How dbt Can Help Solve 4 Common Data Engineering Pain Points

Last edited on Mar 10, 2025
[This is a guest post from Analytics8, a dbt Labs Preferred Consulting Partner. Learn more about the dbt Labs Partner Program here.]
Data isn’t very valuable if you can’t make it accessible—and usable—to your entire organization. Even with a clear data strategy and new technology in place, your data teams can experience several roadblocks including workflow bottlenecks, lack of trust or knowledge around the data, as well as data pipeline issues.
These pain points are common for organizations across industries, and luckily there is a tool in the marketplace—dbt—that helps to address them.
dbt Overview: What is dbt and What Can It Do For My Data Pipeline?
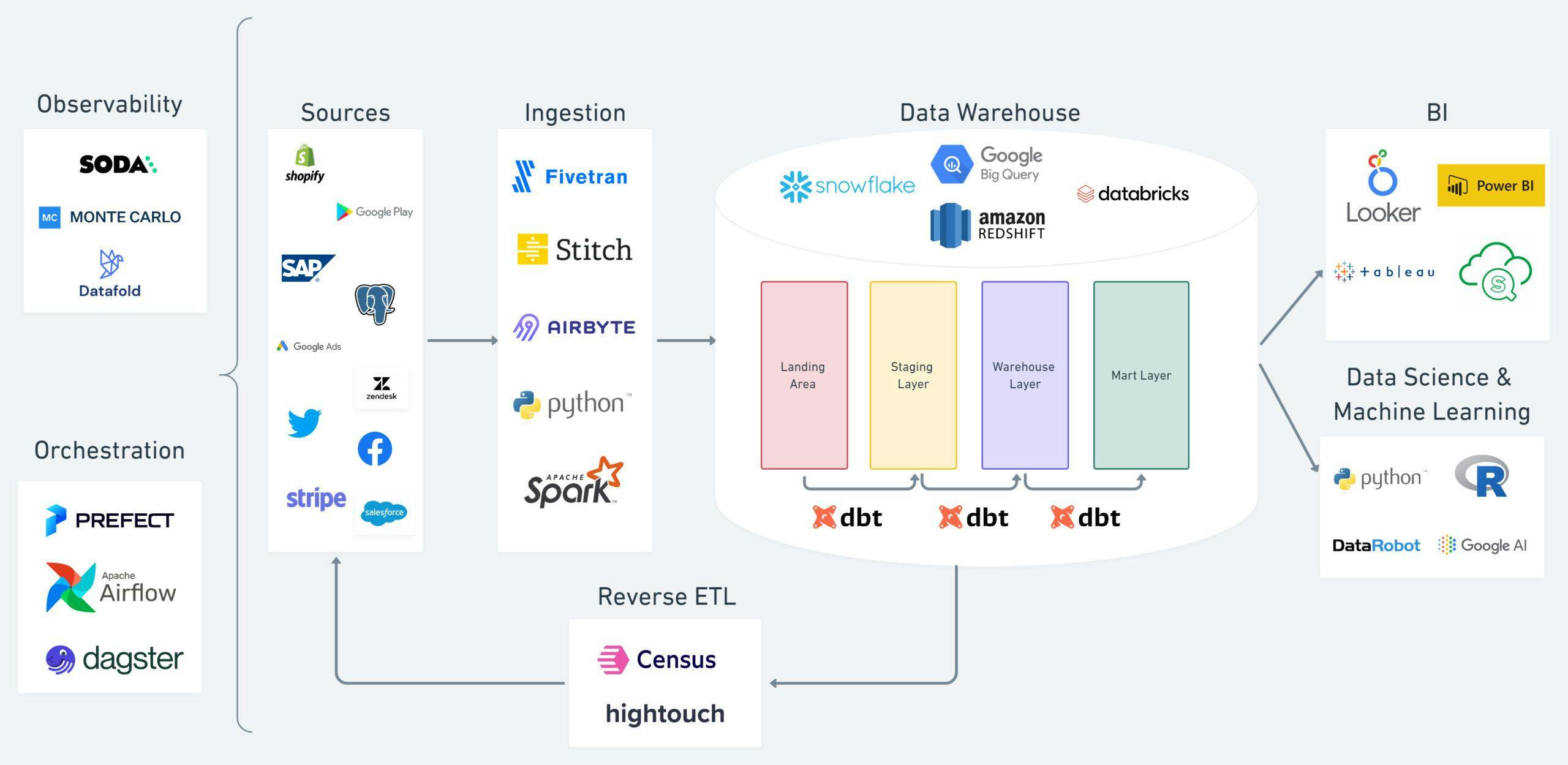
The ecosystem surrounding dbt and the modern data stack.
