line. Now I'm 90% using the new IDE.” Brandon Emmerich (Suvretta Capital)
Additional Features
I was a former dbt developer in VS Code myself. There have been so many features that I’ve wished our IDE had to make my life developing analytics code easier.
It’s just a start, but the New IDE is set up for faster iteration, more predictable work, and is also a more extensible product platform for us to develop on. Our team has been going through all the things that you’ve asked for, and here are some changes we hope you’re happy to see:
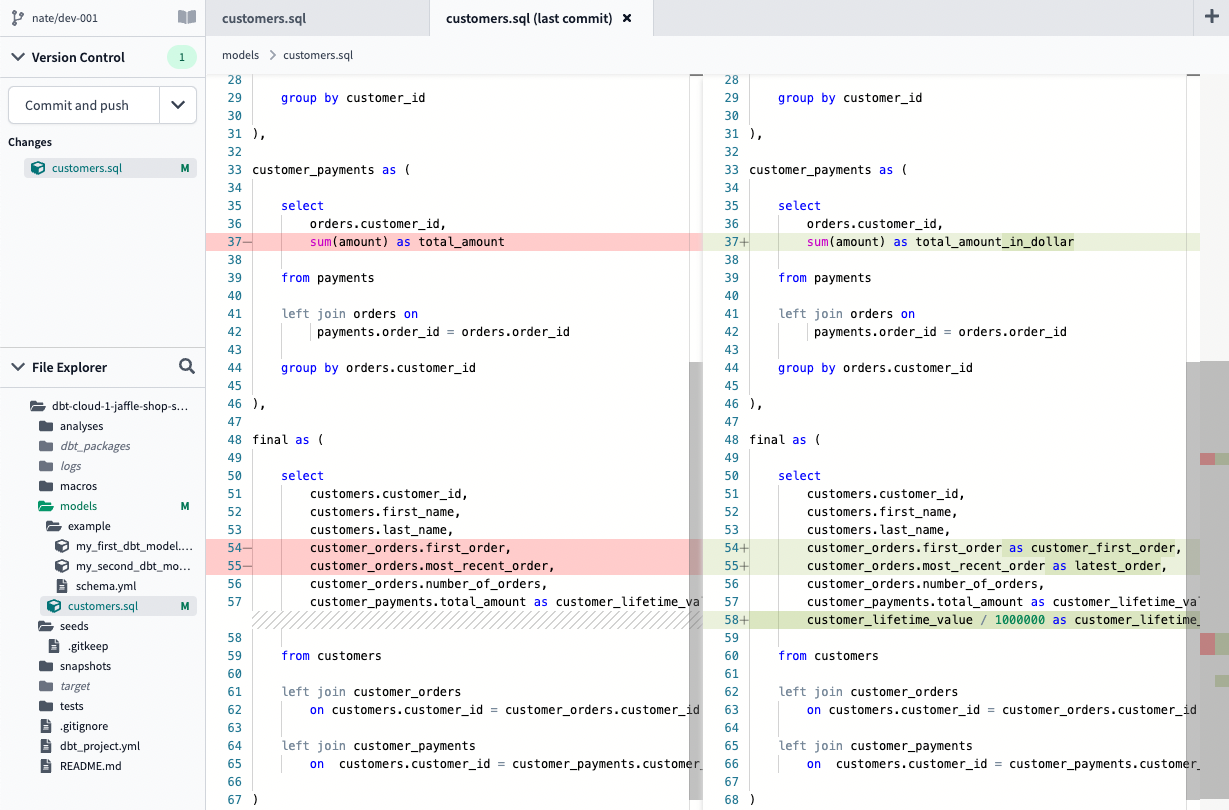
Diff view
We added in a section to summarize all the file changes in the left navigation. From there, you can see what changes are ready for you to commit easily in a side-by-side view of the file.
Autocomplete
You can now autocomplete common dbt constructs, including:
ref: autocomplete model names in your projectsource: autocomplete source name and table name in your projectmacro: autocomplete the function name and its argument inputenvironment variable: autocomplete any environment variable you have defined in the project

Code formatter
This one is exciting. There are so many amazing tools that our community has already built to improve the experience of developing in dbt. I’m happy to now introduce the first (and surely not the last!) such extension within the Cloud IDE.
The Cloud IDE now integrates with sqlfmt to allow you to auto-format your file with an opinionated style guide.
sqlfmt is similar in nature to black, gofmt, and rustfmt (but for SQL). It works with Jinja, with no templater required. Most importantly, it is very fast and easier to maintain and extend than linters that need a full SQL grammar.
I’d like to thank Ted Conbeer for his work on sqlfmt. Please check out this open-source project and contribute it if you’re interested!
What’s Next?
When are you getting your hands on this? Starting next week (Oct 28), the New IDE will be available for all users while the additional features (diff view, autocomplete, and formatter) will go on beta. The additional features will become generally available by Nov 16th.
The performance and reliability of the IDE experience are, and will continue to be, of the utmost importance to us. We plan to closely monitor and continue to improve on it in the coming weeks. Please reach out to me and to our support team if you run into anything, or just have more suggestions.
The performance work is still not done. I am well aware that a cold start of 40 seconds is not truly revolutionary. We will continue to invest more effort to make the experience better, keep you in a state of flow as long as possible, and allow you to do your best work.
Beyond performance upgrades, there are still many other essential development features that I aim for us to get to: from linting (SQL Fluff), to global search in the IDE, improved interaction with DAG, native integration with documentation, and more complex git controls, to mention just a few. We are actively thinking about and working on ways to incorporate these features in the IDE.
If you’re interested in what’s coming next, or just want to chat about your developer experience on dbt, reach out: I’m @Nate Nunta on dbt Slack!
Published on: Oct 18, 2022
2025 dbt Launch Showcase
Catch our Showcase launch replay to hear from our executives and product leaders about the latest features landing in dbt.
Set your organization up for success. Read the business case guide to accelerate time to value with dbt.





