

The Fishtown Analytics team is incredibly excited to announce that we've re-launched Sinter as dbt Cloud!
A lot of thinking went into this re-brand, and you can find out more about why we made this change in Tristan's blog post on the topic. The TL;DR is that we need to think of both the client-side and cloud applications as being two parts of a whole in order to build the kinds of experiences that we're excited about. We re-branded in order to make this integrated positioning clearer to the community and the wider data ecosystem.
In this post, I want to survey the new and improved functionality in dbt Cloud. I'll call out some of the features and updates that excite us, and share some thoughts about where we see things going from here.
Overview
dbt Cloud is a hosted service that helps data analysts and engineers productionize dbt deployments. It comes equipped with turnkey support for scheduling jobs, CI/CD, serving documentation, and monitoring & alerting. dbt Cloud's generous free tier and deep integration with dbt Core make it well suited for data teams small and large alike. If your team is interested in giving it a spin, you can create a free account here.
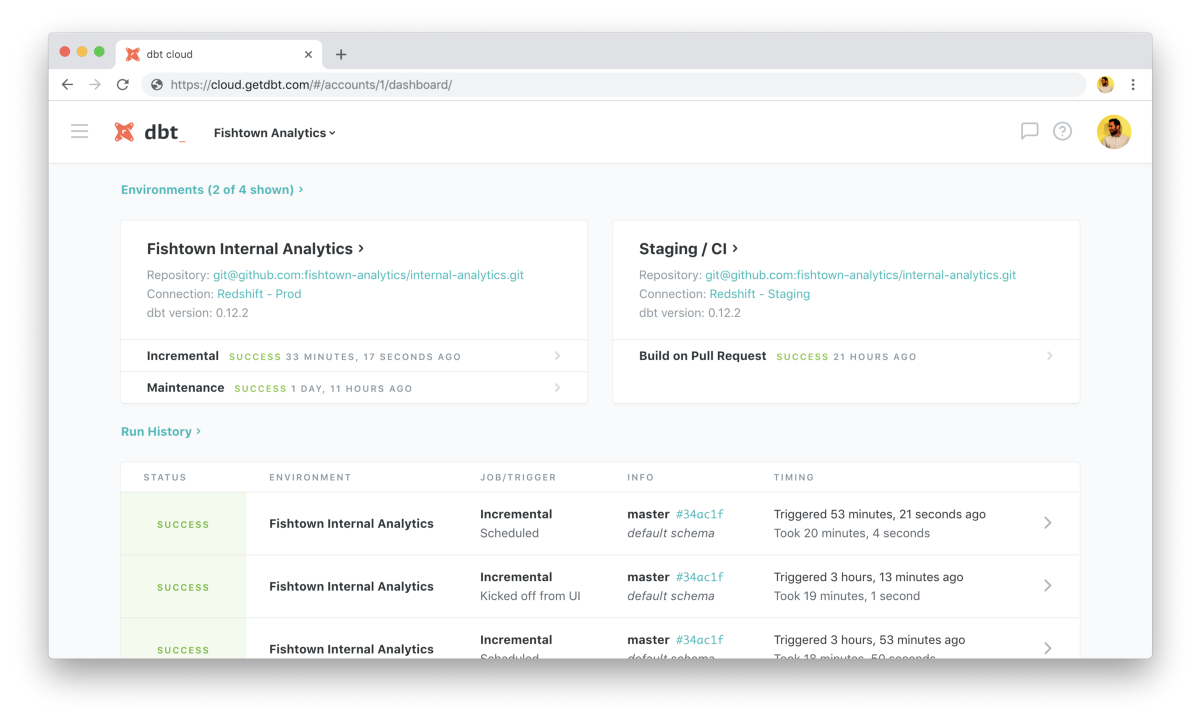
Rethinking Primitives
One of the biggest (and easiest to overlook) changes in dbt Cloud is the introduction of Environments. These environments encapsulate a connection and a repository, the cornerstones of any dbt project. These environments make it easy to categorize and configure jobs with a given connection, repository, and version of dbt. Environments help streamline and simplify the process of creating new jobs.
