

For Ryan Goltz, Principal Data Architect at a Fortune 500 oil & gas company, the demise of the enterprise data warehouse (EDW) began between 2012 to 2017. During that time, two technology trends were developing in parallel–big data platforms and broad adoption for version control and continuous integration. “CI/CD stems from open-source development as a means to ensure governance in a distributed development environment. This change complimented the technical capabilities and performance of the big data platforms,” Ryan said. “The idea was to use these technologies to empower information consumers to become information producers.”
Ryan was convinced that the value of big data platforms wasn’t the size of the data: “Most of these people weren’t writing Spark. They were writing Impala views. This wasn’t big data, it was just big queries.” Instead, he saw the value of big data platforms as being in the new workflows. If you could apply software engineering best practices like code control and reusability to the data warehouse in a simple language like SQL, you could empower a whole new set of users to build and deploy their own data sets.
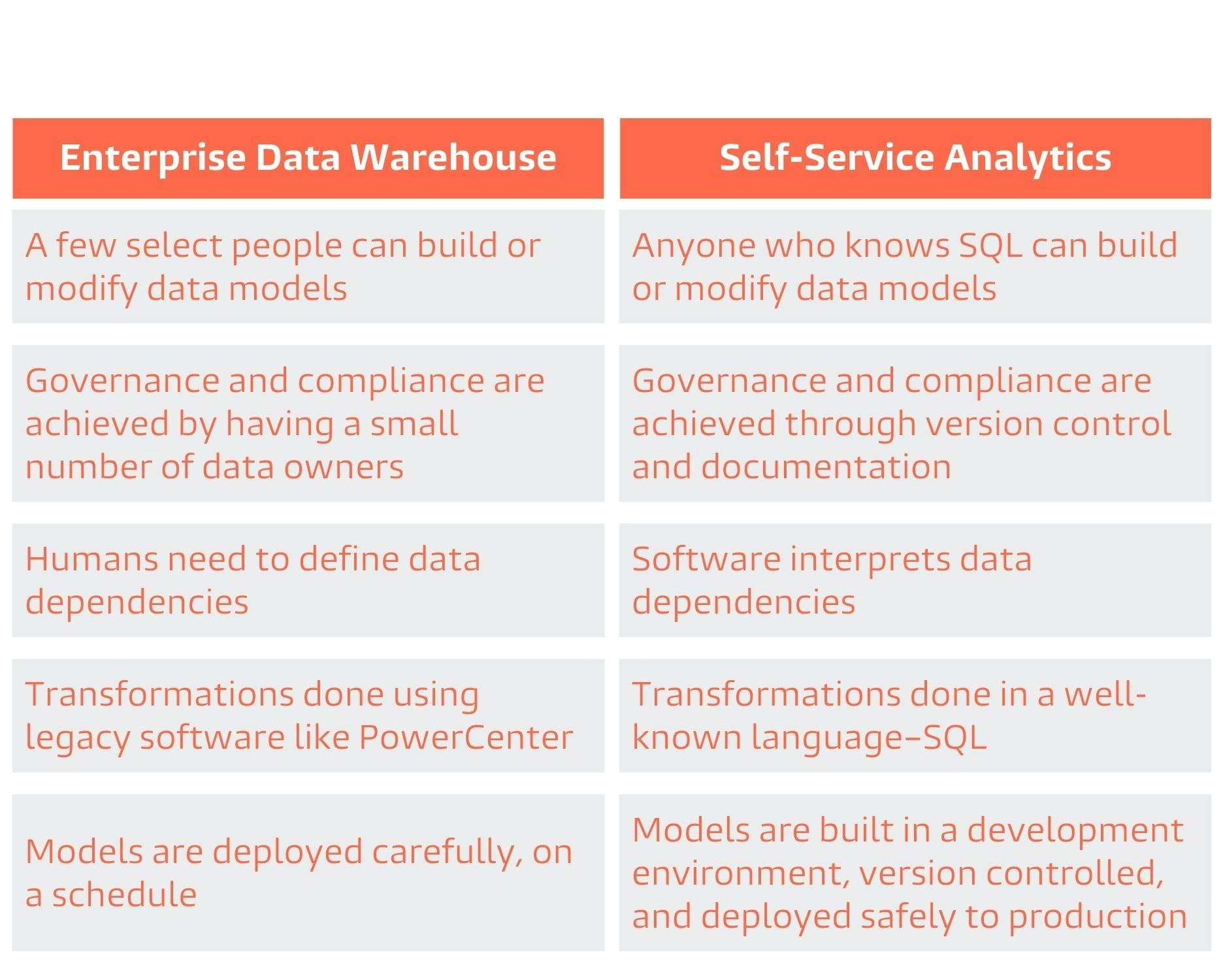
Why the enterprise data warehouse couldn’t support self-service
Like many in the Fortune 500, the company has a long history with the centrally-managed EDW. Over 10 years ago the team started to build a system for consolidating, cleaning, and organizing information from more than 70 operational systems into a single repository. “It served its purpose,” Ryan said. However, the EDW would never allow for self-service. It came from a time that assumed the fewer people touching your data sets, the better.
“We understood that for the company to get value from our information we need to change how we work with that information,” Ryan said. He saw two barriers blocking people from ever contributing to the enterprise data warehouse:
1.The tools to manage the EDW were inaccessible. At the oil and gas company, an organization of nearly 2300 employees, there were 15 people on the team with the knowledge needed to modify or update the EDW. “Provisioning information models in an Oracle data warehouse requires a lot of up-front knowledge about the data and how that data will be accessed,” Ryan said. “Moreover, to implement that model, we relied on legacy tools like Informatica PowerCenter to perform incremental loads. There was a lot of complexity involved in building performance into the system just to accomplish our data loads and as the calculations became more complex so did the data loads.”