dbt pairs with whatever data platform or database you’re using, and it provides a framework to develop data pipelines, test and document them, and then deploy them so that the resulting data is useful to the organization for decision making. According to Ryan McGibony of dbt Labs, “The most powerful feature of the dbt framework is the workflow that it enables and the way it democratizes data pipeline development so more people in different data roles can participate in that process and do it in a way that's manageable, scalable, and robust.”
How dbt Helps Organizations Remove Data Engineering Roadblocks
dbt has been helping organizations reshape the way they model, transform, and manage their data while also enabling data teams to scale faster without reliance on data engineers. Four of our data engineering consultants discuss how the platform has helped clients navigate four common data team pain points.
Pain Point #1: Lack of centralized business logic creates workflow bottlenecks and siloed data.
Data silos—a real pain point for many organizations—can lead to unnecessary headaches for data analysts and data engineers. Often, analysts in one business unit are unable to access data from another and must rely on data engineers for on-demand solutions.
For example, an HR analyst may need sales and marketing data for a report they’re working on. In many organizations, they would need to reach out to a data engineer to build a data model, and then create a workflow to receive the data on a regular basis. Depending on available resources there could be a delay, making the data outdated and irrelevant when it finally becomes available. Or worse, it may lead to duplicate efforts if, for example, another department has already created a similar model that could have been leveraged if everything data-related was available in one centralized location.
How dbt centralizes business logic to alleviate workflow bottlenecks and avoid siloed data
dbt reduces data silos by acting as a centralized location for all transformation logic and enabling any data analyst with SQL skills to create models and leverage data across business units. Some key features include:
- Simply set up a developer account in dbt, grant access as needed, and away you go.
- The user handles the business logic, dbt does the rest.
- Models are SQL statements that are built using various dbt commands, all DDL (table creation, view alteration, etc.) is handled by dbt behind the scenes.
- Executing simple commands from within the development environment builds models within the development warehouse, enabling an analyst to quickly review the data in their personal development schema.
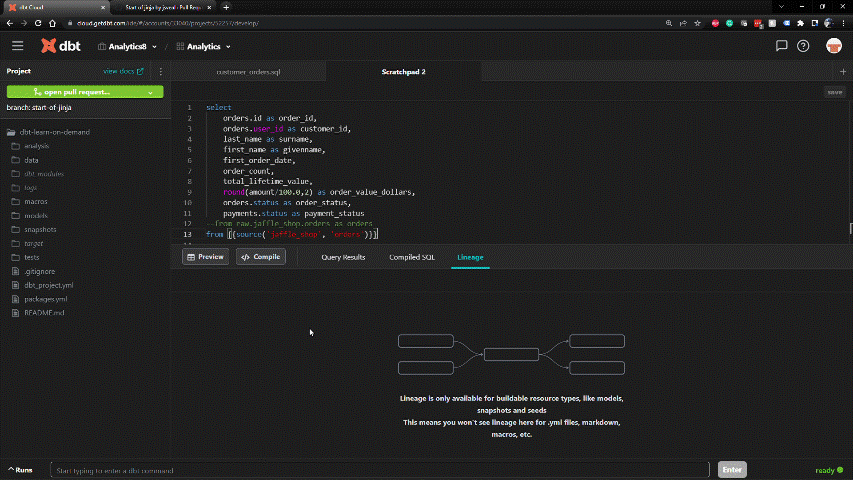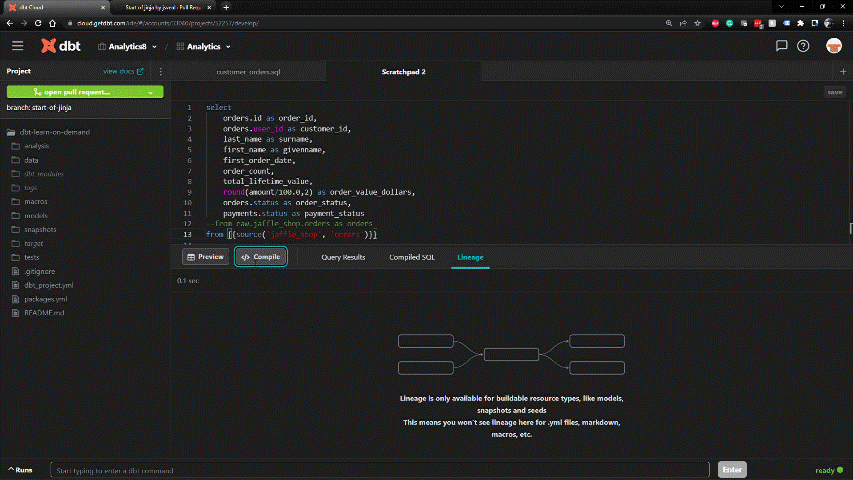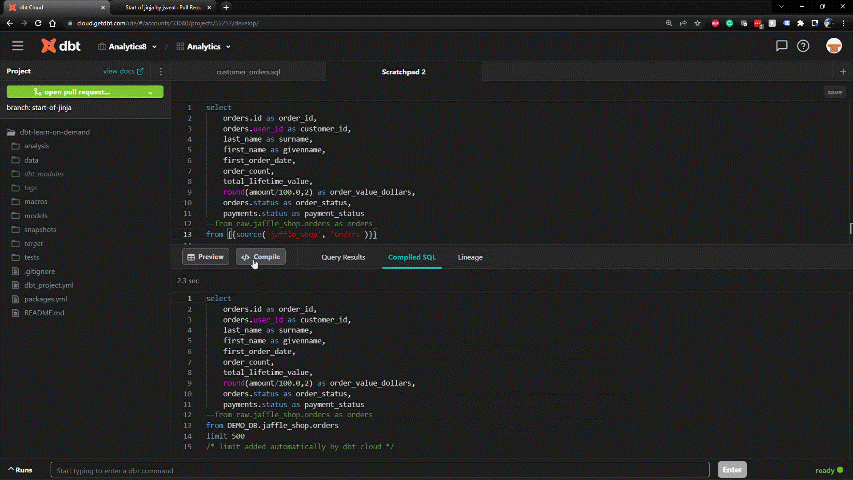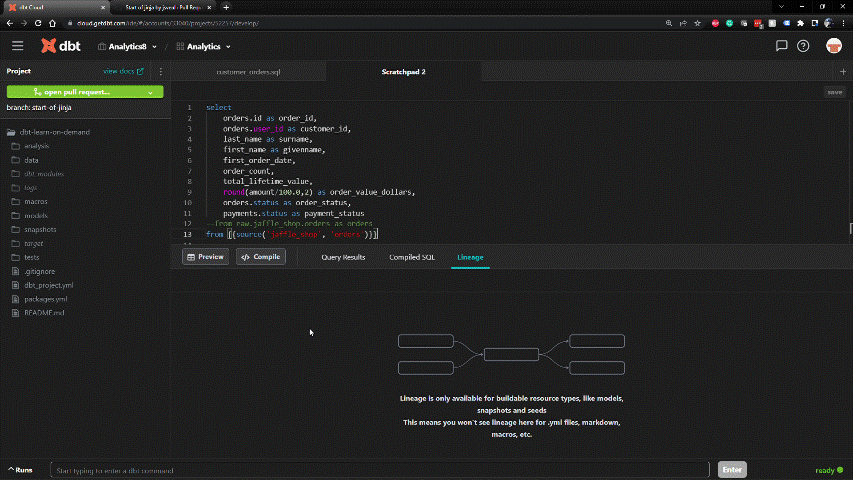
SQL-based framework within dbt enables rapid development. DDL is handled behind the scenes.