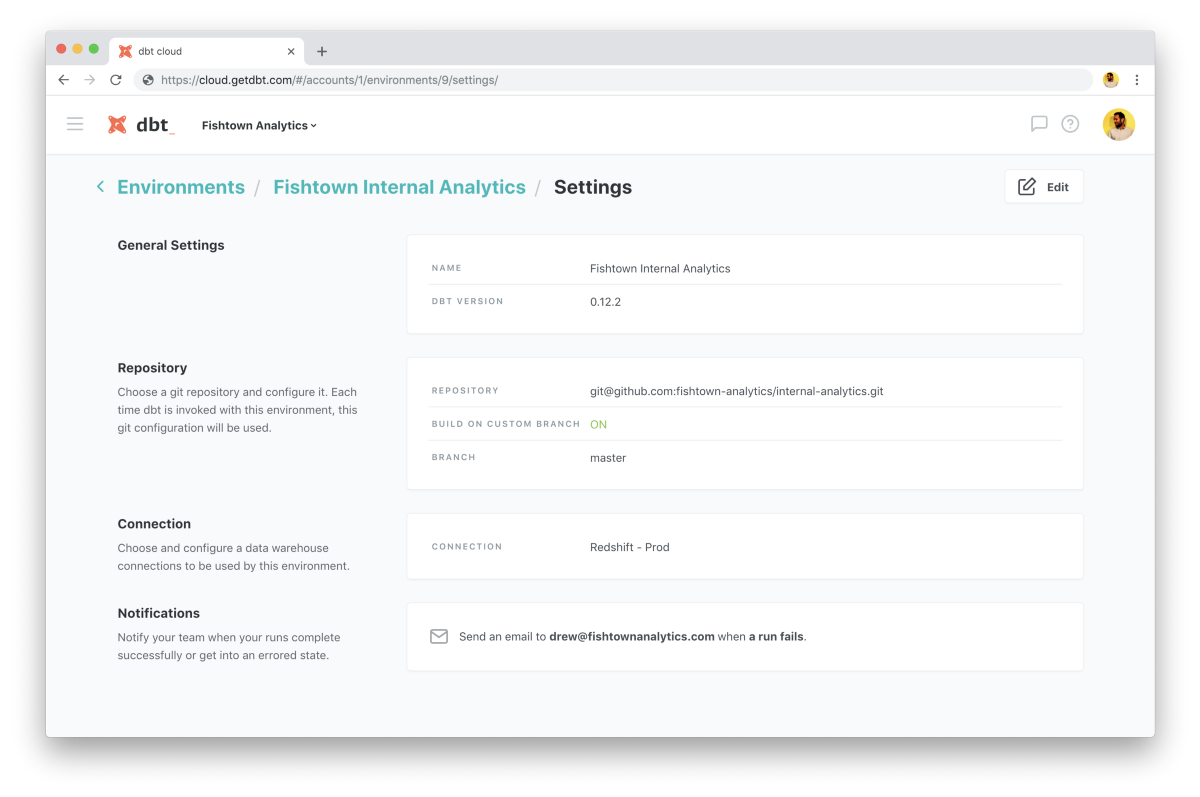
Environments are also the foundation for an upcoming paradigm shift in how dbt is deployed across teams. We've previously written about our plans to make dbt work in client-server paradigm, and environments set up dbt Cloud well to act as a persistent dbt server which will be able to field requests from dbt clients.
In a client-server world, each user could have their own environment (complete with configuration and credentials) which will simplify and secure the rollout of dbt to all of the members on a data team.