2. Managing model dependencies required deep knowledge of the EDW. “We have hundreds of models in our EDW,” Ryan said. “Managing these dependencies adds an additional layer of complexity. There is too much risk in asking a business user to understand these dependencies.”
Ryan had a new vision for how data teams should work. The question he found himself asking was, “How do we provide a mechanism that allows more people to contribute to the value chain of the data warehouse?”
The approach he imagined would have four things: “First, you need to co-locate the data so that users can assemble models that span operational systems. Second, you need a really fast database with certain characteristics that make the system easy to use. Third, you need some tooling which allows models to be built in a language that the users understand. Finally, you need integration with workflow-based release processes.” This setup would unlock self-service for the company.
How dbt + Snowflake enabled self-service
For Ryan, the choice to go with Snowflake was an easy one. The team evaluated other warehouses, but he was sold on the ease of use: “Snowflake makes performance easy for us. We rarely think about performance and when we do the solution is incredibly simple.” For an organization trying to get non-IT people to work with the data warehouse, this ease of use was a must-have.
He was still looking for a way to solve transformation when a colleague sent him the dbt viewpoint. “We had spent the last 10 years building systems which templatized the EDW development process and we firmly believe in the advantages of standardization,” Ryan said. dbt provided a standardized process, but packaged in a new workflow that was accessible to non-IT people. “I remember reading the dbt viewpoint and thinking this is fantastic–a simple way to focus on SQL as a way to manage data objects and at the same time solve our scheduling and dependency problems. dbt was an off-the-shelf solution that took our ideas to the next level. It was revelatory. We took this idea to the EDW team warehouse team that had been doing PowerCenter work and we were like, guys, this is it. The spaceship had landed.”
Together, Snowflake and dbt hit Ryan’s four most important requirements:
- Co-located data that spanned operational systems
- Data warehouse that didn’t require sophisticated tuning or complex maintenance.
- Transformation process that required limited proprietary knowledge and where business logic could be expressed in SQL.
- Workflow that allowed non-IT practitioners to apply best practices from the software development lifecycle to the data warehouse.
The final piece of the puzzle was figuring out how to put an architecture in place that would preserve trust in the data. The primary reason that everyone at the company used the EDW was simple–they trusted it. The EDW was carefully governed by a central team. It had a set of common definitions and data quality was high. If Ryan was going to make self-service a reality, the team would need an architecture that retained the high quality of the EDW even as more people were building and deploying data models. “Cool tools are just cool tools,” Ryan said. “But they wouldn’t do anything for us if we didn’t have the right architecture in place.”
The company needed a logical architecture that would allow for “innovation at the business domain level without propagating risk to everyone else.” Key data that every business domain needed would be managed at the enterprise level and owned by the enterprise team. Domain level knowledge would be managed by that domain. “Snowflake allowed us to add segmentation in the logical architecture. This helps us manage the company’s risk while providing a clear path to expand usage as needed,” Ryan said. “If someone needs data from another business domain, the enterprise team can apply the necessary data governance to move the appropriate dbt models to the enterprise level.”
This architecture follows an important principle of software engineering–domain-driven design. This is the concept that code should match the business domain it supports. Ryan was able to implement domain-driven design using Snowflake and dbt by giving each business domain its own dbt project, Snowflake database, and a separate warehouse for processing. These domains are built around the business process—planning, operations, production—as well as corporate functions like finance. Within a given domain, business users fully own their dbt project. Users can also “reach into” the enterprise domain to reuse or extend enterprise business objects.
The business impact of increased self-service
Ryan is candid about the work that still needs to be done. Introducing the ability to self-serve your own data models comes with some challenges–there’s still an education gap on how to do this work really well, and he imagines implementing education sessions and quarterly business reviews for department groups to meet and review their dbt projects. But the self-service model has already proven to be incredibly valuable to company. Ryan points to a few key results:
Reallocated $10 million back into the business: Energy companies have high operational costs. With more agile analytics, business users can better analyze these operational costs and forecasts. Mike Green, Manager of the company's Accounting Center of Excellence, says, "It can be challenging to articulate the value of empowering the business with an operating model and technology to analyze and innovate against data at scale. The capital accrual process is a great example using significant data volumes from multiple systems. With data collocated in a platform and an operating model that allows the business to analyze it, we've freed up millions of dollars that were tied up in the capital accrual process."
Eliminated three weeks of work on regulatory reporting: The company routinely participates in audits for each state where the company operates. The states typically bring in one of the major accounting firms to assist in the audit which involves analyzing General Ledger data. “The auditors would coordinate with IT to run and extract data in batches then load the data in their databases to rebuild the dataset. This process is tedious for all involved, and normally takes several weeks at best,” Ryan said. With Snowflake and dbt, this process has become not only better and faster, but also more secure. “We make a model of the data needed for the audit, publish to a Snowflake Share and when the audit is complete, we turn off their access to the data. We are able to keep the data resident in our systems under our control and we’ve saved weeks of pain extracting data.”
2x the number of people collaborating on data modeling: The EDW was previously managed by a team of 15 people. Today? “There are currently three people building the enterprise structures inside Snowflake.” Instead, domain experts are now collaborating on data modeling. The team has nearly 30 people who contribute to this work–a massive expansion in raw data engineering capability. “With Snowflake and dbt, the people who have the business problem now have the tools to go and solve their business problem. It creates a fundamentally different relationship with IT. We’re no longer the bottleneck or order taker,” Ryan said. With self-service analytics, the entire organization is empowered to get value out of the company’s data.


