Data transformation: The foundation of analytics work

Last edited on Oct 08, 2024
Data transformation is a key component of the ETL/ELT process where the “T” represents the data transformation stage, and is typically performed by the analytics engineer on the team or, depending on the organizational structure and needs, data analysts or data engineers.
Without data transformation, analysts would be writing ad hoc queries against raw data sources, data engineers will be bogged down in maintaining deeply technical pipelines, and business users will not be able to make data-informed decisions in a scalable way.
As a result, data transformation is at the heart of a business: good transformation creates clear, concise datasets that don’t have to be questioned when used, empowers data analysts to take part in the analytics workflow, and presents a series of challenges that keeps analytics work interesting 😉
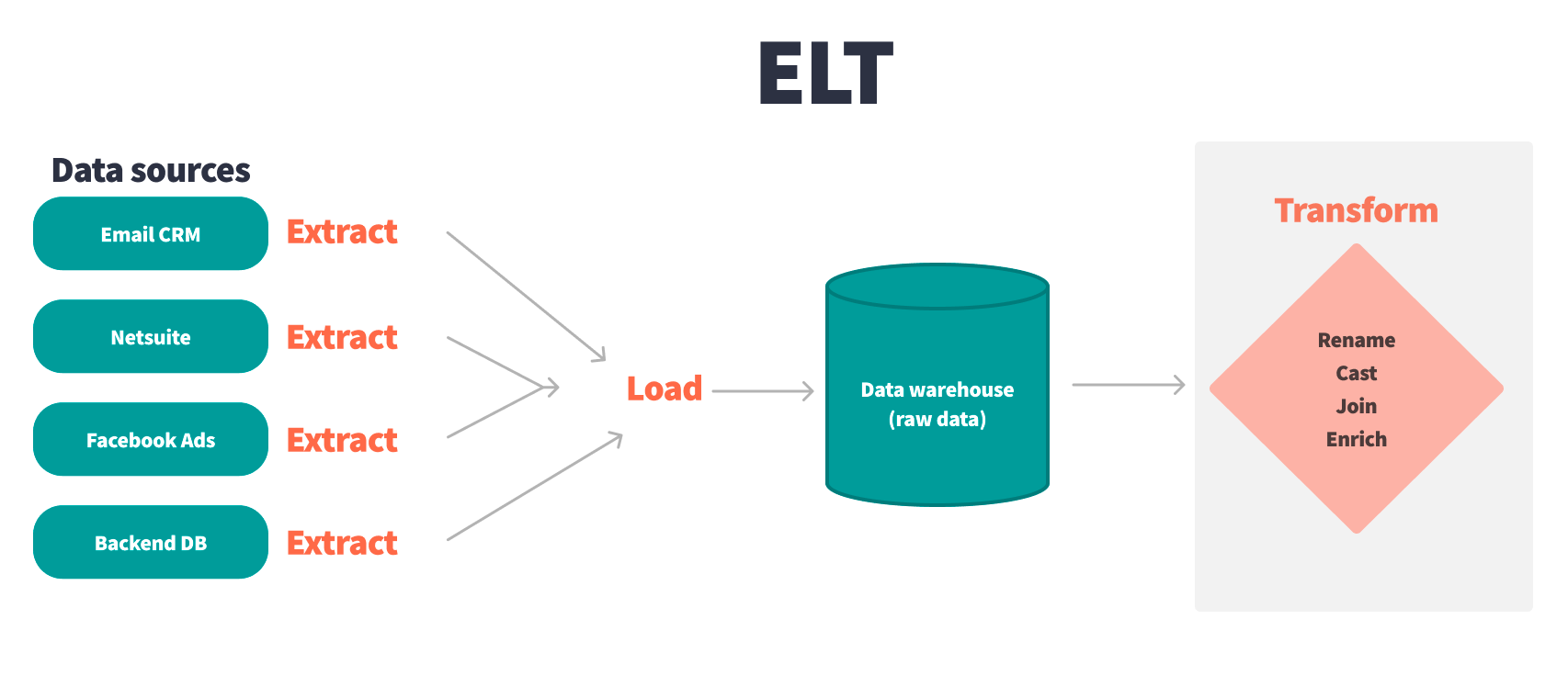
What is data transformation?
Data transformation is the process of taking raw source data and using SQL and Python to clean, join, aggregate, and implement business logic to create important datasets. These end datasets are often exposed in a business intelligence (BI) tool and form the backbone of data-driven business decisions.
Benefits of data transformation
Why is data transformation the foundation for modern data analytics? Because it’s the baseline for increasing the data quality of your business and creating meaningful data for your end users.
Increases data quality
Data transformation can increase data quality through the process of standardization, testing, and automation. During the transformation process, raw data is cleaned, casted, converted, joined, and aggregated using SQL and Python to create end datasets that are consumed by business users. In an ideal world, these transformations are version-controlled and peer-reviewed. This transformation process should also follow automated testing practices, ultimately creating tables data analysts and end business users can trust.
