

At its core, dbt is a workflow tool that makes it easy to build and process DAGs (directed acyclic graphs). In dbt's latest release, we made some significant changes to how dbt processes these DAGs, and we're seeing that these changes make dbt projects run about 30 percent faster. In this post, I'll break down how dbt processes DAGs and explore the implications its brand-new graph traversal scheme.
Hang on, what's a DAG?
You don't need to be a graph theory expert to use dbt, but a basic understanding of how graphs work can help you reason about your dbt project. In computer science, a "graph" is a collection of nodes with edges that connect them. In the graph below, the dots are the nodes, and the lines between them are the edges.
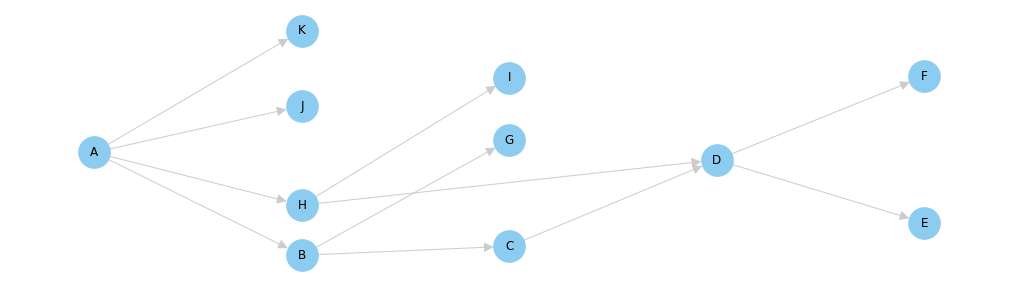
The graph shown above is a really special type of graph. It's called a DAG, or a Directed Acyclic Graph. It's directed because the edges have arrows indicating a direction, and it's acyclic because there are no "cycles" (or loops) present in the graph. You can tell that this graph is acyclic because if you put your finger on any node and follow the lines in the direction of the arrows, there's no way for your finger to touch the same node twice.
DAGs are a much-researched and well understood data structure, so there is a rich vocabulary for discussing them, and heaps of algorithms for operating on them. As we'll see below, DAGs are used by dbt, but they're also the data structure that powers GPS navigation, social networks, and search engines.
Dependencies and Ordering
DAGs are a natural way for representing processes with dependencies. In these processes, the steps in the process are the nodes, and the dependencies between them are the edges. Looking at the DAG again, we can see that Node B has a dependency on Node A. That is: Node A needs to finish before Node B can begin. In this relationship, we say that Node A is the parent and Node B is the child.
In dbt, models are represented as nodes in a DAG. When you use the ref function to reference another model, dbt creates an edge between the two nodes. In this way, dbt users are able to build and maintain really complex networks of models without having to think about the larger structure of their graph (or even realize that there is a graph at all!).
When you execute the dbt run command, dbt will analyze your graph and generate a dependency-aware ordering of all of your models. One convenient way to do this is with the topological sort algorithm. Crucially, this topological ordering of models considers the parent/child relationship between all of the nodes in the DAG, and will ensure that children are never run before their parents. Once a topological ordering of models has been generated, dbt can execute the models in the graph in order, one at a time. The image below shows a topological ordering for the DAG shown above. Topological sort is a great algorithm, and it's how dbt iterated through DAGs in the early days.

Don't Thread on Me
Modern data warehouses are impressive pieces of technology. Warehouses like Snowflake and BigQuery can scale to process enormous workloads, and dbt exists to put them to work. One way to maximize the throughput (and minimize the runtime) of a dbt projects is to parallelize the execution of its models. Consider again our example DAG. There's no getting around the fact that model A needs to run first here, but as it turns out, all of the immediate children of model A can run simultaneously after that.
To this end, dbt supports "multithreading". When dbt is configured to use more than one thread, it can arrange the models in a project such that multiple models can execute simultaneously. In this example, models K, J, H and B can all execute in parallel after model A has completed.
This is a key insight, and it's the most meaningful performance optimization in dbt today. Unfortunately, the logic required to intelligently parallelize the execution of the DAG is complicated, and we can't just throw topological sort at this problem. To understand why, consider the output of the topological sort algorithm. Suppose we had two threads ready to start executing models. The first thread can definitely get started on model A, but what should the second thread do? It can't process model K until model A has completed, but that information isn't present in the topological ordering of the DAG. Topological sort just isn't applicable in a multi-threaded use case.