Another key feature of dbt is native version control, which guarantees a stable production environment. Native features of dbt make it simple to view model lineage, generate documentation, and see relationships between data across business units. Other features include:
- Version control via dbt's native integrations with Github, Gitlab, or Azure DevOps enable data teams to work in tandem with each other, without fear of incompatible code breaking production.
- Version control is easy to set up using an analyst’s personal Git account, with access to the organization's repository controlled by an org admin.
- Code modifications are logged in the repository, with documentation around each change, pull request and commit.
- Analysts can push finished models to review but checks and balances prevent deployment to production until compatibility with the existing codebase is confirmed.
- With multiple different users, there is peace of mind knowing rollback to a stable branch is easy in the event of failure.
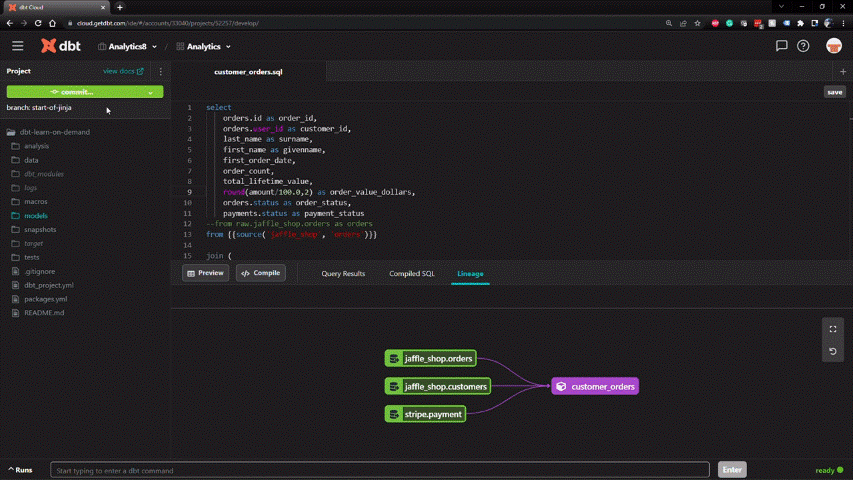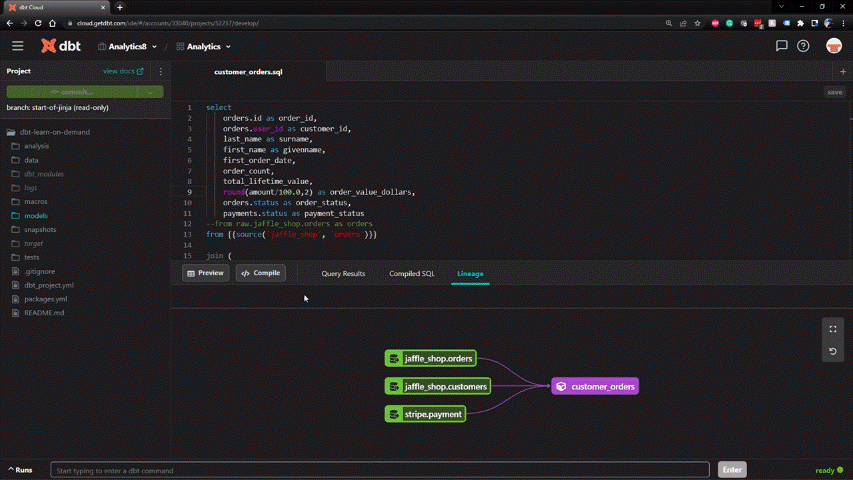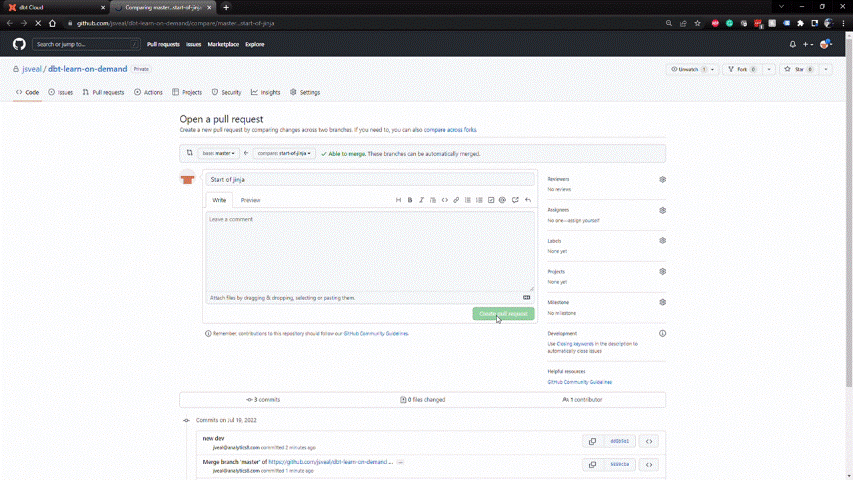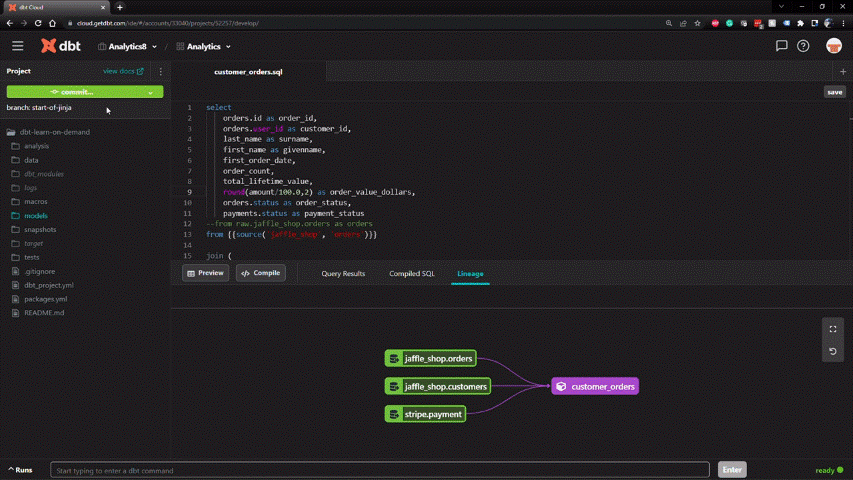
Creating a new development branch and merging with production follows an intuitive Git workflow in dbt. All code is stored in a central repository.
Watch Jordan Veal, Data Engineering Consultant at Analytics8 explain how dbt helps reduce data silos
Pain Point #2: Business users don’t know where data in dashboards came from or how to interpret it.
Another common pain point for many organizations has to do with knowledge sharing and documentation—it often takes a back seat in development but is a front and center problem when business users don’t know where data in their dashboard came from or how to interpret it.
Every organization handles documentation differently—it can be embedded in ETL tools, live in Excel, SharePoint, Confluence, etc., —or may not exist at all. A lack of centralized documentation and data lineage can be problematic for data analysts, who are responsible for sourcing data requirements to build dashboards and reports but are not involved in the data pipeline development where data transformation occurs. Data analysts run into issues including:
- Difficulty in understanding downstream dependencies and discrepancies and unable to field questions from the business about the data.
- Tracking down business logic and/or ownership of ETL logic of how data is flowing through pipeline and sometimes needing to build workarounds.
- Inability to build trust around data and provide the insights the business is seeking.