By transforming your data with tooling that supports standardization, version control, integrated documentation, modularity, and testing, you leave little room for error. Data analysts don’t need to remember which dataset is in which time zone or currency; they know the data is high-quality because of the standardization that has taken place.
In addition to standardizing raw data sources, metrics can be properly created during the transformation process. dbt supports the creation of metrics and exposing them via the Semantic Layer, ultimately allowing you to create and apply the same metric calculation across different models, datasets, and BI tools, ensuring consistency across your stack. As you develop consistent metric definitions, your data quality increases, trust in your data work increases, and the ROI of a data team becomes much more apparent.
Creates reusable, complex datasets
Data transformation allows you to automate various data cleaning and metric calculations. This ensures consistent, accurate, and meaningful datasets are being generated in the data warehouse each day, or on whatever time cadence your business chooses. By automating certain data models, data analysts do not need to repeat the same calculations over and over again within the BI layer. These data sets can be referenced directly within a report or dashboard instead, speeding up compute time.
Data transformation also activates the reverse ETL process. Transformation allows analytics engineers to join different datasets into one data model, providing all the needed data in one dataset. Because datasets are being automated using data transformation, this data can be ingested into different reverse ETL tools, giving stakeholders the data they need, where and when they need it.
Challenges of data transformation
Data transformation is fun, but tough work for analytics practitioners. The difficulty often varies given the complexity and volume of your data, the number of sources you’re pulling from, and the needs of your stakeholders. Some of the biggest challenges you’ll face during the data transformation process are: creating consistency, standardizing core metrics, and defining your data modeling conventions.
Consistency across multiple datasets
During the transformation process, it can be challenging to ensure your datasets are being built with standardized naming conventions, following SQL best practices, and conforming to consistent testing standards. You may often find yourself checking if time zones are the same across tables, whether primary keys are named in a consistent format, and if there’s duplicative work across your data transformations.
How you determine what consistency and standardization look like in your data transformation process is unique to your team and organization. However, we recommend using a tool, such as dbt, that encourages data transformation DRYness and modularity, code-based and automatic tests for key columns, and explorable documentation to help you keep consistent and governable data pipelines. Here are some other dimensions you should keep in mind when trying to create consistency in your data:
- What timezone are your dates and timestamps in?
- Are similar values the same data type?
- Are all numeric values rounded to the same number of decimal points?
- Are your column names named using the same format?
- Are all primary keys being regularly tested for uniqueness and non-nullness?
These are all different factors to consider when creating consistent datasets. Doing so in the transformation stages will ensure analysts are creating accurate dashboards and reports for stakeholders, and analytics practitioners can more easily understand the requirements to contribute to future transformations.
Defining data modeling conventions
Defining data modeling conventions is a must when utilizing data transformation within your business. One of the reasons data transformation is so powerful is because of its potential to create consistent, standardized data. However, if you have multiple analytics engineers or data analysts working on your data models, this can prove difficult. In order to create high-quality, valuable datasets your data team must decide on style conventions to follow before the transformation process begins.
If proper style guidelines are not in place, you may end up with various datasets all following different standards. The goal is to ensure your data is consistent across all datasets, not just across one engineer’s code. We recommend creating a style guide before jumping into the code. This way you can write all of your standards for timezones, data types, column naming, and code comments ahead of time. This will allow your team to create more consistent, scalable, and readable data transformations, ultimately lowering the barrier for contribution to your analytics work.
Standardization of core KPIs
A lack of consistency in key metrics across your business is one of the largest pain points felt by data teams and organizations.
Core organizational metrics should be version-controlled, defined in code, have identifiable lineage, and be accessible in the tools business users actually use. Metrics should sit within the transformation layer, abstracting out the possibility of business users writing inaccurate queries or conducting incorrect filtering in their BI tools.
When you use modern data transformation techniques and tools, such as dbt, that help you standardize the upstream datasets for these key KPIs and create consistent metrics in a version-controlled setting, you create data that is truly governable and auditable. There is no longer a world where your CFO and head of accounting are pulling different numbers: there is only one world where one singular metric definition is exposed to downstream users. The time, energy, and cost benefit savings that comes from a standardized system like this are almost incalculable.
Data transformation tools
Just like any other part of the modern data stack, there are different data transformation tools depending on different factors like budget, resources, organization structure, and specific use cases. Below are some considerations to keep in mind when looking for a data transformation tool.
Enable engineering best practices
One of the greatest developments in recent years in the analytics space has been the emphasis on bringing software engineering best practices to analytics work. But what does that really mean?
This means that data transformation tools should conform to the practices that allow software engineers to ship faster and more reliable code—practices such as version control, automatic testing, robust documentation, and collaborative working spaces.
Version Control
You should consider whether or not a data transformation tool offers version control, and supports the basic Git flow, so that you can keep track of transformation code changes over time.
A data transformation tool should support the following seven steps of a basic Git flow:
- Clone the original codebase
- Create your development branch
- Stage your updates to files
- Commit your staged changes to the local repository
- Push your changes to the remote repo + open a pull request
- Merge your changes with the master codebase.
- Pull down a new clone of the main repo
Transformations-as-code
Your data transformation tool should also support transformations-as-code, allowing anyone who knows SQL can partake in the data transformation process.
