How we configure Snowflake

Last edited on Oct 15, 2024
Since this post was published, Fishtown Analytics has become dbt Labs, and our CEO Tristan has also since written a note about our stance on providing consulting services.
Snowflake is an incredibly powerful data warehouse. The biggest reason: its emphasis on scalability. By separating computation and storage, Snowflake enables smooth transitions from very small datasets to very large ones.
A better-kept secret is Snowflake's excellent security model, which requires some appreciation for its unique architecture. Databases, warehouses, users, and roles turn out to be useful abstractions for designing the ideal data warehouse environment.
Since our earlier consulting days as Fishtown Analytics, we've set up Snowflake accounts for quite a few clients and have an approach that we rather like. This will probably be most useful to you if you use dbt, but even if you're not a dbt user there is a lot of good stuff to steal.
First, some definitions.
- User: A single credentialed user, with a login and password, who can connect to Snowflake.
- Role: A group of users who have the same permissions to access account resources. All permissions in Snowflake are assigned at the role level. A single user can be associated with multiple roles; they specify one role when making a connection, and can switch between them in the online console.
- Database: The highest level of abstraction for file storage. Each Snowflake account can have multiple databases. Each database can have multiple schemas, each of which can have multiple tables / views / other objects. The data is stored in S3, meaning that the storage of each database is effectively unlimited.
- Warehouse: A "warehouse" is Snowflake's unit of computing power. If you're familiar with cloud infrastructure, these are like EC2 instances --- they perform the actual data processing. Snowflake charges you based on the size of the warehouse and how long you have it running, by the minute. Critically, any warehouse can process data from any database.
Setting up Snowflake is an exercise of arranging these pieces in concert. Someone new to Snowflake may create one database, one warehouse, one super-powered role, and just a couple of users. That may fly in Redshift, **but there's a much better way.**Let's take it from the top.
Our Recommended Setup
One Connection
Account: your-host.your-region
Web UI: https://your-host.your-region.snowflakecomputing.com/console
Unlike in Redshift, you can use the same connection to access separate logical databases and compute warehouses, all accessed via a single login.
Also unlike Redshift, Snowflake allows traffic from all IP addresses by default. We highly recommend disabling this feature and explicitly whitelisting IP addresses by managing Network Policies in the online console.
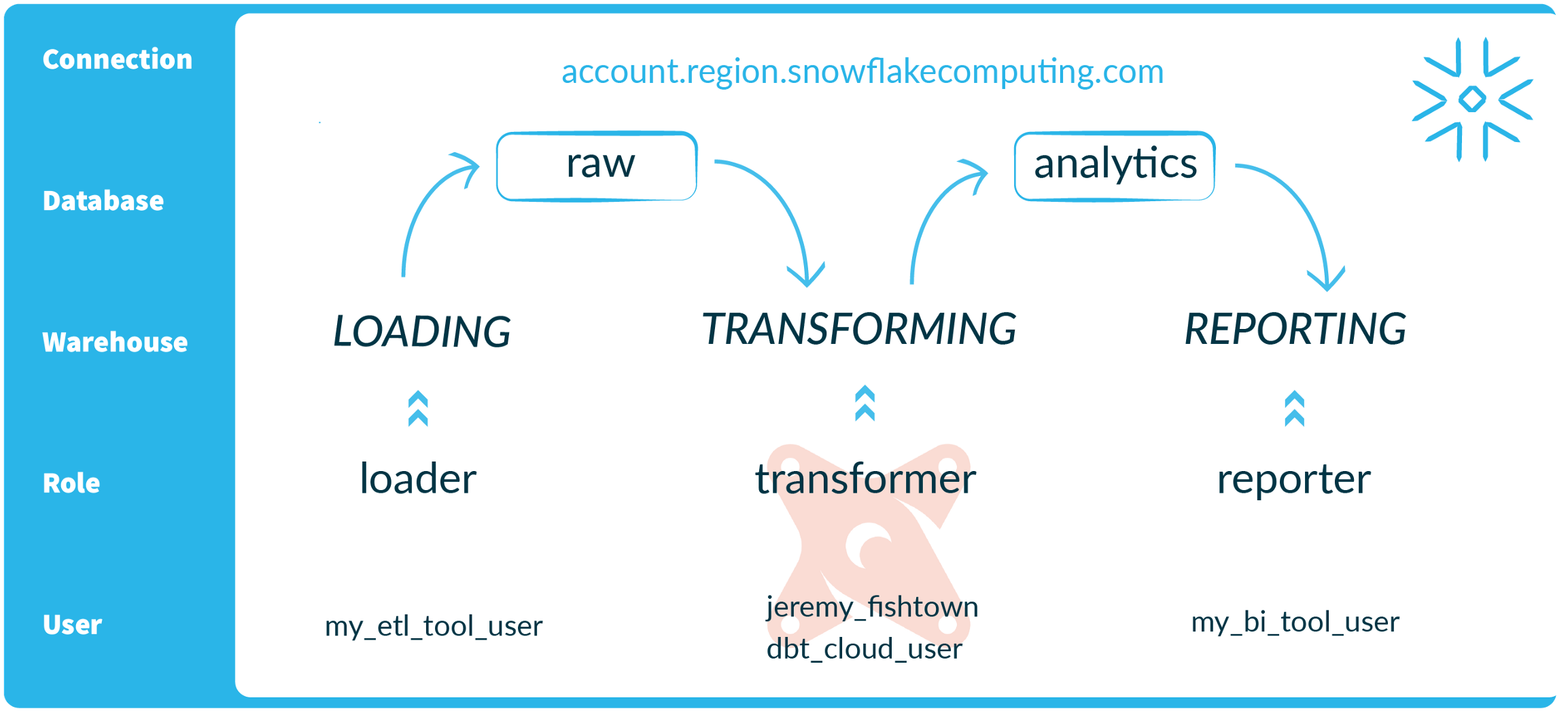
Two Databases
rawUnsurprisingly, this database contains your raw data. This is the landing pad for everything extracted and loaded, as well as containing external stages for data living in S3. Access to this database is strictly permissioned.analytics** This database contains tables and views accessible to analysts and reporting. Everything inanalyticsis created and owned by dbt.
