Write once, query anywhere with the dbt Semantic Layer

Last edited on Oct 15, 2024
We’re gearing up to launch the dbt Semantic Layer in Public Preview this coming October at Coalesce. With the dbt Semantic Layer, you can define core business metrics once under version control, then query them from anywhere. Callum McCann, dbt Labs Developer Advocate, wrote a companion post to help you get started with dbt metrics, but I wanted to take this opportunity to share more on what we’re building, who we’re building it for, and how we think the end result will bring a new level of collaboration and coherence to the modern data stack.
Creating consistency
I remember my first OLAP cube. Tristan, Jeremy, and I were working on a consulting project in 2017 and we were trying to wrap our heads around consistent reporting for core business metrics. We landed on an approach—basically an OLAP cube—in which we built dbt models to aggregate business metrics up to a daily grain, then unioned them together into a big table called “analytics.metrics”. To query for a metric value on a particular day, you’d run a query like:
select *
from analytics.metrics
where metric_name = 'dbt_cloud_weekly_acIt was the right idea with the wrong implementation. We were seeking consistency and precision for these core metric definitions—a noble goal—but pre-aggregated metrics via dbt models have tragic limitations around flexibility and reporting. We had to make unpleasant tradeoffs between dimensionality (how deeply can you slice & dice a metric) and usability (how intuitive is the resulting metrics table to query) and could never really nail the implementation. That didn’t stop us from building our own metrics table for our own internal business metrics though – the value of consistency and precision for these crucially important metrics was large enough to outweigh the costs of our approach.
Right idea, wrong time:
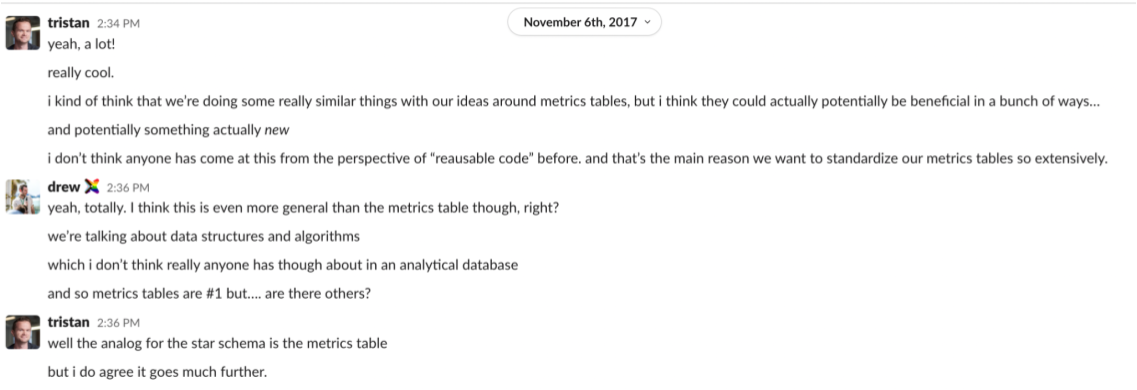
Having it both ways
In data mostly everything is a tradeoff. The question we’re trying to answer with the dbt Semantic Layer is: what if you didn’t have to choose between precision and flexibility? What kind of data infrastructure would make it possible to define business metrics under version control without losing dimensionality (or dealing with an explosion of it!) via pre-aggregated tables in a data warehouse? And further: how do we make this infrastructure easily pluggable and compatible with the wealth of existing data tools that already know how to query data warehouses?
The approach we’ve landed on is pretty clever. Callum’s blog postngets into the details, but at a high-level, we’re bringing the OLAP cube to the Cloud Data Warehouse era. Internally, we’re using dbt metrics to track and report on our company-level OKRs. This means that every Key Result definition is versioned and any logic changes to a metric definition will be propagated out to all of the different data tools that we use internally.