Build vs buy
Like all internal tooling, there will come a time and place when your team needs to determine whether to build or buy the software and tooling your team needs to succeed. When considering building your own tool, it’s vital to look at your budget and available resources:
- Is it cheaper to pay for an externally managed tool or hire data engineers to do so in-house?
- Do you have enough engineers to dedicate the time to building this tool?
- What do the maintenance costs and times look like for a home-grown tool?
- How easily can you hire for skills required to build and maintain your tool?
- What is the lift required by non-technical users to contribute to your analytics pipelines and work?
Factors such as company size, technical ability, and available resources and staffing will all impact this decision, but if you do come to the conclusion that an external tool will be appropriate for your team, it’s important to break down the difference in open source and SaaS offerings.
Open source vs SaaS
If you decide to use an externally created data transformation tool, you’ll need to decide whether you want to use an open source tool or SaaS offering. For highly technical teams, open source can be budget-friendly, yet will require more maintenance and skilled technical team members. SaaS tools have dedicated infrastructures, resources, and support members to help you set up the tool, integrate it into your already-existing stack, and scale your analytics efficiently. Whether you choose open source or SaaS will again depend on your specific budget and resources available to you:
- Do you have the time to integrate and maintain an open source offering?
- What does your budget look like to work with a SaaS provider?
- Do you want to depend on someone else to debug errors in your system?
- What is the technical savviness of your team and end business users?
dbt offers two primary options for data transformation: dbt Core, an open source Python library to help you develop your transformations-as-code using SQL and the command line. dbt Cloud, the SaaS offering of dbt Core, includes an integrated development environment (IDE), orchestrator, hosted documentation site, CI/CD capabilities, and more for your transformations defined in dbt. Learn more about the three flexible dbt Cloud pricing options here.
Data documentation in data catalogs
Analytics engineers are data librarians, and documentation is our Dewey decimal system to catalog information. Someone may not know precisely where to begin on a project, so they’ll ask the analytics engineer, aka the librarian, to point them in the right direction. And at other times, they’ll know exactly what they’re looking for and delve directly into the Dewey decimal card catalog (aka the documentation) themselves.
Either way, both the analytics engineer and the documentation are here to help. Relying 100% on an analytics engineer is inefficient, yet relying entirely on documentation lacks comprehensiveness. Having both empowers people to find the information they need in the most direct, efficient way possible.
The argument for documentation revolves around four crucial points we hold dear:
- People only use code they trust: Testing and documentation provide the coverage the code needs to gain others’ trust. Those who can understand your code and view the tests performed will use it. Code that has no documentation will never be used, resulting in wasted time and wasted code.
- Reliable documentation is key to scaling a data team: Unrecorded experiential knowledge and outdated documentation are a recipe for an ineffective team, where individuals ask the same questions repeatedly and waste each other’s time. Documented data takes the knowledge out of people’s heads and arranges it so everyone has access. No matter if you’re working in a small team or as part of a team of 40, you’ll all be on the same page.
- Automation is key: One of the reasons data documentation is so often unsuccessful is because it relies on someone manually entering explanations and notes — possibly one of the most boring things in the world to do. dbt automates most documentation by making inferences about your codebase, thus taking away the uncomfortable task of manually maintaining a Google sheet or Confluence article. There is still a need for some manual input, especially, for example, when you just can’t convey everything one needs to know about a particular column in the column title itself. If you’ve ever looked in Snowflake explorer and not understood what a column means, you know why manual documentation is still necessary on some level.
- The documentation process shouldn’t be a game of catch-up: Imagine an inchworm making its way along a leaf — just as its back-end catches up, its front end moves forward a little more, so both parts of the body are moving, but the tail is always one step behind. Documentation should always step in tandem with the work; it must be a part of the same workflow as the transformations it seeks to describe. It can’t if the two are separate; the documentation will always lag behind.
Technical ramp period
Last but definitely not least, you must weigh the technical learning and adoption curves that come with choosing a data transformation tool. You need to ask yourself if those on your data team have the technical expertise to use whatever tool you choose to implement. Can they code in the language the tool uses? If not, how long will it take them to learn? If it’s an open source tool you decide on you may need to consider whether or not your data team is familiar with hosting that tool on their own infrastructure.
It’s also important to note the lift required by your end business users: will they have difficulty understanding how your data pipelines work? Is transformation documentation accessible, understandable, and easily explorable by business users? For folks who likely only know baseline SQL, what is the barrier to contributing? After all, the countless hours of time and energy spent by data practitioners are to help empower their business users to make the most informed decisions they can using the data and infrastructure they maintain.
Conclusion
Data transformation is a fundamental part of the ETL/ELT process within the modern data stack. It allows you to take your raw source data and find meaning in it for your end business users; this transformation often takes the form of modular data modeling techniques that encourage standardization, governance, and testing. When you utilize modern data transformation tools and practices, you produce higher-quality data and reusable datasets that will help propel your team and business forward. While there are very real challenges, the benefits of following modern data transformation practices far outweigh the hurdles you will jump.
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.



