

Last week, Fishtown Analytics turned three years old. This is an exciting milestone for us, and our journey to-date is best summarized by a graph that you may have seen before:
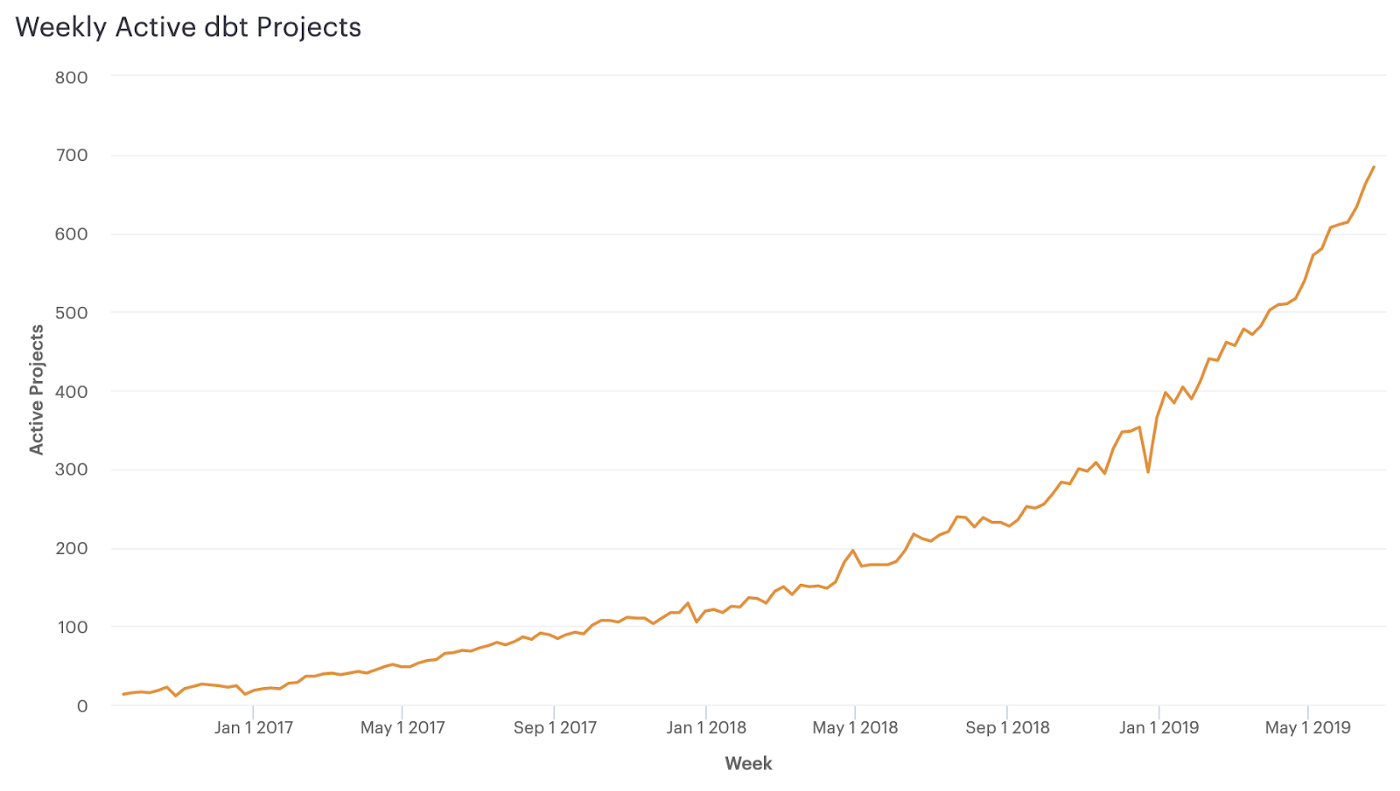
The "up-and-to-the-rightness" of this graph is exciting and validating and meaningful to every one of us at Fishtown Analytics. It's a great indication that we're making progress on our mission to elevate the analytics profession. If we allow ourselves to extrapolate from this line, we can consider what the future of dbt might look like and the ways in which it may need to change. If we're going to continue to elevate the analytics profession, then we need to make dbt more accessible to the power users of the future --- data analysts.