Here’s what it feels like to query for a metric value as a time series today:
select *
from {{ metrics.calculate(
metric('dbt_cloud_weekly_active_users'),
dimensions=['country'],
grain='day'
) }}If you’ve written dbt code before, this should look familiar: it’s just a SQL query that calls a macro named calculate in a package called metrics. We’ve made this experience possible by building some new and foundational data infrastructure (a dbt Server + a rewriting SQL proxy) which can live-compile queries en route to a data warehouse. Note that no aggregated metric data is materialized in the data warehouse in this approach. Instead, we live-compile a metrics query which calculates dbt_cloud_weekly_active_users based on the version-controlled metric definition that lives in our dbt project! Here’s how that feels in practice today:
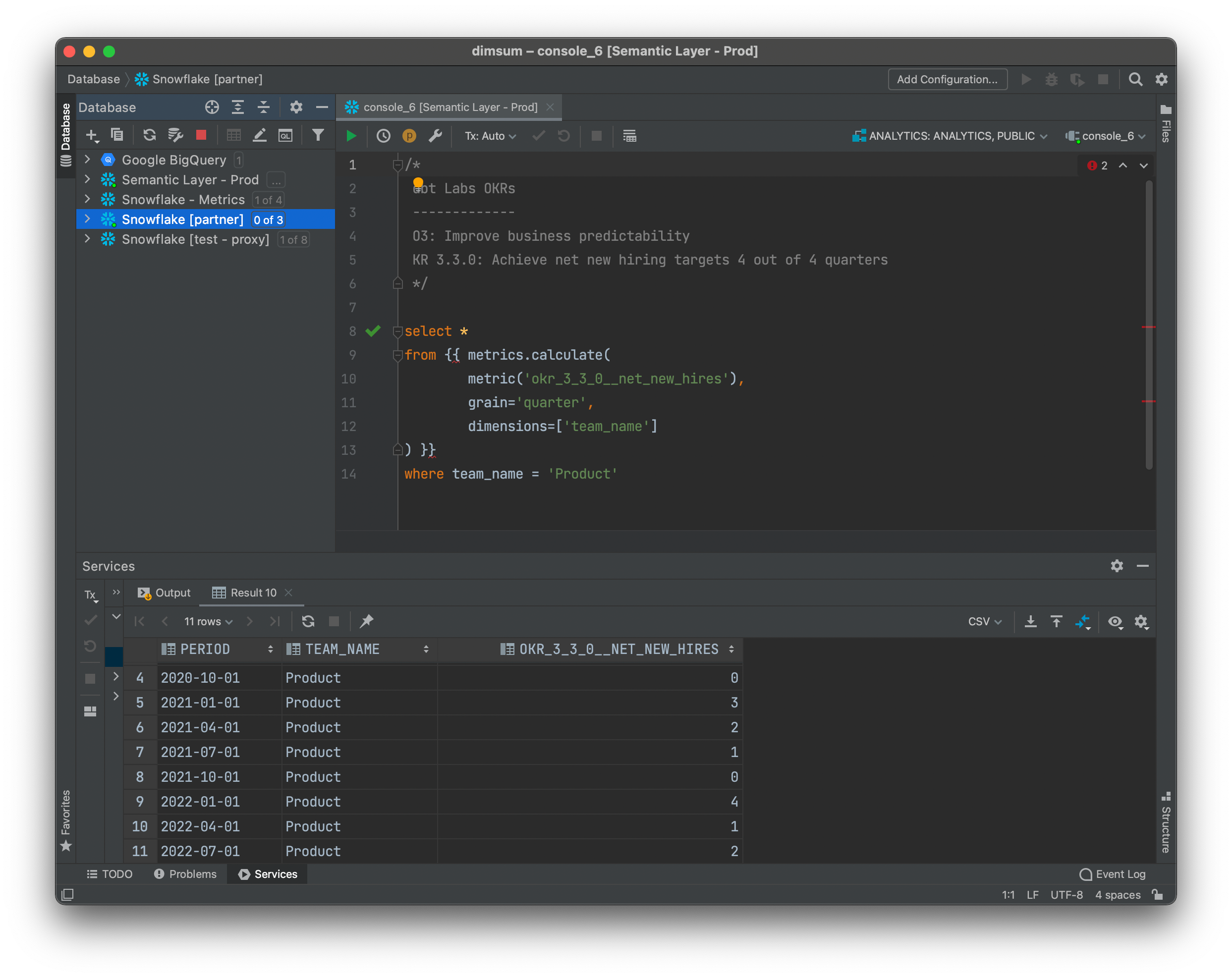
Metrics! Precise, flexible, and accessible with consistency and precision in the tools that you know and love on day one.
