Introducing the Discovery API

last updated on Sep 11, 2024
Today we released the Discovery API, a significant revamp of the dbt Cloud Metadata API. It’s available in Public Preview for customers on dbt Cloud Team and Enterprise plans.
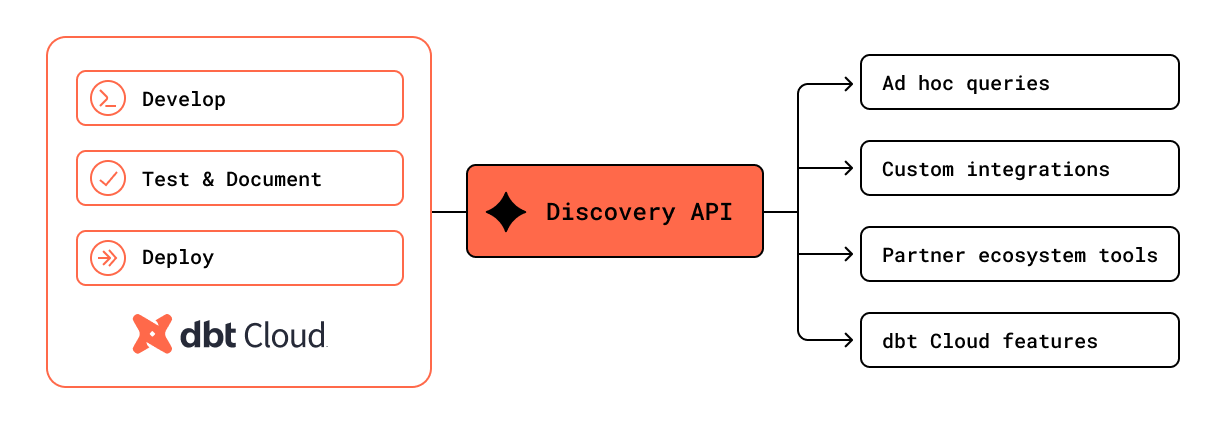
The API is designed to help you get a rich understanding of your dbt deployment and the data it generates, facilitating faster data discovery, better data quality, and easier pipeline optimization. New environment-level endpoints give you a comprehensive view of your dbt project's state, eliminating the need to query multiple jobs or parse artifact files.
You can access the API today through ad hoc queries, custom applications, or a range of ecosystem integrations.
A wealth of information
Every time your dbt Cloud project runs, it generates valuable information. When was the data last updated? Which models, tests, and sources are part of the project, and how are they connected? How long did it take to build each model? Which tests passed, and which failed? What does a table or column mean?
As the complexity of a dbt project grows, spanning many teams and datasets, information like this becomes essential for you to easily understand your data and optimize your deployment. But it can do more than that too: it also allows you to prevent or quickly resolve issues and equips data consumers to find and use the data they need with confidence.
An improved developer experience
The Discovery API introduces two types of project state:
- Definition: The state of a dbt project’s resources (DAG) at compile time. It updates when the project is changed.
- Applied: The output of successful dbt DAG execution that creates or describes the state of the database (e.g. dbt run, dbt test, source freshness, etc.)
You can now easily view the difference between a model’s definition and its applied state; perhaps it hasn’t been run yet or the run failed. The tables/views in the data platform today are considered applied as a result of the last successful dbt Cloud run.
Most dbt Cloud users have multiple jobs based on factors like when the models need to be updated or when the sources are refreshed. Because of that, it's been hard to have one entry point to get results for each model from all the jobs. The Discovery API now provides production metadata at the environment-level, so this is no longer an issue.
Here’s what you can expect with the Discovery API.
- Easier path to integration. Unlike with using artifact json files or the job-level API, you will be able to:
- Get consolidated results across multiple jobs and runs for the latest, most relevant metadata.
- Use enriched lineage and flexible filtering options for efficient querying.
- Simplified setup for application end-users.
- Users no longer need to configure different job IDs or provide json files during setup.
- Use the same configuration approach as the upcoming Semantic Layer release.
- Richer and more timely metadata, with reliable latest or historical production state.