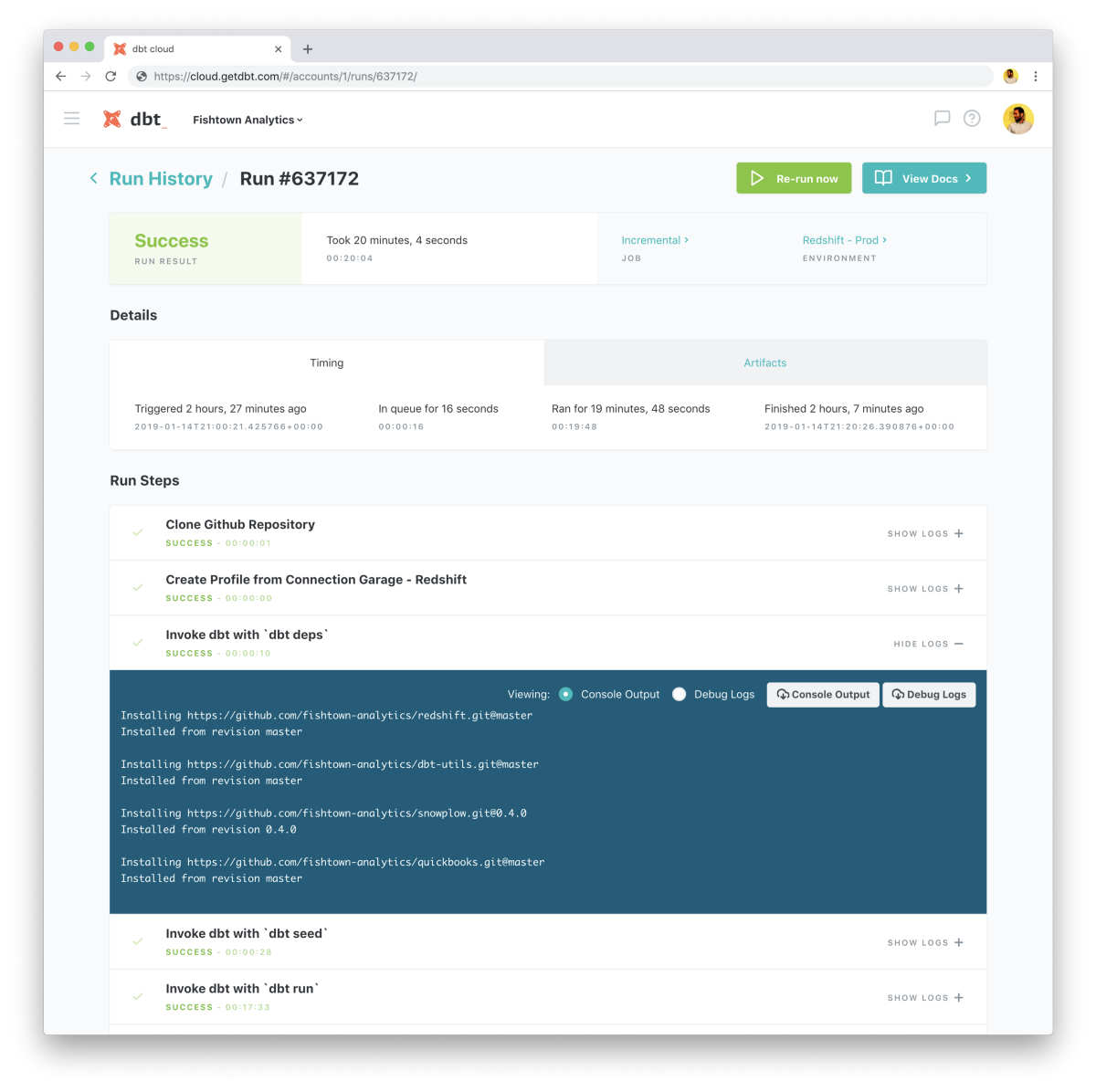
Run History
In addition to some strategic backend updates, dbt Cloud ships with a brand new Run History interface. This new page makes it easy to filter and view jobs by their name, status, and environment. If you've ever tried to hunt down a failed job from three months ago, then this feature is for you!