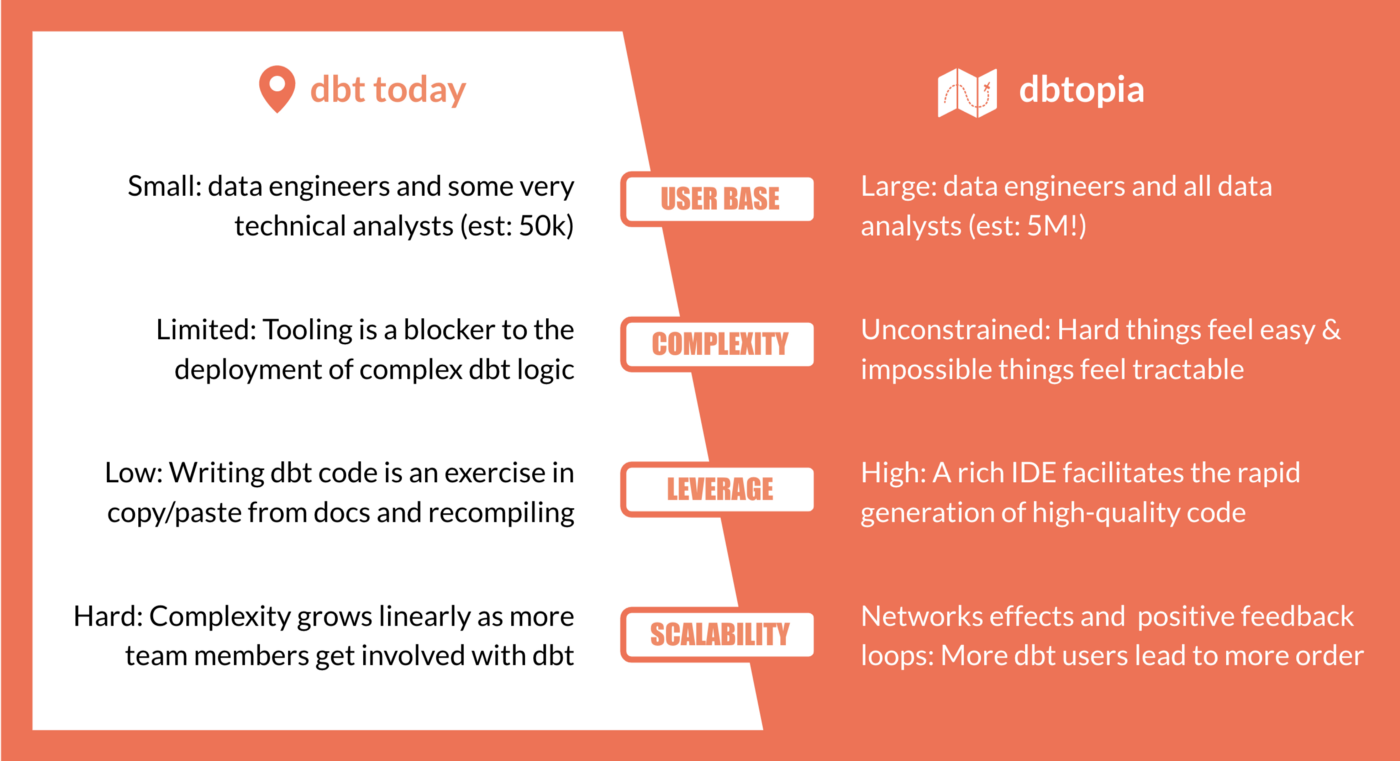
Bringing the benefits of dbt to more people
dbt today is an amazingly powerful tool for people whose brains are already wired to do things "the dbt way". We joke that dbt ships without batteries included: users need to come prepared with pretty serious knowledge of git, bash, and Python environments in order to be fully productive with dbt, or they need to learn how to use these tools fast. In some ways, this is a good thing. We believe that teams that apply software engineering methodologies to analytics tasks are higher performing than those that do not. In other ways though, these prerequisites often prove to be exclusionary to even talented analysts.
Only a tiny fraction of the human beings conducting analytics in the world today have already developed a mastery of tools like git and bash. These people are progressive data engineers and highly technical data analysts, and they represent maybe 1% of the overall segment of analytics professionals out there. To this broader group of analysts in the world, the tooling that dbt is built around looks more like a roadblock than an express lane.
We want to make it easier for new analysts in the space to master the dbt learning curve, and the way we're going to do this is by leveraging user interfaces in dbt Cloud. Future cohorts of dbt users will get up and running without navigating pip or homebrew. They will configure their database connections with user interfaces, and they won't edit yaml files in hidden folders in their home directories, at least to start. As these users become more familiar with dbt, it may become useful for them to break out of these user interfaces and use tools like git directly on their local machines. These users will be set down a path which encourages them to master these tools, but we will not insert them as roadblocks into the onboarding processes.