Instead of leaning on topological sort, we needed to write our own graph traversal algorithm. I wrote the original implementation of it in August 2016, and it served dbt really well for a couple of years. In my opinion, it was one of the more clever pieces of code I've ever written. I suppose it looks pretty obvious in retrospect, but I have pages and pages of DAG diagrams in my notepad trying to work out an effective algorithm. Here's what I came up with:
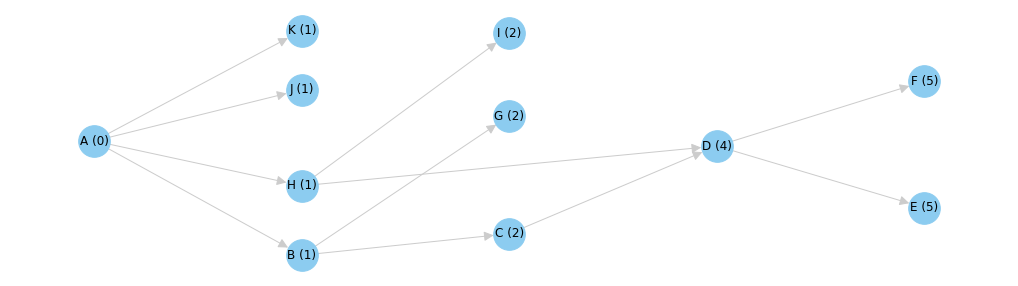
First, assign a "depth" to each node equal to the number of ancestors it has. Model A has zero ancestors, so its depth is 0. Similarly, model B has one ancestor, so its depth is 1. All the way at the end, models E and F have five ancestors each (go ahead, count them), so their depths are 5 a piece.
Once a depth has been calculated for each model, we can assemble the models into a list of "run levels" according to the depth of each model.
- Level 0: A
- Level 1: K, J, H, B
- Level 2: I, G, C
- Level 4: D
- Level 5: E, F
With this arrangement, dbt can execute all of the models in each run level in parallel beginning at Level 0 and proceeding onwards from there. As long as dbt executes each run level in order, a child will never be executed before its parent. To understand why this works, consider that any model has at least one more ancestor than any of its parents. Given this fact, dbt can run all of the models with 0 ancestors, followed by all of the models with 1 ancestor, and so on. Since all of the models in a given run level are "siblings"[1], they can all execute simultaneously. In the following animation, each model is shown with an example cost, representing the time it takes to run the model.