How dbt integrates documentation into your data pipelines so all users know where the data came from and how to interpret it
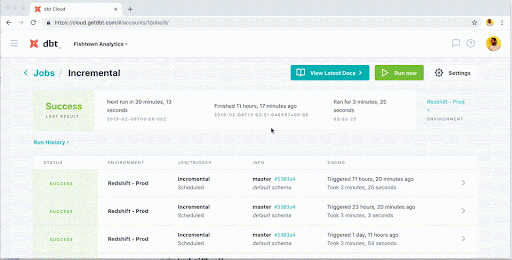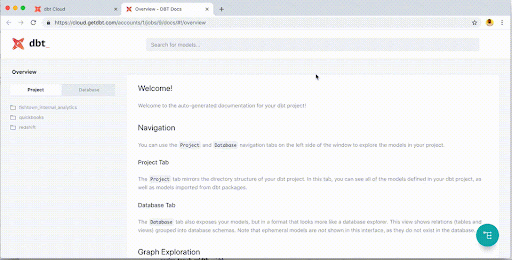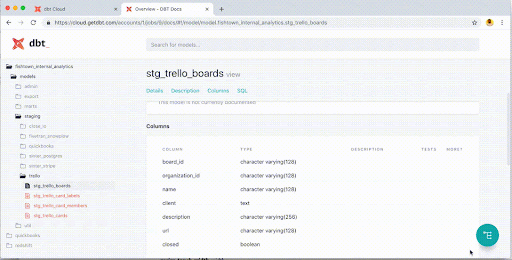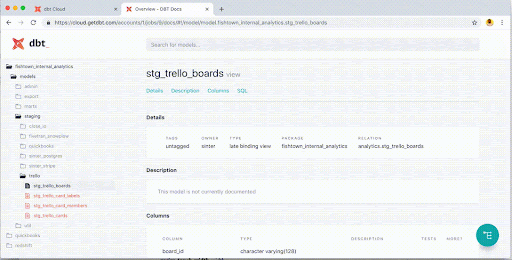
dbt brings integrated documentation to your data pipelines for all stakeholders to navigate documentation and lineage.
Bringing your data analysts into your data pipeline development brings numerous advantages to the table, especially in terms of building trust with external stakeholders—and dbt helps make that easy and possible. dbt Docs—a key feature of dbt—is a way to document your dbt models and give access to both your data analysts and business users to see how data is flowing from source systems to data marts and dashboards. Some key highlights of dbt Docs include:
- Sources are documented and profiled.
- Each step in a transformation pipeline can have an associated documentation block defining what logic is being employed.
- Maintain shared understanding of your business's data lineage. Lineage is built through references to previous transformation steps or source systems.
- Documentation and lineage are easily hosted on dbt Cloud or through your own service (cloud storage) where business stakeholders can access it (self service).
Hear from Tyler Rouze, Data Engineering Consultant at Analytics8, about how dbt’s centralized documentation and lineage build trust with all stakeholders
Pain Point #3: Data pipeline issues are discovered too late.
The lack of automated testing in your data pipeline should be an immediate red flag. There is too much that can go wrong, including:
- Delayed—or no—realization of data integrity issues.
- No alerts for source data replication failures.
- Time-consuming data validation.
- Logic changes breaking the production environment.
One very common pain point for many organizations is being slow to discover any upstream data issues flowing through your data warehouse. Too often this puts you in a reactive position and forced fire drills which can be achieved by setting up notifications with automated tests. The problem is that it can be complex to build this environment on your own.
Learn more about “How to Use Data Observability to Improve Data Quality and Ensure Proper Flow of Data”
How dbt can help with native testing and notifications so you can address problems before it’s too late
dbt comes with the following prebuilt generic tests: unique, not null, referential integrity, and accepted value testing. Additionally, you can write your own custom tests using a combination of Jinja and SQL. To apply any generic test on a given column, you simply reference it under the same YAML file used for documentation for a given table or schema. This makes testing data integrity an almost effortless process. Some key features include:
- Built-in testing which includes source freshness testing, singular tests, and generic tests.
- Source freshness and generic tests are defined in YAML, while singular tests are defined by writing a SQL statement in the test directory of your project.
- dbt cloud also offers automated email notifications, which can work extremely well to uncover issues early.
Watch John Barcheski, Data Engineering Consultant at Analytics8, discuss how dbt’s built-in testing helped his client uncover issues before they became problems
Pain Point #4: It’s difficult to deploy data pipelines and keep them updated over time.
Most data transformation tools require you to develop and maintain a self-hosted CI/CD pipeline. It takes a significant amount of time to plan, develop, and maintain these pipelines and often, you can run into issues when you scale, or when your technology changes. It doesn’t take much to strain a self-hosted CI/CD pipeline—anything from growing data and source code volumes, increasing involvement of non-data-team users, or even pressure for faster iteration can tip it over the scale and make it difficult to deploy data pipelines and keep them updated.
This can result in pushes to production being delayed, and sometimes even breaking dependent tables on the next production job run, which means stale data.