We can, and must, implement these changes without diluting the potency of dbt. We're totally uninterested in building a tool which sacrifices our values in order to grow usage. Rather, we recognize that we can better contextualize the benefits of effective version control, local development workflows, and a mastery of the terminal by creating a sensible upgrade path for users that are new to software engineering environments.
Managing complexity in dbt projects
dbt's approach to data modelling is inherently flexible: there are innumerable ways to configure dbt projects, and repeated code is frequently encapsulated into potentially long chains of complex macros. Custom materializations allow users to fundamentally change the way that dbt operates under the hood, and dbt's new operations allow for asynchronous maintenance tasks to be templated and shared across teams.
This flexibility makes it possible to encode really complex business logic in dbt projects, but it can also make it hard to enforce standards and maintain code quality in large projects. In the future, dbt will make it easy to build tools that hook into its code development, compilation, and execution pipelines. These hooks will be the substrate upon which a whole ecosystem of tooling can be built. These hooks will make it possible to lint and format dbt code, generate test coverage reports, and more. Some teams are already building tooling like this, but we can do so much more to make it a first-class endeavor.
Working with leverage
Developing dbt models today can be a painful experience: this process involves switching back and forth between source code and compiled artifacts, tailing logs, and copy/pasting code between your text editor and SQL runner. This isn't necessarily hard work, but it is time consuming and error prone. A better dbt workflow would provide leverage: users would be able to do better work with less effort.
In the future, we will provide a first-class Integrated Developer Environment (IDE) that facilitates the development of high-quality dbt code. This editor will be tailor-made for the development of dbt projects --- it will have a baked-in understanding of the models and macros defined in dbt projects and the variables and functions available in dbt's compilation context. Further, this editor will take the effort out of implementing dbt's best-practices: it will natively support the specification of model documentation and schema tests, and it will tie in with the tooling that exists around dbt.
Network effects, not growing pains
Over the past year, we've seen a number of large organizations integrate dbt into their data stacks. Excitingly, these organizations are using dbt to empower their analysts. While we're thrilled that this is happening, we also recognize that scaling dbt to a broader team can be challenging. Installing dbt across various operating systems, synchronizing dbt versions, and enforcing coding conventions all add friction to the process of scaling out a dbt deployment to a large team. This is the exact opposite of how this should feel: each additional dbt user should increase the net value of the system, not detract from it.
In the future, each additional dbt user will produce positive network effects for the health of an organization's data practice. Onboarding new users to an existing project will be quick and simple, and these new users will quickly be able to get up and running with development of the project with ease. This new world will be a manifestation of the developments shared above: easier setup, better tooling, and a capable IDE are all going to be necessary to effect this kind of organizational change at scale.
Introducing dbt v0.14.0
Today, we're releasing dbt v0.14.0. This release lays the foundations for the future that we want to materialize. This release comes equipped with a dbtserver that can run code in the context of a dbt project. The dbt server can run queries which include references to sources, models, and macros. This long-lived server makes it possible to build new interfaces into dbt projects which extend beyond the command line.
To this end, we're also making dbt Develop generally available to dbt Cloud customers. dbt Develop is a query editor which leverages the brand new dbt server. With dbt Develop, analysts can develop models and macros interactively in the browser. dbt Develop represents a great first step in the direction of helping analysts work with leverage, and we're excited to continue to invest deeply in it over the months to come. In the future, this editor will support workflows for creating, modifying, and running dbt projects in a version-controlled manner.
The dbt server is open source (Apache 2.0 licensed) and we hope you give it a look! We wanted to put this server out into the world early, but we certainly have more work to do here too. In the future, we will extend this server to run models, tests, and other dbt resources over the network.
Our plans for the future are ambitious, but we're well suited to make our vision a reality. A fourth full-time engineer is joining our team later this month, and we have plans to continue to grow this team into the future.
Finally, thanks to the 13 of you who made a Pull Request (or three) during the 0.14.0 development cycle! We've just updated our contributing guide: if you're interested in getting involved with the development of dbt, I'd love to hear from you in Slack :)
Published on: Jul 10, 2019
2025 dbt Launch Showcase
Catch our Showcase launch replay to hear from our executives and product leaders about the latest features landing in dbt.
Set your organization up for success. Read the business case guide to accelerate time to value with dbt.