Integrations
The impacts of this system are far-reaching. dbt participates in an ecosystem of interoperable tools (sometimes called the modern data stack) which represent a best-of-breed approach to building a functional analytics practice. While there are many benefits of a decentralized data stack, it can also serve to fragment business logic and mask dependencies between systems. We are missing a layer of the stack that can bind these tools together around shared definitions for core business entities, relationships, and metrics.
To fix this, we’re working on deep dbt Semantic Layer integrations with design partners focused on BI, Data Science, data loading, and other types of warehouse-connected data applications. In short, the dbt Semantic Layer is acting as the glue that binds these best-of-breed data tools together into a more unified, less fragmented stack. It’s a vision of the future that we’re tremendously excited about, but it will take time to realize it in its entirety.
Beyond metrics
Today, dbt knows a lot about the graph of transformations that produces your data models, but it knows very little about how these tables relate to each other. Sure, dbt can build both the fct_transactions and dim_customers models, but shouldn’t it also know that they join together on the customer_id column? And couldn’t it also expose that information to your BI tool, your data catalog, and other warehouse-connected data apps? This is the specific interface that we’re driving towards with the launch of the dbt Semantic Layer. Here, the word “semantic” refers to the working knowledge of the individual puzzle pieces of the system (tables and views) and how they fit together (entities and metrics).
The realization of this vision will help improve precision and consistency while expanding flexibility and capability in the modern data stack. It will do this by lowering the barrier to entry for new tooling (step 1 of onboarding is no longer “redefine your data model”) and allowing data tools to focus on their unique value propositions instead of creating myriad workflows to support the redefinition of core business metrics and well-understood semantic entities.
We are not the first people on the planet to imagine a semantic model for data! There are a few analytics products which support the creation and exploration of semantic models already. Both Looker (via LookML) and PowerBI (via DAX/MDX) provide comprehensive and battle-hardened semantic models, but neither plays nicely with other analytics tools in the space. We think that for a semantic layer to be maximally useful, it must integrate with many different tools and be - in a word – headless. We think that dbt is exceptionally well placed to occupy this space given that it is:
- open source in nature
- independent and ubiquitous in the modern data stack
- buttressed by a vibrant and healthy community that can help steward its future development
How you can help
We have a lot of respect for this problem space and we’re not going to be able to realize this vision overnight. Our first step here — the launch of the dbt Semantic Layer — is coming this October at Coalesce. The initial cut of metrics will likely not support full semantic relationships (joins between models, virtualized dimensions, etc), but this is the direction that we’re most interested in taking the Semantic Layer long-term.
But, we’re going to need your help to get there! Many of you have already submitted this dbt Semantic Layer Beta Signup Form, though you probably haven’t heard back from me yet! We are excited to start opening up private betas of these dbt Semantic Layer integrations in the coming weeks and will be reaching out to some of the folks on this list shortly. In the meantime, keep the good ideas and hot takes coming in the #dbt-metrics-and-server channel in dbt Slack. We’re always excited to hear from you and can’t wait to show off what we’re building.
Changelog:
- July 2022: Clarified in the first sentence that the dbt Semantic Layer launch in October will be in Public Preview.
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




