

Today I’m pleased to announce the General Availability of our newest adapter in dbt Cloud: Starburst.
Connectors such as this one are purpose-built to allow dbt Cloud to connect to and run against specific data platforms, and they’re a critical component to the overall dbt workflow.
The new Starburst adapter, which is also compatible with Trino, will make it possible to create transformation logic in dbt Cloud that’s pushed down to multiple different data stores, all from a single dbt project – no data movement required.
The centralization challenge
Imagine you’re an analytics engineer in your first month at a large retail company.
You’ve been hired to help measure the success of a new product line. You’re familiar with the space, you’ve already formulated several ideas on how to approach the problem, and you’re eager to sink your teeth into it.
But as you get access to dbt Cloud and your data warehouse to start exploring the data model, you soon start to learn that:
- While your new team’s stack uses cloud Warehouse X, it’s brand new to the team.
- In fact, much of the data still lives in Warehouses Y and Z (the latter of which happens to be on-prem).
- Your analysis will also depend heavily on data that lives in another team’s data lake, to which you don’t currently have access.
Where do you, a fresh analytics engineer, even start?
We’ve heard stories like the above time and time again. While centralization on a single data platform is a noble and important goal, in practice it can be challenging to achieve for larger enterprises with sprawling technology across multiple business units. When it does happen, it can often take months or even years of tedious work.
In the past, there hasn’t been an ideal way to take advantage of the benefits of dbt Cloud in such complex multi-platform scenarios. But today, that is changing.
Starburst and dbt Cloud
Starburst mitigates this issue by making it possible to federate data queries across multiple data stores from one central plane. By connecting to it, users of dbt Cloud can now write queries that join data from different data stores in the IDE: that includes data warehouses, data lakes, object storage, streaming databases, and more.
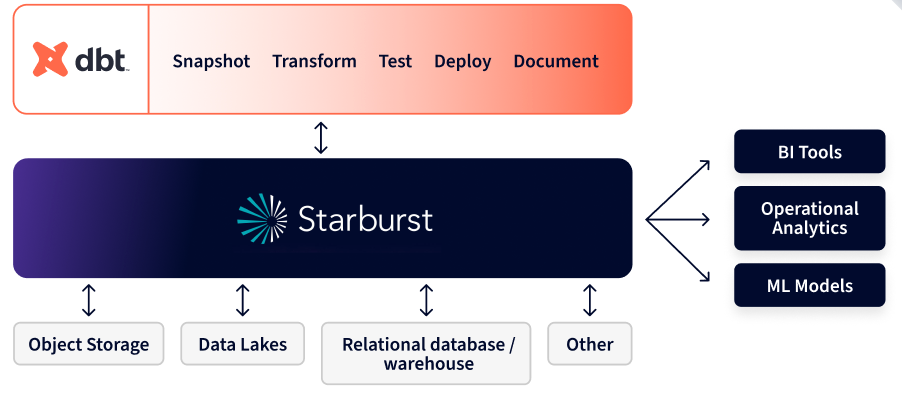
We’ve been working with the Starburst team to bring this to life for several months, and are thrilled about the possibilities it’s going to unlock for joint customers.
This adapter is maintained by the Starburst team as part of our recently launched dbt adapter Verification Program. It’s met a stringent bar for quality, and you can use it with confidence that it will be continuously updated to support new constructs or features that Starburst may introduce in the future.
The new connection option will be a big help for many large organizations dealing with the complexity of scaling data teams. In fact, for some customers, federating queries from a single platform is a first step towards teams taking control of their data at the domain level – a future that dbt Labs is highly aligned with.
Getting started
To get started, simply select Starburst as your connection of choice when creating a new dbt Cloud project.
You'll need to specify the cluster, the default output catalog, and your user credentials. After this initial setup, you’ll have unlocked the ability to join from multiple data stores using simple select statements:
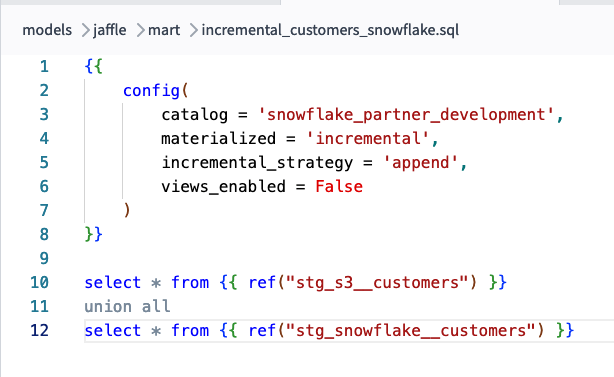
For more guidance, you can also explore our new quickstart guide for Starburst Galaxy or check out the more in-depth Starburst and Trino Configuration docs.
And if at any point along your journey you think you might find it helpful to get some more help, or just hang out with others in the same boat, don’t hesitate to drop into the #db-starburst-and-trino channel in dbt Slack.
Published on: Apr 26, 2023
2025 dbt Launch Showcase
Catch our Showcase launch replay to hear from our executives and product leaders about the latest features landing in dbt.
Set your organization up for success. Read the business case guide to accelerate time to value with dbt.





