A Good Problem to Have…

last updated on Sep 11, 2024
… just not a good one to keep! In this two part series you’ll learn how we rearchitected our scheduler to meet greater demand in dbt Cloud.
For those looking for more technical detail, check out the second post, in which an engineer on this team breaks down the architecture we started with, the technical decisions we've made along the way, and what we're looking to tackle next.
Part I: Why we decided to rebuild our scheduler and how we moved our key metrics
If you’re part of our community, you know that interest in dbt has grown dramatically in the past few years. Heck, we didn’t even have a cloud product until the beginning of 2019, so to have 4k+ accounts actively using our scheduler in just over 3 years is incredibly humbling.
About 9 months ago, the customer demand started to crush our cloud scheduling performance. In a prior life, when I was a venture investor, if a portfolio company shared that they were having performance issues because usage was so high, I would have replied something encouraging and trite like, “well, it’s a good problem to have!” But when you’re in the arena, it’s the complete opposite. Our scheduler performance was causing problems for our users, and that weighed on this team deeply. In some cases, our customers were pulling us in ways that we hadn’t initially intended – our scheduler was powering production software. The stakes were high, and we had to continually earn the right to service these critical workloads.
Put simply – We needed to be on time, so our customers’ data could be on time.
Outgrowing our initial scheduler offering
In many ways, dbt Labs is very much a startup. We empower teams to innovate and iterate quickly, and we practice having “strong beliefs loosely held”. But we’ve also come a long way, and some of the largest enterprises in the world depend on the software that we build. This is incredibly motivating. And performance, reliability, and scalability are top of mind for us. Our scheduler improvements will hopefully be one of many services that you’ll hear us rebuilding from the ground up to better meet our standards.
I’m probably not supposed to admit this, but the first scheduler we wrote was essentially a couple of for-loops and a call to kubernetes (k8s) to spin up an environment to run our users’ dbt projects inside their cloud data warehouse. The design was simple, and it worked incredibly well for a while.
Actually, it’s remarkable how long our first solution lasted. Software has a shelf-life, and every 2 years, we have to redesign it to meet new scaling cliffs. We could have built an over-engineered distributed system from day 1, but we didn’t need to. We didn’t have any users on day 1! And building the original scheduler as we did, allowed us to deliver dozens of other features in the meantime.
Our scheduler became the most popular discrete product in dbt Cloud with over 75% of users engaging with the product monthly. But because of the way it was initially built, it exhibited reverse network effects – the more accounts that used the scheduler, the worse the experience was for everyone. Pain was acutely felt at the top of the hour when more accounts competed for shared resources, creating a rush hour for jobs.
Every month, we’d see the average prep times for customers rise on our team’s dashboard. The trend was pretty clear, ominous even. Complaints started trickling in, and they’d be far louder soon. We even had one well-intentioned community member offer to help us scale our clusters if we couldn’t get our act together. Yes, we did try to optimize some queries to shave off a few seconds here and there, but when you have a centralized service that processes customers’ runs serially, little fixes weren’t going to cut it. In August of last year, we had had enough trying to optimize a system that needed an overhaul.
How we solved the problem – the abbreviated version
We needed a solution that could arbitrarily scale, meaning if performance started to slow again, we could turn up the dials of the system to handle the increased load. I’ll save the details on how we designed the solution for Part II of this post, but we decided on a distributed scheduler that introduced Go workers to queue up runs, a proxy to pool requests to our database, and additional EKS clusters to absorb all the k8s API calls. Our goal was to make each account feel as if they had their own dedicated scheduler, so that they’d never be stuck waiting in traffic again.
8x-ing performance
Today, we’re in a much better spot, but that doesn’t mean this work is done. The delays flattened out significantly at the top of the hour. We saw a 8-12x speed up at the peaks post-roll out of our work, and even the delays between the top of the hour improved significantly.
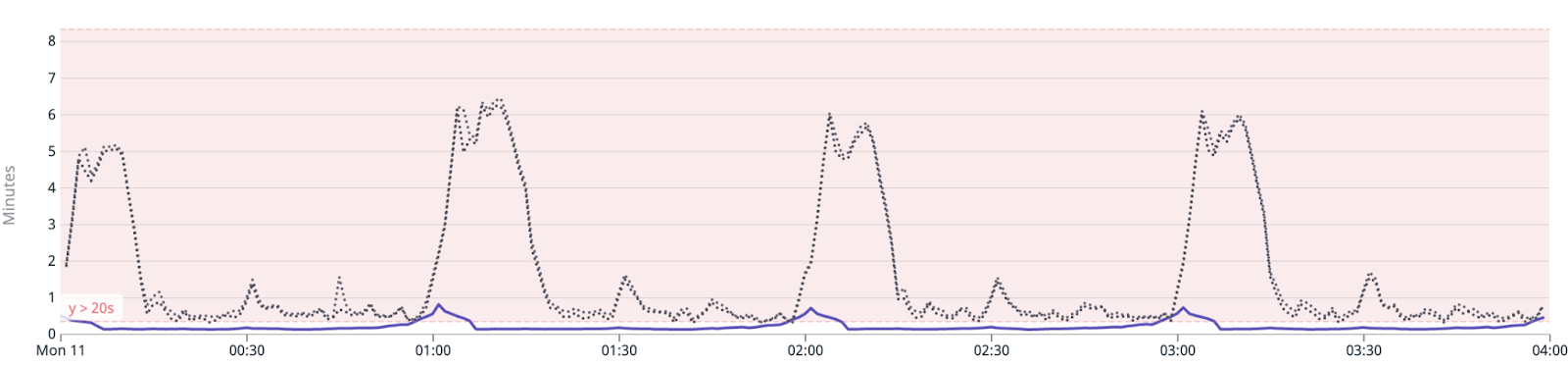
The graph shows customer prep time today (purple) vs. 1 month ago (gray).