Making it faster
The "run level" graph traversal algorithm works well and is correct, but it's definitely suboptimal. While this algorithm will never execute models in the wrong order, it can stall execution of the graph while waiting for all of the models in a run level to complete.
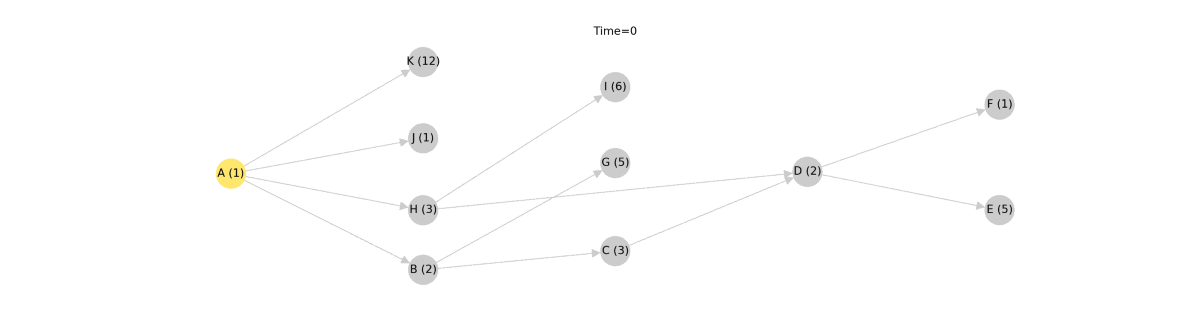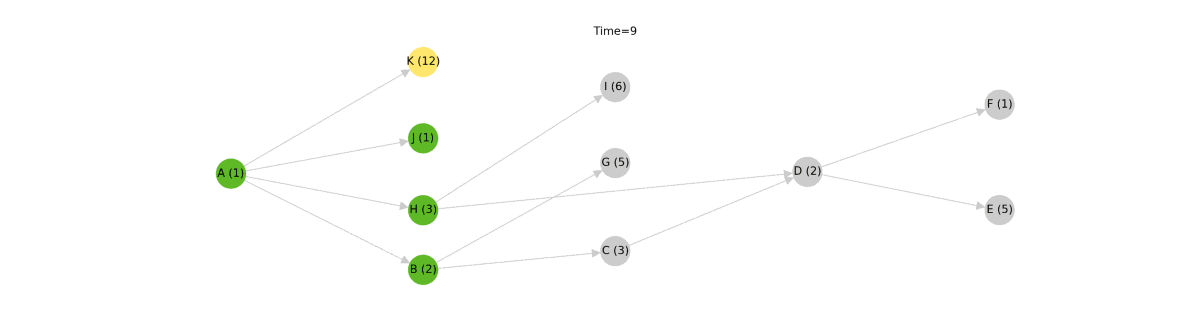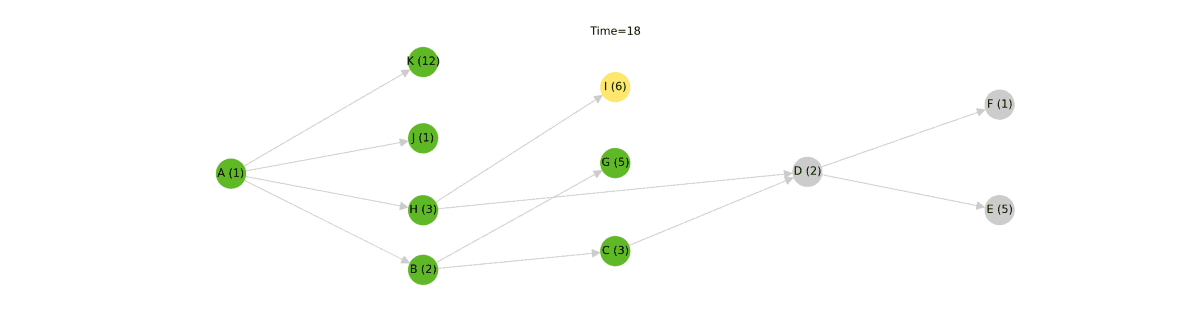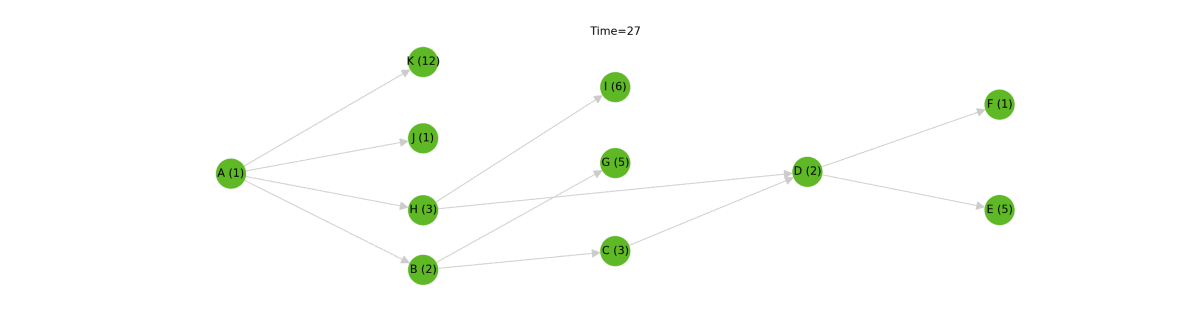
In this example, model K takes 12 seconds to execute while the rest of the nodes in the same run level take less than 3 seconds to execute. When visualized, you can see that model C is ready to execute at Time = 3, but the algorithm can't begin executing it until model K has finished completing at Time = 12. These nine seconds represent a stall in the dbt pipeline and a great opportunity for optimization.
To remove these stalls, we did away with the run level algorithm and instead implemented a type of priority queue [2]. This queue is initially seeded with the "roots" of the graph --- those models with no ancestors. A collection of worker threads consume models from this queue, executing them as they arrive. When a worker thread has finished executing a model, it will remove the model from the queue. Next, the worker will scan the graph for new models which have become executable, adding them into the queue as it goes. In this way, models will execute as soon as they are able to.