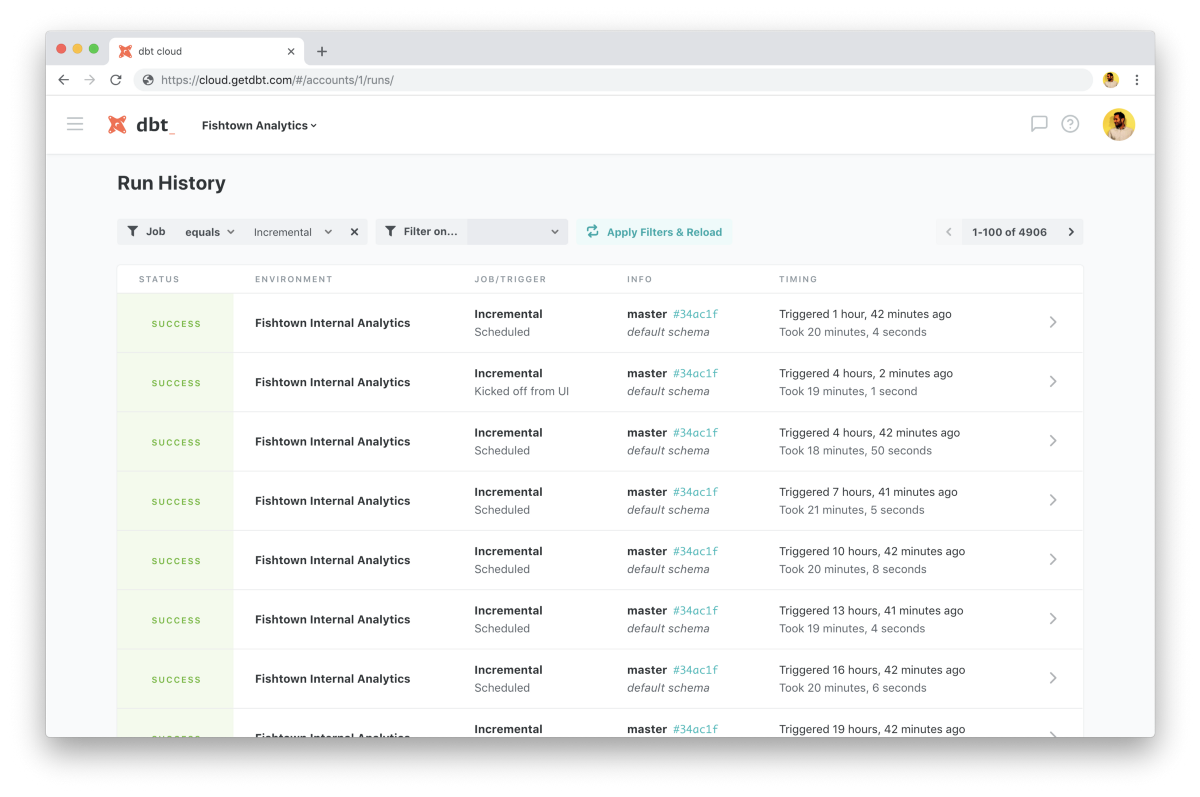
With this new interface, dbt Cloud users can drill into historical runs to evaluate changes in project build times, diagnose build errors, and audit data quality issues. This Run History page is emblematic of the types of interfaces that we're excited to build going forwards. dbt Cloud will increasingly provide rich user interfaces over the functionality provided in dbt Core to enable the deployment of dbt to entire data teams.