How dbt can help with deploying data pipelines and keeping them updated.
dbt has built-in CI/CD features that require minimal to no development and maintenance. It is easy to configure and constantly being improved by dbt as the technology changes. Key features include:
- dbt Cloud integrates with git providers like Github so that you can have automated checks that run and test your data when you open a Pull Request.
- Using webhooks or APIs, a dbt Cloud CI job is kicked off with Slim CI which runs and tests only the models that are impacted by the changed code. This includes the model that you changed and the downstream dependencies as well. This is easily done because of the lineage that is defined when developing in dbt.
- Automated tests can also be run in the CI job which gives you further confidence that the changes you are making will not break your production jobs and the data maintains its quality.
- A serverless infrastructure—everything is configured in dbt Cloud and run in your data warehouse.
- dbt integrates with other tools including SQL Fluff, which is a SQL linter that can integrate with dbt Cloud so that the SQL code that is being pushed to production follows a certain format. This is extremely beneficial for growing teams or large teams as it can be hard to maintain consistently formatted code.
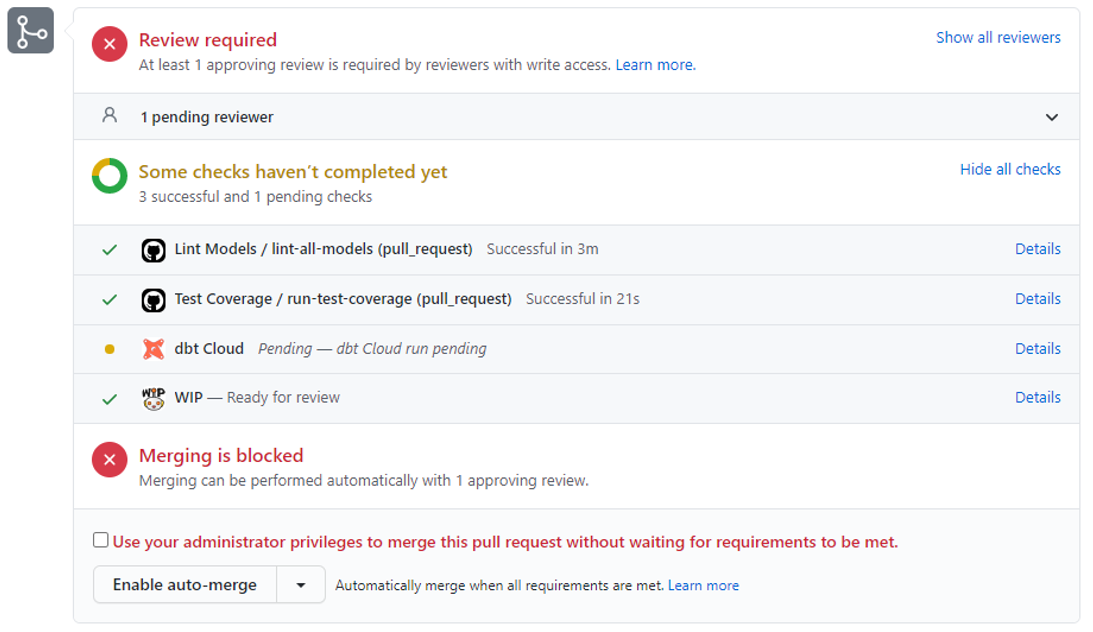
A Github pull request showing the integration with dbt Cloud.
With dbt Cloud’s built-in CI/CD features, your team does not need to worry about developing and maintaining a CI/CD pipeline, can significantly speed up the process with slim CI, and get your code to production faster and with confidence. As your team and code base grows, you don’t have to worry about scalability of a self-hosted CI/CD pipeline.
Hear from Erin Barnier, Data Engineering Consultant at Analytics8, about the ease of configuring dbt Cloud’s CI/CD features
How dbt Fits into the Modern Data Stack and What It Brings to Your Business
dbt is cloud agnostic and sits on top of your data warehouse, offering flexibility for your data stack. It also offers a multitude of connectors to various tools—bringing together your data transformation development into one place and providing your data team with an understanding of how data flows through your organization—ultimately ensuring trust in the data and enabling better decision-making across the business.
Watch Tyler Rouze discuss how dbt fits into the modern data stack
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