All said, this is a much smarter and more efficient algorithm than the run level approach, but it comes at the cost of added code complexity. Given the benefits, we think this tradeoff is totally justified. Check out the difference between the run level approach and the priority queue approach below[3].
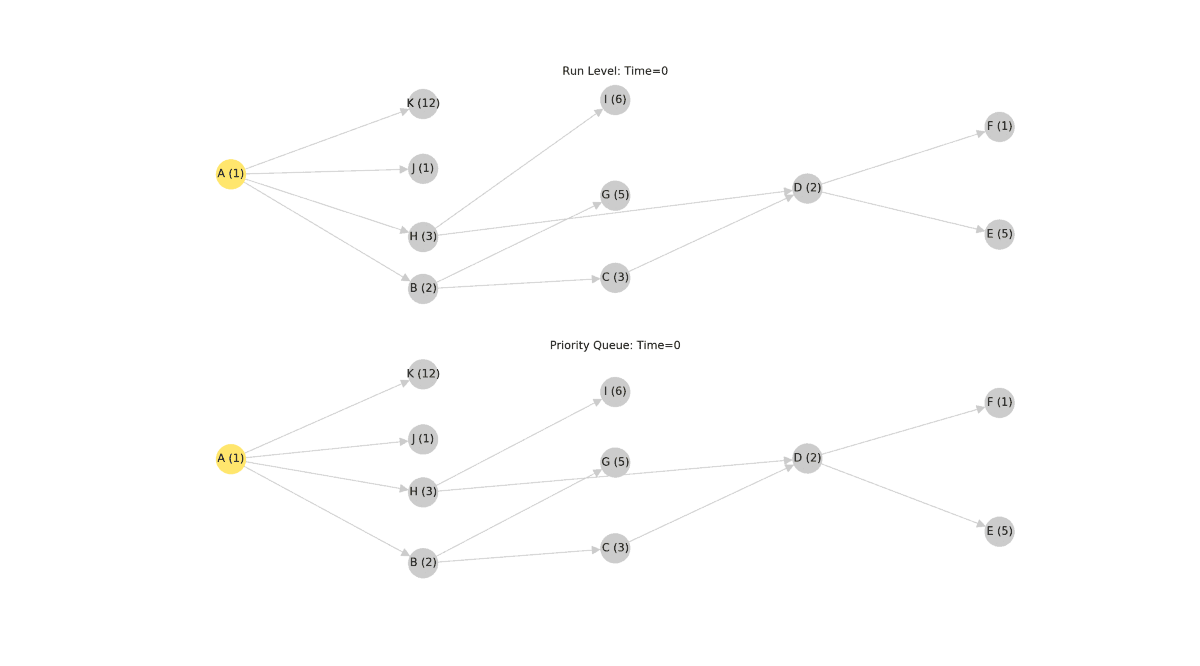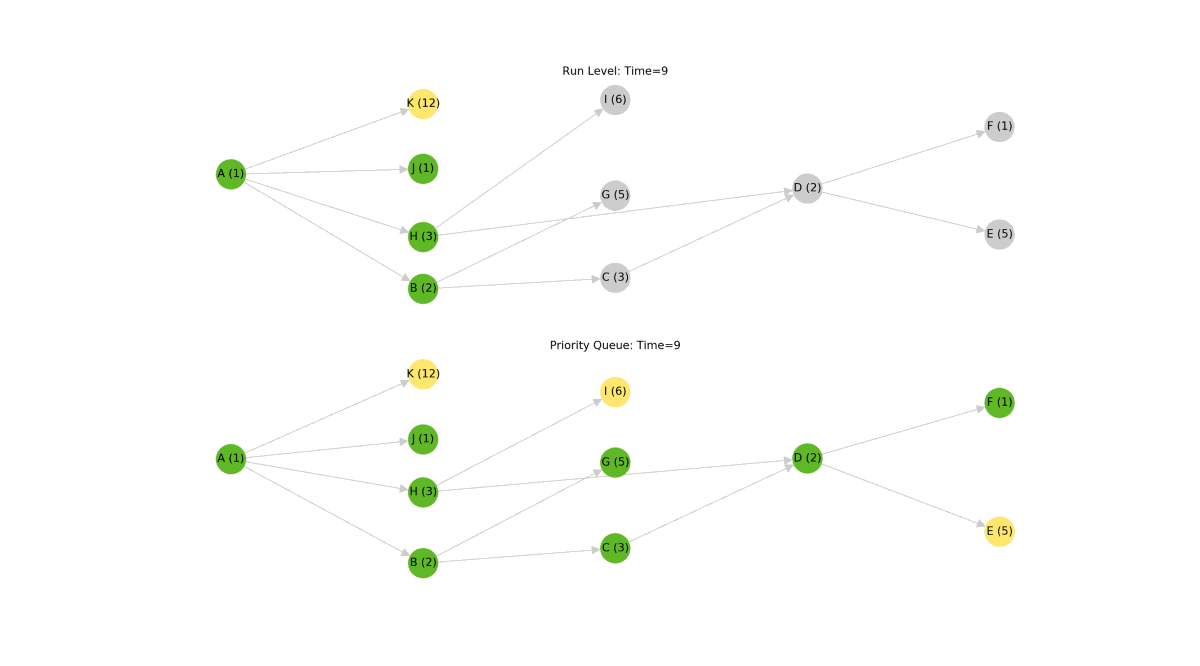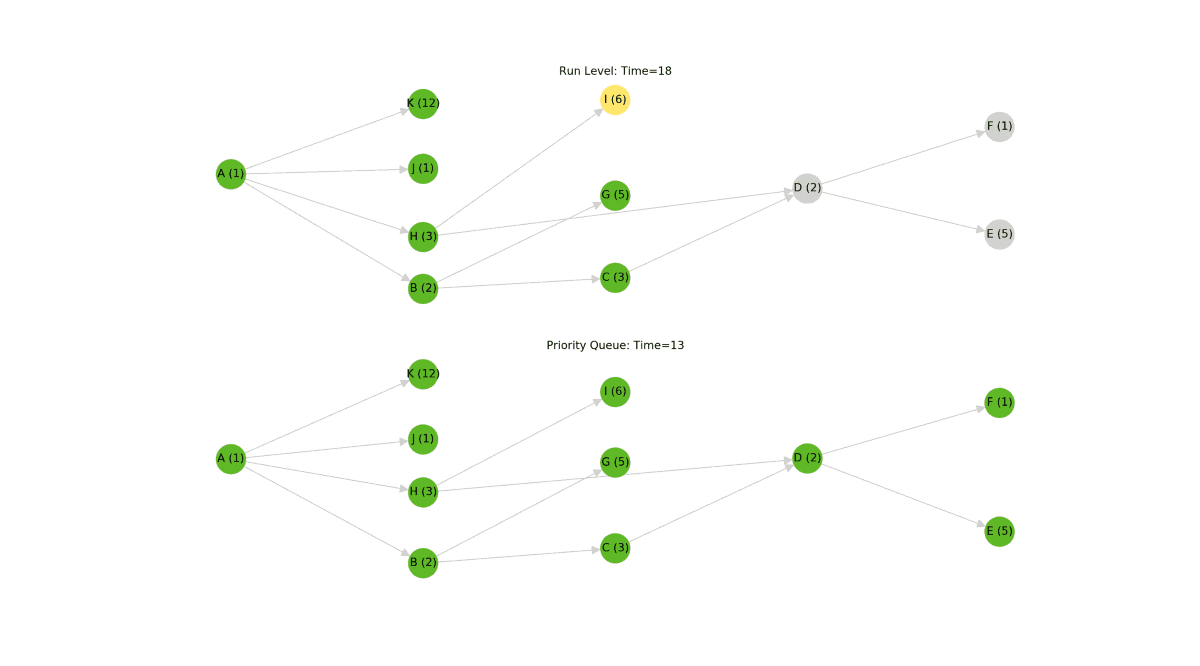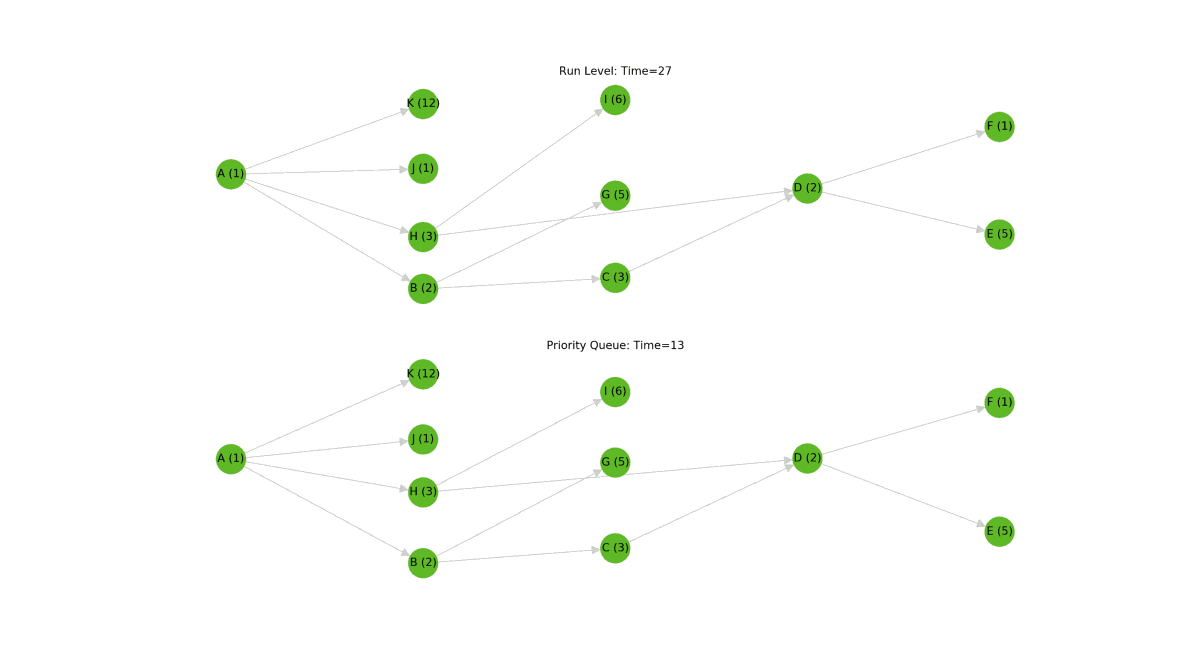
In this simulation, the new algorithm completes in about half of the time of the old algorithm. In practice, the expected performance boost probably isn't quite this drastic, but it's still a significant speedup. One thing to consider is that as the number of concurrently running nodes increases, so too does the load on the warehouse. This will likely temper the best-case theoretical improvement of the new priority queue algorithm.
The future
I've written this post for two audiences:
- The small cadre of dbt users in the world who geek out about graphs as much as I do
- Myself