Our team defined a run as “on time” if its prep time was less than or equal to 60 seconds, and we defined the run as “delayed” if its prep time was greater than 60 seconds. We went from only 21% of runs being “on time” at the beginning of the year to 96% currently. Even better, 82% of runs now kick off in fewer than 25 seconds.
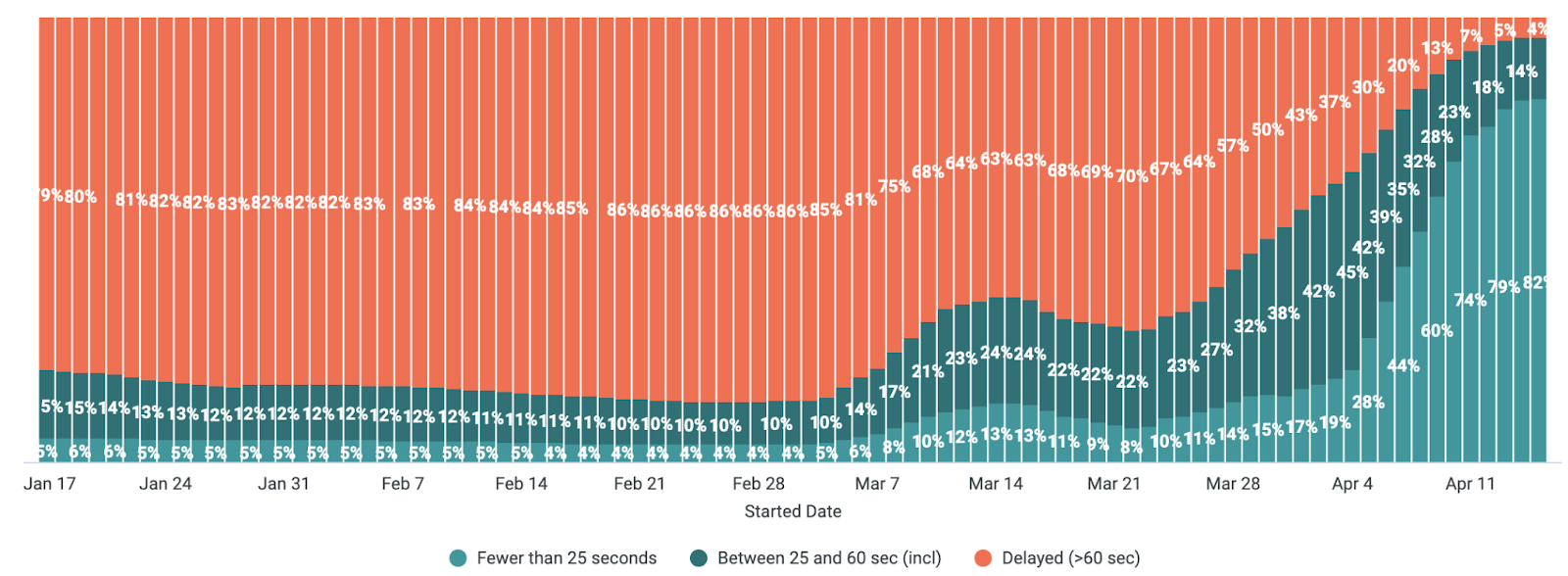
We review these metrics daily and watch the impact of our work.
Tell us what you think
While we acknowledge we are not yet where we want to be, these improvements are material and should hold us for our next phase of growth. Have feedback or thoughts? Reach out to me on the dbt Slack @Julia Schottenstein. I’m always game to hear how we can serve our users better.
In part two of this series, we’ll open source 😉 some of our engineering architectural design, so that those who are interested in building systems like ours, or are curious to go deeper, can learn more about the nuts and bolts of how we changed our application and infrastructure to better support our needs.
VS Code Extension
The free dbt VS Code extension is the best way to develop locally in dbt.