- Choose the results that best suit your users’ needs: latest state, historical runs, or state comparison.
- Couple with outbound webhooks to pull new metadata when a run completes.
Use cases
Here are some of the ways you can use dbt Cloud metadata with the new Discovery API.
See the complete use case guide for more detailed examples.
Performance: Identify inefficiencies in pipeline execution to reduce infrastructure costs and improve timeliness.
- What’s the latest status of each model?
- Do I need to run this model?
- How long did my DAG take to run?
Quality: Monitor data source freshness and test results to resolve issues and drive trust in data.
- How fresh are my data sources?
- Which tests and models failed?
- What’s my project’s test coverage?
Discovery: Find and understand relevant datasets and semantic nodes with rich context and metadata.
- What do these tables and columns mean?
- What’s the full data lineage?
- Which metrics can I query?
Governance: Audit data development and facilitate collaboration within and between teams.
- Who is responsible for this model?
- How do I contact the model’s owner?
- Who can use this model?
Development: Understand dataset changes and usage and gauge impacts to inform project definition.
- How is this metric used in BI tools?
- Which nodes depend on this data source?
- How has a model changed? What impact?
A rich integration ecosystem
The Discovery API is the gateway to dbt Cloud’s metadata platform, allowing you to easily answer questions via ad hoc queries, custom applications, or dbt Cloud features like model timing and the dashboard status tile. However, we expect the experience provided by ecosystem integrations will unlock the most value for the majority of teams.
We’ve been working closely with some of our key technology partners to provide you with updated integrations:
“Monte Carlo gives data engineers end-to-end visibility into their data, including how data quality issues relate to their pipelines running on dbt Cloud. dbt’s Discovery API will enable our data observability platform to provide mutual customers with more granular and scalable insights into dbt performance, dbt runtime issues, dbt test results and other factors that impact the reliability of their data assets. With this new API, data teams can detect and resolve dbt-related incidents faster - before they impact the business.”
– Lior Gavish, CTO at Monte Carlo
”Data teams put a lot of love into their dbt models. The new Discovery API is a great way for Hex to surface all of that metadata and lineage in useful, intuitive ways. We’re really excited for how it will help our users make better decisions with data.”
– Claire Carroll, Product Manager at Hex
"We’re excited about the dbt Cloud Discovery API launch, and we've already begun integrating it with Atlan. The richer metadata will help joint customers easily discover, understand, and trust their data, paving the way for more effective data-driven decision making."
– Prukalpa Sankar, Co-founder at Atlan
Examples
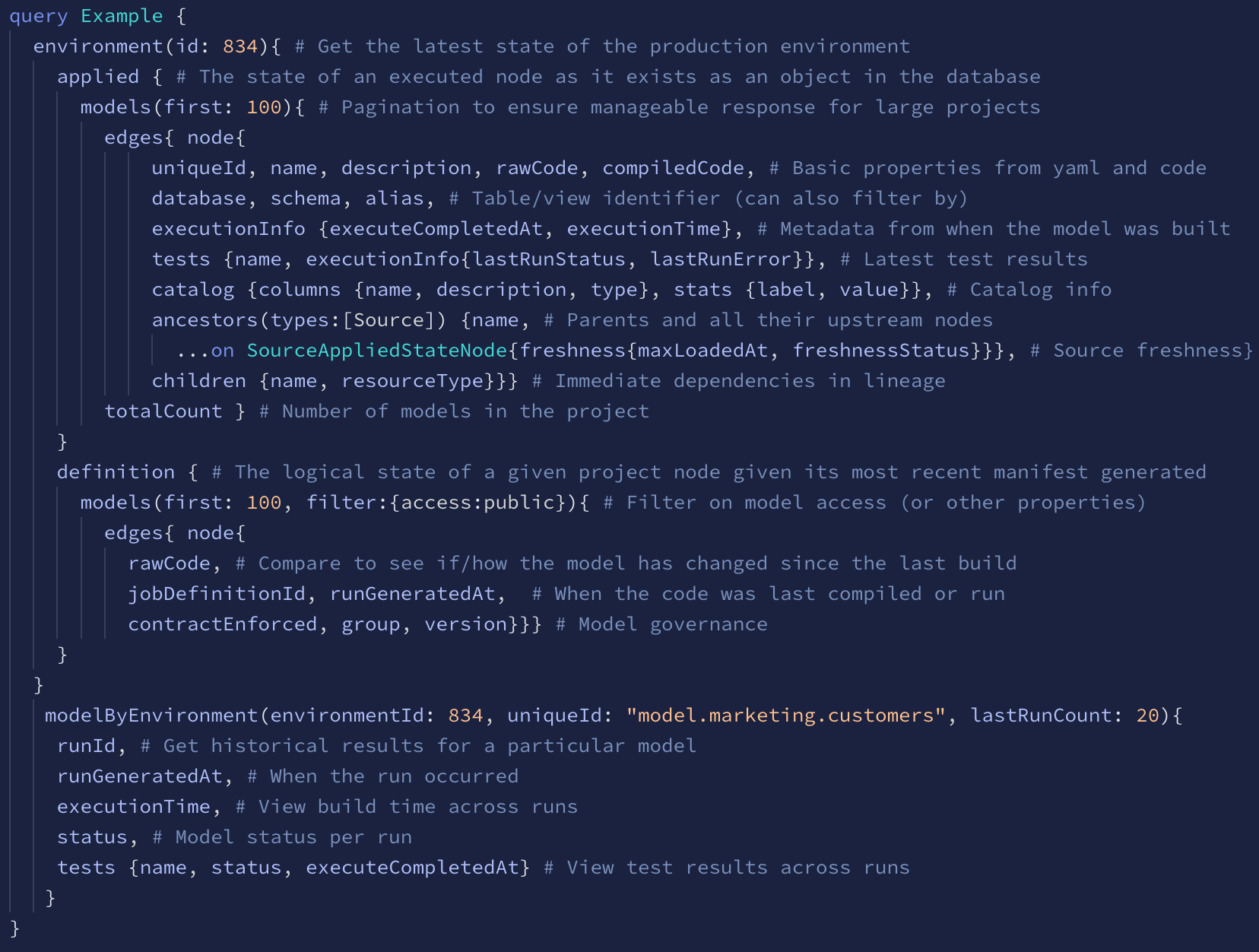
Query
Here is an example of a query using the Discovery API’s new environment-level approach to get the latest information about all the models built in a project, additional definition properties of public models, and historical run metadata for a particular model.
Application
Let's dive into an example showing the ease of using the Discovery API and its potential for future integrations and dbt Cloud features.
Stakeholders need to know when a dataset was last updated to ensure data freshness and accuracy for decision-making. Data teams must monitor data quality and address any issues that arise.
Using functions like these, the API informs the creation of a lineage graph, calculation of when each model was last run and its sources loaded, and alerting of model owners given freshness SLA violations.