End-users, including BI and reporting tools, should never have access to raw data. When specific datasets need to be exposed for analysis, we always model them first in dbt. This staging layer acts as a critical abstraction layer: it can be used to cleanse, denormalize, model, and enforce security practices on top of raw data.
ELT-based data transformation tools (including but not limited to dbt) can query from tables in raw and create tables in analytics using the same Snowflake connection. End-users who want to investigate or audit underlying data should always be accessing staging views, with proper casting, renaming, and PII-hashing baked in. If this sounds useful or familiar, it's also a best practice in the dbt workflow.
Once within analytics , Snowflake permissions are granular enough to control view and query access to specific tables, and any views built on top of them. In an ideal setup, we organize materialized views and tables into schemas based on their intended users, and we can set specific user permissions by running future grants on those schemas within dbt hooks.
Three Warehouses
loadingTools like Fivetran and Stitch will use this warehouse to perform their regular loads of new data. We separate this workload from the other workloads because, at scale, loading can put significant strain on your warehouse and we don't want to cause slowness for your BI users.transformingThis is the warehouse that dbt will use to perform all data transformations. It will only be in use (and charging you credits) when regular jobs are being run.reportingMode and any other BI tools will connect to this warehouse to run analytical queries and report the results to end users. This warehouse will be spun up only when a user is actively running a query against it.
Snowflake warehouses spin up very fast, run queries multi-threaded, and put serious computational resources at your disposal. They also account for Snowflake's cost, per minute of activity. This setup can cost as little as $500 / month with average usage.
A Snowflake warehouse is resumed and suspended either manually, by executing explicit suspend and resume commands, or automatically, spinning up to run a query and shutting off some configurable number of minutes later. transforming and reporting can be auto-resumed and auto-suspended as usage dictates. By harnessing finely tuned role permissions to set up Snowflake accounts, with dbt Cloud scheduling the availability of compute resources for ETL loads, you have quite a lot of tools in your box to control costs.
Four Roles
publicThe default set of user permissions. Every user starts withpublicand adds roles as their position requires.loaderOwns the tables in yourrawdatabase, and connects to theloadingwarehouse.transformerHas query permissions on tables inrawdatabase and owns tables in theanalyticsdatabase. This is for dbt developers and scheduled jobs.reporterHas permissions on theanalyticsdatabase only. This role is for data consumers, such as analysts and BI tools. These users will not have permissions to read data from therawdatabase.
This list does not include the default administrative roles: sysadmin, accountadmin, and securityadmin . You should only tap these superuser roles when needing to set up resources, configure permissions, and check billing information. Very few users should have access to these roles.
Five Types of Users
Every member of the team, human or API, should have their own username and password. Even in a team of one, that means at least five separate users:
- Primary account login This is your CTO, DBA, or Lucky Soul Who Was Tasked With Setting Up Snowflake--- with all the admin roles comes great responsibility. Use only to set up or administer databases, warehouses, roles, and users. Never use this login to perform any real analysis!
- Your data loader(s) Stitch, Fivetran, Alooma. These users should be assigned to the
loaderrole. - Your transformation scheduler(s) Airflow, Luigi, dbt Cloud. These users should be assigned to the
transformerrole. - Your BI tool(s) Mode, Looker, Periscope. These users should be assigned to the
reporterrole. - Analysts All analysts writing queries in a SQL client, notebook, via dbt, etc., should have their own logins. Users that are building dbt models should be assigned the
transformerrole so that they can accessrawtables.
The keys are to control permissions at the role level, and to create unique logins for all users. That means every ad hoc script, python job, or person running queries. One-to-one user setup requires little time upfront, and provides immense added value in security and accountability.
Recap
With by-the-minute cost structure and granular permissions, Snowflake configuration is an optimization problem in disguise. We think we've come up with a good solution:
1 Connection: account.region.snowflakecomputing.com **
2 Databases: raw, analytics **
3 Warehouses: loading, transforming, reporting **
4 Roles: public, loader,* transformer, reporter **
5 Users: admin, etl_user, dbt_cloud_user, bi_user, analyst **
Want to see all of this in a single graphic? I thought so.
All of the setup mentioned in this article---every create, alter , and grant statement---takes the lesser part of an hour. From then on, you're free to fret over much more complicated matters: transient tables, clustering keys, zero-copy clones. Want to chat about that stuff? You'll have to join us in Slack.
Changelog:
- August 2021: Both dbt Labs and the data platform ecosystem that dbt operates in have evolved meaningfully since this post was written. We've made edits to reflect how our work at dbt Labs has evolved and how functional comparisons between warehouse vendors have changed.
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.