In the early days of dbt, I spent most of my time thinking about graphs. I was captivated by graph algorithms and analyses, and I wondered about how dbt could use the information present in graphs to make recommendations to dbt users. Are there certain types of subgraphs that should be avoided? Can dbt recommend refactoring models which share a number of ancestors? Is there a way to detect and categorize certain types of transformations from the shape of a dbt graph? These are all interesting questions worthy of investigation.
For me, 2018 was a year of going deep on SQL and user interfaces. At this point, much of the SQL required to power dbt has been written, and we're in pretty good shape on the UX front too. In 2019, I hope to run directly at the most significant part of any dbt project: the DAG. This post is a reflection of my renewed interested, and I'm excited to share more of our thinking as it develops. If you're interested in chatting about DAGs, you should ping me in dbt slack.
Addendum
[1] Nodes in a given run level aren't necessarily "siblings" as they don't need to share a parent. More precisely: all of the ancestors of the nodes in Run Level K are present in the union of the nodes in Run Levels 0...K-1.
[2] dbt uses a priority queue to prioritize running models with the highest number of descendants first. In an ideal world, we would use the estimated "cost" (historical average runtime in seconds) of its descendants, but dbt is stateless, so dbt doesn't really have access to this information at runtime.
[3] These visualizations do not account for a specific number of threads. Any graph traversal algorithm will complete in the same amount of time if run with a single thread. The simulations shown here assume that dbt is running with enough threads to never block because workers aren't available. This is baked into the "30%" number I'm using --- the simulations in the attached notebook show closer to a 40% or 50% improvement, which is probably unrealistic for most dbt projects out there.
Published on: Jan 07, 2019
2025 dbt Launch Showcase
Catch our Showcase launch replay to hear from our executives and product leaders about the latest features landing in dbt.
Set your organization up for success. Read the business case guide to accelerate time to value with dbt.