Here’s an example result:
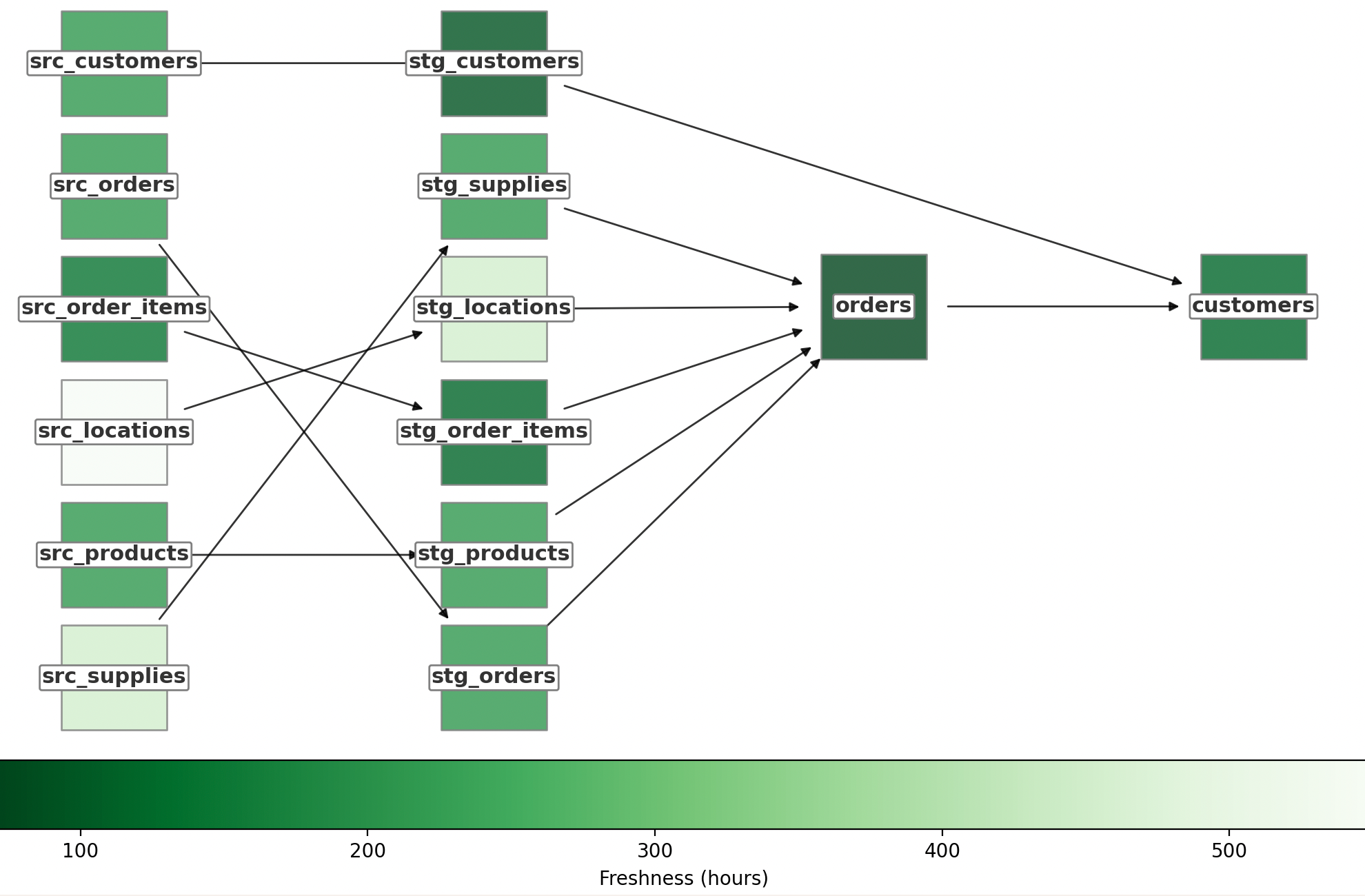
With dbt Cloud metadata, you can create systems for data quality monitoring and alerting, lineage exploration, and automated reporting with machine learning.
Roadmap
We are continually enhancing the dbt Cloud Discovery API to ensure you have access to timely, rich, and reliable metadata about your dbt runs. In the coming year, we’ll expand the range of questions the Discovery API helps answer so you more easily understand the state, meaning, and structure of your data to inform data development and analysis experiences.
- [Now] Query across jobs & lineage: Get the latest state of a dbt DAG (production environment) to find, understand, and trust the right dataset to analyze.
- [Ongoing] Improvements: Enhanced developer ergonomics, state fidelity, and metadata timeliness.
- [Soon] Query across projects: View and manage cross-project lineage using public models to define, use, and manage governed datasets for enhanced collaboration across teams.
- [Later] Query over time: Understand longer-term dbt Cloud execution result trends to optimize pipeline performance and costs, such as improving costly, error-prone, or slow datasets.
Get started
If you’re a dbt Cloud customer (Team or Enterprise plan) or developer interested in trying the API, check out the dbt docs to get started. You may also be interested in this list of current integration partners.
Please reach out with any questions, feedback, or interest in integrating and join the #metadata channel in Community Slack.
VS Code Extension
The free dbt VS Code extension is the best way to develop locally in dbt.