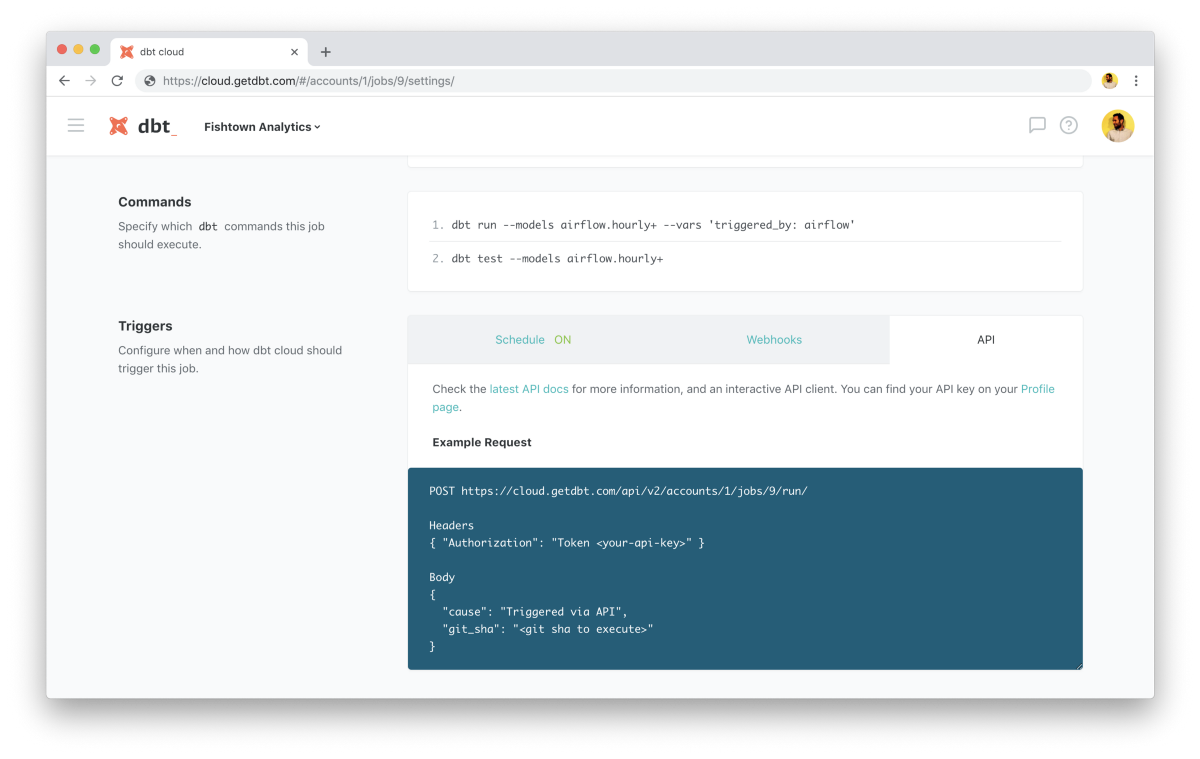
Tighter API Integration
dbt Cloud brings with it a new API for managing deployments of dbt. This API makes it possible to orchestrate complex data workflows through the creation and triggering of dbt Cloud jobs. Some users are already using this API to trigger dbt jobs from Airflow. Workflows like this give you the best of both worlds: deep integration of dbt into your existing data pipeline, and an easy-to-use web interface for the data analysts and engineers focused on building your dbt-based transformation pipelines.
Unified Look & Feel
Finally and most noticeably, dbt Cloud introduces a brand new look and feel. This UX is powered by a style guide that unifies the styles of dbt's documentation website and the dbt Cloud application. This style guide will help us build better, more consistent user interfaces faster than ever. This investment in UX will pay dividends as we continue to provide novel and compelling user interfaces in dbt Cloud.
Getting Started
We believe that dbt Cloud is the best way to deploy dbt in production. If you're interested in giving it a spin, you can sign up for a free account here. Like what you see? Have some feedback for us? Don't hesitate to drop us a line on Intercom.
Happy modeling!
Published on: Jan 15, 2019
2025 dbt Launch Showcase
Catch our Showcase launch replay to hear from our executives and product leaders about the latest features landing in dbt.
Set your organization up for success. Read the business case guide to accelerate time to value with dbt.





